 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-Guided Learning Network for Infrared Small Target Detection
Dec 10, 2025Recently, infrared small target detection has attracted extensive attention. However, due to the small size and the lack of intrinsic features of infrared small targets, the existing methods generally have the problem of inaccurate edge positioning and the target is easily submerged by the background. Therefore, we propose an innovative gradient-guided learning network (GGL-Net). Specifically, we are the first to explore the introduction of gradient magnitude images into the deep learning-based infrared small target detection method, which is conducive to emphasizing the edge details and alleviating the problem of inaccurate edge positioning of small targets. On this basis, we propose a novel dual-branch feature extraction network that utilizes the proposed gradient supplementary module (GSM) to encode raw gradient information into deeper network layers and embeds attention mechanisms reasonably to enhance feature extraction ability. In addition, we construct a two-way guidance fusion module (TGFM), which fully considers the characteristics of feature maps at different levels. It can facilitate the effective fusion of multi-scale feature maps and extract richer semantic information and detailed information through reasonable two-way guidance. Extensive experiments prove that GGL-Net has achieves state-of-the-art results on the public real NUAA-SIRST dataset and the public synthetic NUDT-SIRST dataset. Our code has been integrated into https://github.com/YuChuang1205/MSDA-Net
Why and How: Knowledge-Guided Learning for Cross-Spectral Image Patch Matching
Dec 15, 2024



Recently, cross-spectral image patch matching based on feature relation learning has attracted extensive attention. However, performance bottleneck problems have gradually emerged in existing methods. To address this challenge, we make the first attempt to explore a stable and efficient bridge between descriptor learning and metric learning, and construct a knowledge-guided learning network (KGL-Net), which achieves amazing performance improvements while abandoning complex network structures. Specifically, we find that there is feature extraction consistency between metric learning based on feature difference learning and descriptor learning based on Euclidean distance. This provides the foundation for bridge building. To ensure the stability and efficiency of the constructed bridge, on the one hand, we conduct an in-depth exploration of 20 combined network architectures. On the other hand, a feature-guided loss is constructed to achieve mutual guidance of features. In addition, unlike existing methods, we consider that the feature mapping ability of the metric branch should receive more attention. Therefore, a hard negative sample mining for metric learning (HNSM-M) strategy is constructed. To the best of our knowledge, this is the first time that hard negative sample mining for metric networks has been implemented and brings significant performance gains. Extensive experimental results show that our KGL-Net achieves SOTA performance in three different cross-spectral image patch matching scenarios. Our code are available at https://github.com/YuChuang1205/KGL-Net.
From Easy to Hard: Progressive Active Learning Framework for Infrared Small Target Detection with Single Point Supervision
Dec 15, 2024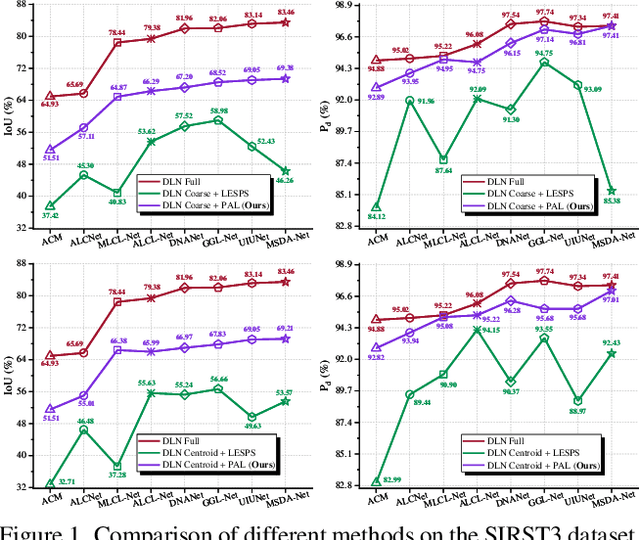
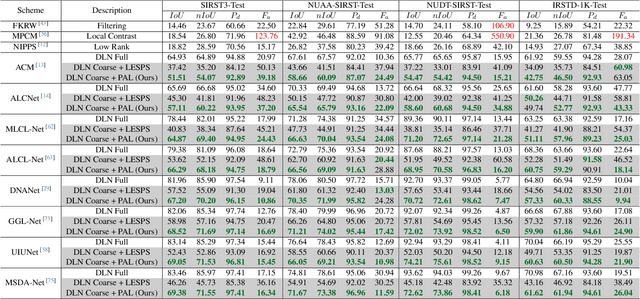
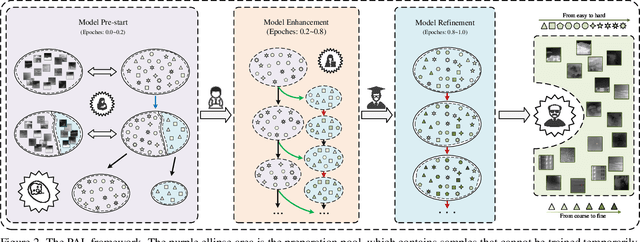

Recently, single-frame infrared small target (SIRST) detection with single point supervision has drawn wide-spread attention. However, the latest label evolution with single point supervision (LESPS) framework suffers from instability, excessive label evolution, and difficulty in exerting embedded network performance. Therefore, we construct a Progressive Active Learning (PAL) framework. Specifically, inspired by organisms gradually adapting to their environment and continuously accumulating knowledge, we propose an innovative progressive active learning idea, which emphasizes that the network progressively and actively recognizes and learns more hard samples to achieve continuous performance enhancement. Based on this, on the one hand, we propose a model pre-start concept, which focuses on selecting a portion of easy samples and can help models have basic task-specific learning capabilities. On the other hand, we propose a refined dual-update strategy, which can promote reasonable learning of harder samples and continuous refinement of pseudo-labels. In addition, to alleviate the risk of excessive label evolution, a decay factor is reasonably introduced, which helps to achieve a dynamic balance between the expansion and contraction of target annotations. Extensive experiments show that convolutional neural networks (CNNs) equipped with our PAL framework have achieved state-of-the-art (SOTA) results on multiple public datasets. Furthermore, our PAL framework can build a efficient and stable bridge between full supervision and point supervision tasks. Our code are available at https://github.com/YuChuang1205/PAL.
Refined Infrared Small Target Detection Scheme with Single-Point Supervision
Aug 05, 2024Recently, infrared small target detection with single-point supervision has attracted extensive attention. However, the detection accuracy of existing methods has difficulty meeting actual needs. Therefore, we propose an innovative refined infrared small target detection scheme with single-point supervision, which has excellent segmentation accuracy and detection rate. Specifically, we introduce label evolution with single point supervision (LESPS) framework and explore the performance of various excellent infrared small target detection networks based on this framework. Meanwhile, to improve the comprehensive performance, we construct a complete post-processing strategy. On the one hand, to improve the segmentation accuracy, we use a combination of test-time augmentation (TTA) and conditional random field (CRF) for post-processing. On the other hand, to improve the detection rate, we introduce an adjustable sensitivity (AS) strategy for post-processing, which fully considers the advantages of multiple detection results and reasonably adds some areas with low confidence to the fine segmentation image in the form of centroid points. In addition, to further improve the performance and explore the characteristics of this task, on the one hand, we construct and find that a multi-stage loss is helpful for fine-grained detection. On the other hand, we find that a reasonable sliding window cropping strategy for test samples has better performance for actual multi-size samples. Extensive experimental results show that the proposed scheme achieves state-of-the-art (SOTA) performance. Notably, the proposed scheme won the third place in the "ICPR 2024 Resource-Limited Infrared Small Target Detection Challenge Track 1: Weakly Supervised Infrared Small Target Detection".
LR-Net: A Lightweight and Robust Network for Infrared Small Target Detection
Aug 05, 2024



Limited by equipment limitations and the lack of target intrinsic features, existing infrared small target detection methods have difficulty meeting actual comprehensive performance requirements. Therefore, we propose an innovative lightweight and robust network (LR-Net), which abandons the complex structure and achieves an effective balance between detection accuracy and resource consumption. Specifically, to ensure the lightweight and robustness, on the one hand, we construct a lightweight feature extraction attention (LFEA) module, which can fully extract target features and strengthen information interaction across channels. On the other hand, we construct a simple refined feature transfer (RFT) module. Compared with direct cross-layer connections, the RFT module can improve the network's feature refinement extraction capability with little resource consumption. Meanwhile, to solve the problem of small target loss in high-level feature maps, on the one hand, we propose a low-level feature distribution (LFD) strategy to use low-level features to supplement the information of high-level features. On the other hand, we introduce an efficient simplified bilinear interpolation attention module (SBAM) to promote the guidance constraints of low-level features on high-level features and the fusion of the two. In addition, We abandon the traditional resizing method and adopt a new training and inference cropping strategy, which is more robust to datasets with multi-scale samples. Extensive experimental results show that our LR-Net achieves state-of-the-art (SOTA) performance. Notably, on the basis of the proposed LR-Net, we achieve 3rd place in the "ICPR 2024 Resource-Limited Infrared Small Target Detection Challenge Track 2: Lightweight Infrared Small Target Detection".
Multi-Scale Direction-Aware Network for Infrared Small Target Detection
Jun 04, 2024



Infrared small target detection faces the problem that it is difficult to effectively separate the background and the target. Existing deep learning-based methods focus on appearance features and ignore high-frequency directional features. Therefore, we propose a multi-scale direction-aware network (MSDA-Net), which is the first attempt to integrate the high-frequency directional features of infrared small targets as domain prior knowledge into neural networks. Specifically, an innovative multi-directional feature awareness (MDFA) module is constructed, which fully utilizes the prior knowledge of targets and emphasizes the focus on high-frequency directional features. On this basis, combined with the multi-scale local relation learning (MLRL) module, a multi-scale direction-aware (MSDA) module is further constructed. The MSDA module promotes the full extraction of local relations at different scales and the full perception of key features in different directions. Meanwhile, a high-frequency direction injection (HFDI) module without training parameters is constructed to inject the high-frequency directional information of the original image into the network. This helps guide the network to pay attention to detailed information such as target edges and shapes. In addition, we propose a feature aggregation (FA) structure that aggregates multi-level features to solve the problem of small targets disappearing in deep feature maps. Furthermore, a lightweight feature alignment fusion (FAF) module is constructed, which can effectively alleviate the pixel offset existing in multi-level feature map fusion. Extensive experimental results show that our MSDA-Net achieves state-of-the-art (SOTA) results on the public NUDT-SIRST, SIRST and IRSTD-1k datasets.
Relational Representation Learning Network for Cross-Spectral Image Patch Matching
Mar 18, 2024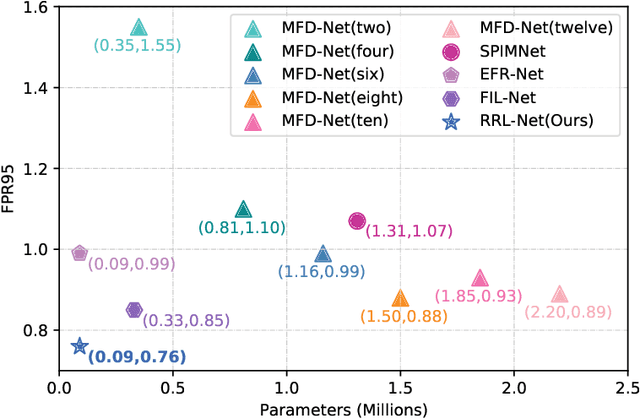
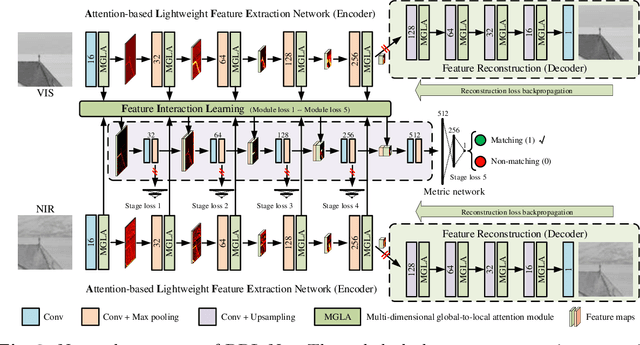
Recently, feature relation learning has drawn widespread attention in cross-spectral image patch matching. However, existing related research focuses on extracting diverse relations between image patch features and ignores sufficient intrinsic feature representations of individual image patches. Therefore, an innovative relational representation learning idea is proposed for the first time, which simultaneously focuses on sufficiently mining the intrinsic features of individual image patches and the relations between image patch features. Based on this, we construct a lightweight Relational Representation Learning Network (RRL-Net). Specifically, we innovatively construct an autoencoder to fully characterize the individual intrinsic features, and introduce a Feature Interaction Learning (FIL) module to extract deep-level feature relations. To further fully mine individual intrinsic features, a lightweight Multi-dimensional Global-to-Local Attention (MGLA) module is constructed to enhance the global feature extraction of individual image patches and capture local dependencies within global features. By combining the MGLA module, we further explore the feature extraction network and construct an Attention-based Lightweight Feature Extraction (ALFE) network. In addition, we propose a Multi-Loss Post-Pruning (MLPP) optimization strategy, which greatly promotes network optimization while avoiding increases in parameters and inference time. Extensive experiments demonstrate that our RRL-Net achieves state-of-the-art (SOTA) performance on multiple public datasets. Our code will be made public later.
ToP-ToM: Trust-aware Robot Policy with Theory of Mind
Nov 07, 2023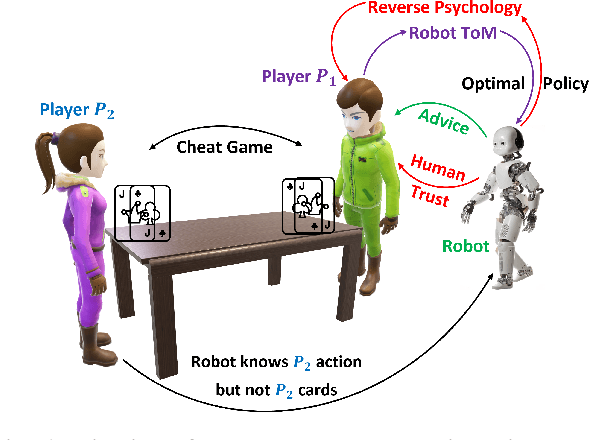
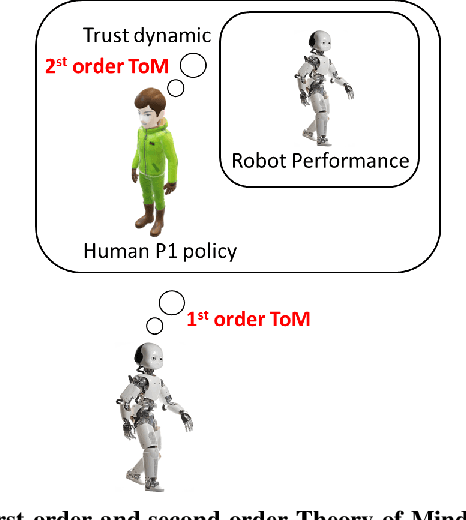
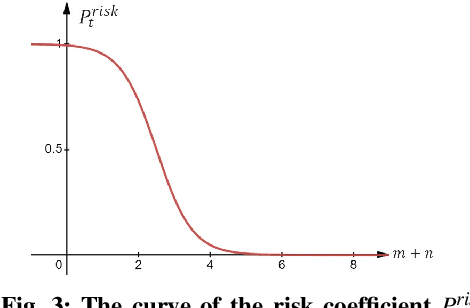
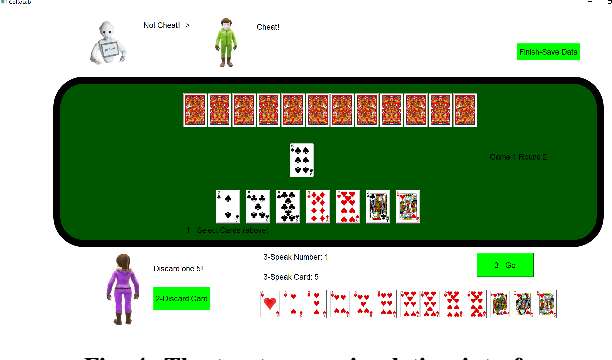
Theory of Mind (ToM) is a fundamental cognitive architecture that endows humans with the ability to attribute mental states to others. Humans infer the desires, beliefs, and intentions of others by observing their behavior and, in turn, adjust their actions to facilitate better interpersonal communication and team collaboration. In this paper, we investigated trust-aware robot policy with the theory of mind in a multiagent setting where a human collaborates with a robot against another human opponent. We show that by only focusing on team performance, the robot may resort to the reverse psychology trick, which poses a significant threat to trust maintenance. The human's trust in the robot will collapse when they discover deceptive behavior by the robot. To mitigate this problem, we adopt the robot theory of mind model to infer the human's trust beliefs, including true belief and false belief (an essential element of ToM). We designed a dynamic trust-aware reward function based on different trust beliefs to guide the robot policy learning, which aims to balance between avoiding human trust collapse due to robot reverse psychology. The experimental results demonstrate the importance of the ToM-based robot policy for human-robot trust and the effectiveness of our robot ToM-based robot policy in multiagent interaction settings.
Audio Event-Relational Graph Representation Learning for Acoustic Scene Classification
Oct 05, 2023



Most deep learning-based acoustic scene classification (ASC) approaches identify scenes based on acoustic features converted from audio clips containing mixed information entangled by polyphonic audio events (AEs). However, these approaches have difficulties in explaining what cues they use to identify scenes. This paper conducts the first study on disclosing the relationship between real-life acoustic scenes and semantic embeddings from the most relevant AEs. Specifically, we propose an event-relational graph representation learning (ERGL) framework for ASC to classify scenes, and simultaneously answer clearly and straightly which cues are used in classifying. In the event-relational graph, embeddings of each event are treated as nodes, while relationship cues derived from each pair of nodes are described by multi-dimensional edge features. Experiments on a real-life ASC dataset show that the proposed ERGL achieves competitive performance on ASC by learning embeddings of only a limited number of AEs. The results show the feasibility of recognizing diverse acoustic scenes based on the audio event-relational graph. Visualizations of graph representations learned by ERGL are available here (https://github.com/Yuanbo2020/ERGL).
Multi-dimensional Edge-based Audio Event Relational Graph Representation Learning for Acoustic Scene Classification
Nov 01, 2022Most existing deep learning-based acoustic scene classification (ASC) approaches directly utilize representations extracted from spectrograms to identify target scenes. However, these approaches pay little attention to the audio events occurring in the scene despite they provide crucial semantic information. This paper conducts the first study that investigates whether real-life acoustic scenes can be reliably recognized based only on the features that describe a limited number of audio events. To model the task-specific relationships between coarse-grained acoustic scenes and fine-grained audio events, we propose an event relational graph representation learning (ERGL) framework for ASC. Specifically, ERGL learns a graph representation of an acoustic scene from the input audio, where the embedding of each event is treated as a node, while the relationship cues derived from each pair of event embeddings are described by a learned multidimensional edge feature. Experiments on a polyphonic acoustic scene dataset show that the proposed ERGL achieves competitive performance on ASC by using only a limited number of embeddings of audio events without any data augmentations. The validity of the proposed ERGL framework proves the feasibility of recognizing diverse acoustic scenes based on the event relational graph. Our code is available on our homepage (https://github.com/Yuanbo2020/ERGL).