 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritic Sequential Monte Carlo
Paper and Code
May 30, 2022
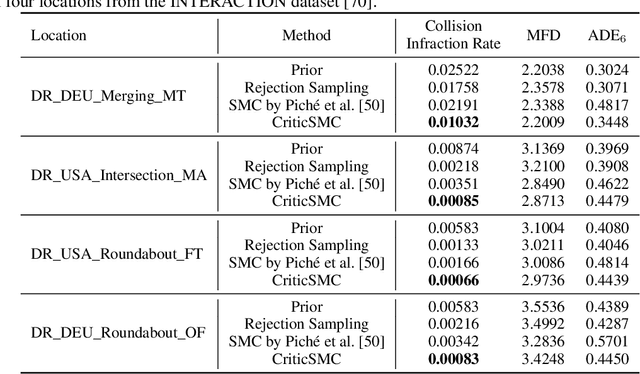
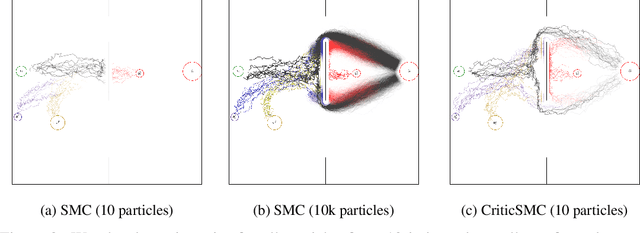
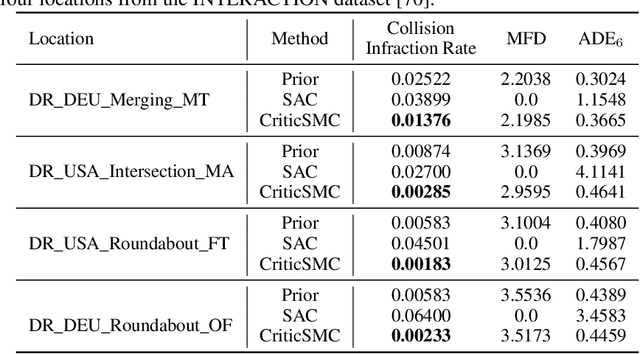
We introduce CriticSMC, a new algorithm for planning as inference built from a novel composition of sequential Monte Carlo with learned soft-Q function heuristic factors. This algorithm is structured so as to allow using large numbers of putative particles leading to efficient utilization of computational resource and effective discovery of high reward trajectories even in environments with difficult reward surfaces such as those arising from hard constraints. Relative to prior art our approach is notably still compatible with model-free reinforcement learning in the sense that the implicit policy we produce can be used at test time in the absence of a world model. Our experiments on self-driving car collision avoidance in simulation demonstrate improvements against baselines in terms of infraction minimization relative to computational effort while maintaining diversity and realism of found trajectories.