 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQP-OneModel: A Unified Generative LLM for Multi-Task Query Understanding in Xiaohongshu Search
Feb 10, 2026Query Processing (QP) bridges user intent and content supply in large-scale Social Network Service (SNS) search engines. Traditional QP systems rely on pipelines of isolated discriminative models (e.g., BERT), suffering from limited semantic understanding and high maintenance overhead. While Large Language Models (LLMs) offer a potential solution, existing approaches often optimize sub-tasks in isolation, neglecting intrinsic semantic synergy and necessitating independent iterations. Moreover, standard generative methods often lack grounding in SNS scenarios, failing to bridge the gap between open-domain corpora and informal SNS linguistic patterns, while struggling to adhere to rigorous business definitions. We present QP-OneModel, a Unified Generative LLM for Multi-Task Query Understanding in the SNS domain. We reformulate heterogeneous sub-tasks into a unified sequence generation paradigm, adopting a progressive three-stage alignment strategy culminating in multi-reward Reinforcement Learning. Furthermore, QP-OneModel generates intent descriptions as a novel high-fidelity semantic signal, effectively augmenting downstream tasks such as query rewriting and ranking. Offline evaluations show QP-OneModel achieves a 7.35% overall gain over discriminative baselines, with significant F1 boosts in NER (+9.01%) and Term Weighting (+9.31%). It also exhibits superior generalization, surpassing a 32B model by 7.60% accuracy on unseen tasks. Fully deployed at Xiaohongshu, online A/B tests confirm its industrial value, optimizing retrieval relevance (DCG) by 0.21% and lifting user retention by 0.044%.
Gradient-Guided Learning Network for Infrared Small Target Detection
Dec 10, 2025Recently, infrared small target detection has attracted extensive attention. However, due to the small size and the lack of intrinsic features of infrared small targets, the existing methods generally have the problem of inaccurate edge positioning and the target is easily submerged by the background. Therefore, we propose an innovative gradient-guided learning network (GGL-Net). Specifically, we are the first to explore the introduction of gradient magnitude images into the deep learning-based infrared small target detection method, which is conducive to emphasizing the edge details and alleviating the problem of inaccurate edge positioning of small targets. On this basis, we propose a novel dual-branch feature extraction network that utilizes the proposed gradient supplementary module (GSM) to encode raw gradient information into deeper network layers and embeds attention mechanisms reasonably to enhance feature extraction ability. In addition, we construct a two-way guidance fusion module (TGFM), which fully considers the characteristics of feature maps at different levels. It can facilitate the effective fusion of multi-scale feature maps and extract richer semantic information and detailed information through reasonable two-way guidance. Extensive experiments prove that GGL-Net has achieves state-of-the-art results on the public real NUAA-SIRST dataset and the public synthetic NUDT-SIRST dataset. Our code has been integrated into https://github.com/YuChuang1205/MSDA-Net
Towards Implicit Aggregation: Robust Image Representation for Place Recognition in the Transformer Era
Nov 08, 2025Visual place recognition (VPR) is typically regarded as a specific image retrieval task, whose core lies in representing images as global descriptors. Over the past decade, dominant VPR methods (e.g., NetVLAD) have followed a paradigm that first extracts the patch features/tokens of the input image using a backbone, and then aggregates these patch features into a global descriptor via an aggregator. This backbone-plus-aggregator paradigm has achieved overwhelming dominance in the CNN era and remains widely used in transformer-based models. In this paper, however, we argue that a dedicated aggregator is not necessary in the transformer era, that is, we can obtain robust global descriptors only with the backbone. Specifically, we introduce some learnable aggregation tokens, which are prepended to the patch tokens before a particular transformer block. All these tokens will be jointly processed and interact globally via the intrinsic self-attention mechanism, implicitly aggregating useful information within the patch tokens to the aggregation tokens. Finally, we only take these aggregation tokens from the last output tokens and concatenate them as the global representation. Although implicit aggregation can provide robust global descriptors in an extremely simple manner, where and how to insert additional tokens, as well as the initialization of tokens, remains an open issue worthy of further exploration. To this end, we also propose the optimal token insertion strategy and token initialization method derived from empirical studies. Experimental results show that our method outperforms state-of-the-art methods on several VPR datasets with higher efficiency and ranks 1st on the MSLS challenge leaderboard. The code is available at https://github.com/lu-feng/image.
Towards Seamless Borders: A Method for Mitigating Inconsistencies in Image Inpainting and Outpainting
Jun 14, 2025Image inpainting is the task of reconstructing missing or damaged parts of an image in a way that seamlessly blends with the surrounding content. With the advent of advanced generative models, especially diffusion models and generative adversarial networks, inpainting has achieved remarkable improvements in visual quality and coherence. However, achieving seamless continuity remains a significant challenge. In this work, we propose two novel methods to address discrepancy issues in diffusion-based inpainting models. First, we introduce a modified Variational Autoencoder that corrects color imbalances, ensuring that the final inpainted results are free of color mismatches. Second, we propose a two-step training strategy that improves the blending of generated and existing image content during the diffusion process. Through extensive experiments, we demonstrate that our methods effectively reduce discontinuity and produce high-quality inpainting results that are coherent and visually appealing.
SelaVPR++: Towards Seamless Adaptation of Foundation Models for Efficient Place Recognition
Feb 23, 2025Recent studies show that the visual place recognition (VPR) method using pre-trained visual foundation models can achieve promising performance. In our previous work, we propose a novel method to realize seamless adaptation of foundation models to VPR (SelaVPR). This method can produce both global and local features that focus on discriminative landmarks to recognize places for two-stage VPR by a parameter-efficient adaptation approach. Although SelaVPR has achieved competitive results, we argue that the previous adaptation is inefficient in training time and GPU memory usage, and the re-ranking paradigm is also costly in retrieval latency and storage usage. In pursuit of higher efficiency and better performance, we propose an extension of the SelaVPR, called SelaVPR++. Concretely, we first design a parameter-, time-, and memory-efficient adaptation method that uses lightweight multi-scale convolution (MultiConv) adapters to refine intermediate features from the frozen foundation backbone. This adaptation method does not back-propagate gradients through the backbone during training, and the MultiConv adapter facilitates feature interactions along the spatial axes and introduces proper local priors, thus achieving higher efficiency and better performance. Moreover, we propose an innovative re-ranking paradigm for more efficient VPR. Instead of relying on local features for re-ranking, which incurs huge overhead in latency and storage, we employ compact binary features for initial retrieval and robust floating-point (global) features for re-ranking. To obtain such binary features, we propose a similarity-constrained deep hashing method, which can be easily integrated into the VPR pipeline. Finally, we improve our training strategy and unify the training protocol of several common training datasets to merge them for better training of VPR models. Extensive experiments show that ......
Rolling Ahead Diffusion for Traffic Scene Simulation
Feb 13, 2025



Realistic driving simulation requires that NPCs not only mimic natural driving behaviors but also react to the behavior of other simulated agents. Recent developments in diffusion-based scenario generation focus on creating diverse and realistic traffic scenarios by jointly modelling the motion of all the agents in the scene. However, these traffic scenarios do not react when the motion of agents deviates from their modelled trajectories. For example, the ego-agent can be controlled by a stand along motion planner. To produce reactive scenarios with joint scenario models, the model must regenerate the scenario at each timestep based on new observations in a Model Predictive Control (MPC) fashion. Although reactive, this method is time-consuming, as one complete possible future for all NPCs is generated per simulation step. Alternatively, one can utilize an autoregressive model (AR) to predict only the immediate next-step future for all NPCs. Although faster, this method lacks the capability for advanced planning. We present a rolling diffusion based traffic scene generation model which mixes the benefits of both methods by predicting the next step future and simultaneously predicting partially noised further future steps at the same time. We show that such model is efficient compared to diffusion model based AR, achieving a beneficial compromise between reactivity and computational efficiency.
Why and How: Knowledge-Guided Learning for Cross-Spectral Image Patch Matching
Dec 15, 2024



Recently, cross-spectral image patch matching based on feature relation learning has attracted extensive attention. However, performance bottleneck problems have gradually emerged in existing methods. To address this challenge, we make the first attempt to explore a stable and efficient bridge between descriptor learning and metric learning, and construct a knowledge-guided learning network (KGL-Net), which achieves amazing performance improvements while abandoning complex network structures. Specifically, we find that there is feature extraction consistency between metric learning based on feature difference learning and descriptor learning based on Euclidean distance. This provides the foundation for bridge building. To ensure the stability and efficiency of the constructed bridge, on the one hand, we conduct an in-depth exploration of 20 combined network architectures. On the other hand, a feature-guided loss is constructed to achieve mutual guidance of features. In addition, unlike existing methods, we consider that the feature mapping ability of the metric branch should receive more attention. Therefore, a hard negative sample mining for metric learning (HNSM-M) strategy is constructed. To the best of our knowledge, this is the first time that hard negative sample mining for metric networks has been implemented and brings significant performance gains. Extensive experimental results show that our KGL-Net achieves SOTA performance in three different cross-spectral image patch matching scenarios. Our code are available at https://github.com/YuChuang1205/KGL-Net.
From Easy to Hard: Progressive Active Learning Framework for Infrared Small Target Detection with Single Point Supervision
Dec 15, 2024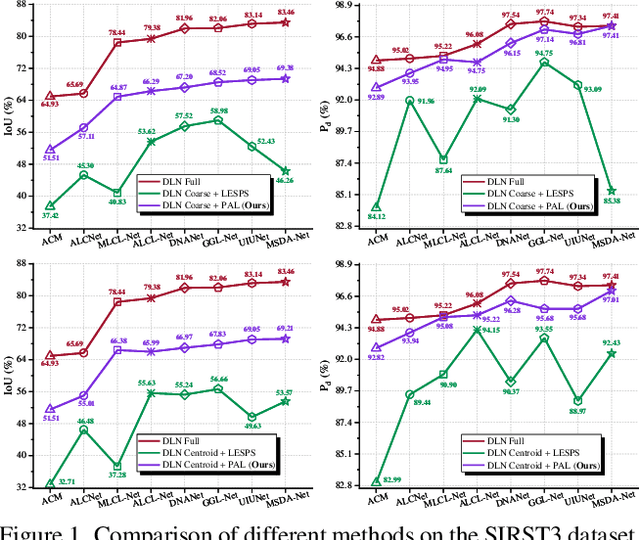
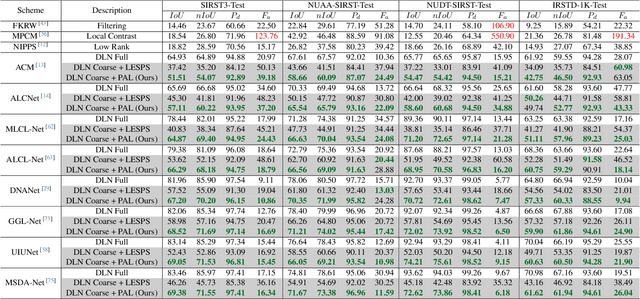
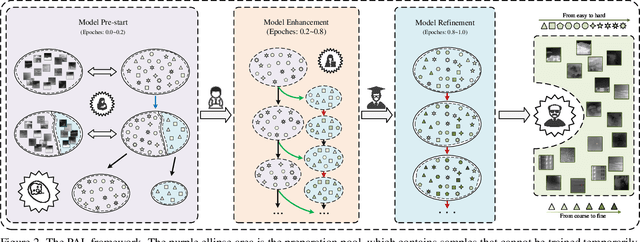

Recently, single-frame infrared small target (SIRST) detection with single point supervision has drawn wide-spread attention. However, the latest label evolution with single point supervision (LESPS) framework suffers from instability, excessive label evolution, and difficulty in exerting embedded network performance. Therefore, we construct a Progressive Active Learning (PAL) framework. Specifically, inspired by organisms gradually adapting to their environment and continuously accumulating knowledge, we propose an innovative progressive active learning idea, which emphasizes that the network progressively and actively recognizes and learns more hard samples to achieve continuous performance enhancement. Based on this, on the one hand, we propose a model pre-start concept, which focuses on selecting a portion of easy samples and can help models have basic task-specific learning capabilities. On the other hand, we propose a refined dual-update strategy, which can promote reasonable learning of harder samples and continuous refinement of pseudo-labels. In addition, to alleviate the risk of excessive label evolution, a decay factor is reasonably introduced, which helps to achieve a dynamic balance between the expansion and contraction of target annotations. Extensive experiments show that convolutional neural networks (CNNs) equipped with our PAL framework have achieved state-of-the-art (SOTA) results on multiple public datasets. Furthermore, our PAL framework can build a efficient and stable bridge between full supervision and point supervision tasks. Our code are available at https://github.com/YuChuang1205/PAL.
See Further When Clear: Curriculum Consistency Model
Dec 09, 2024



Significant advances have been made in the sampling efficiency of diffusion models and flow matching models, driven by Consistency Distillation (CD), which trains a student model to mimic the output of a teacher model at a later timestep. However, we found that the learning complexity of the student model varies significantly across different timesteps, leading to suboptimal performance in CD.To address this issue, we propose the Curriculum Consistency Model (CCM), which stabilizes and balances the learning complexity across timesteps. Specifically, we regard the distillation process at each timestep as a curriculum and introduce a metric based on Peak Signal-to-Noise Ratio (PSNR) to quantify the learning complexity of this curriculum, then ensure that the curriculum maintains consistent learning complexity across different timesteps by having the teacher model iterate more steps when the noise intensity is low. Our method achieves competitive single-step sampling Fr\'echet Inception Distance (FID) scores of 1.64 on CIFAR-10 and 2.18 on ImageNet 64x64.Moreover, we have extended our method to large-scale text-to-image models and confirmed that it generalizes well to both diffusion models (Stable Diffusion XL) and flow matching models (Stable Diffusion 3). The generated samples demonstrate improved image-text alignment and semantic structure, since CCM enlarges the distillation step at large timesteps and reduces the accumulated error.
EDTformer: An Efficient Decoder Transformer for Visual Place Recognition
Dec 01, 2024



Visual place recognition (VPR) aims to determine the general geographical location of a query image by retrieving visually similar images from a large geo-tagged database. To obtain a global representation for each place image, most approaches typically focus on the aggregation of deep features extracted from a backbone through using current prominent architectures (e.g., CNNs, MLPs, pooling layer and transformer encoder), giving little attention to the transformer decoder. However, we argue that its strong capability in capturing contextual dependencies and generating accurate features holds considerable potential for the VPR task. To this end, we propose an Efficient Decoder Transformer (EDTformer) for feature aggregation, which consists of several stacked simplified decoder blocks followed by two linear layers to directly generate robust and discriminative global representations for VPR. Specifically, we do this by formulating deep features as the keys and values, as well as a set of independent learnable parameters as the queries. EDTformer can fully utilize the contextual information within deep features, then gradually decode and aggregate the effective features into the learnable queries to form the final global representations. Moreover, to provide powerful deep features for EDTformer and further facilitate the robustness, we use the foundation model DINOv2 as the backbone and propose a Low-Rank Parallel Adaptation (LoPA) method to enhance it, which can refine the intermediate features of the backbone progressively in a memory- and parameter-efficient way. As a result, our method not only outperforms single-stage VPR methods on multiple benchmark datasets, but also outperforms two-stage VPR methods which add a re-ranking with considerable cost. Code will be available at https://github.com/Tong-Jin01/EDTformer.