 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLNet: Cross-View Correspondence Makes a Stronger Geo-Localizationer
Dec 16, 2025Image retrieval-based cross-view geo-localization (IRCVGL) aims to match images captured from significantly different viewpoints, such as satellite and street-level images. Existing methods predominantly rely on learning robust global representations or implicit feature alignment, which often fail to model explicit spatial correspondences crucial for accurate localization. In this work, we propose a novel correspondence-aware feature refinement framework, termed CLNet, that explicitly bridges the semantic and geometric gaps between different views. CLNet decomposes the view alignment process into three learnable and complementary modules: a Neural Correspondence Map (NCM) that spatially aligns cross-view features via latent correspondence fields; a Nonlinear Embedding Converter (NEC) that remaps features across perspectives using an MLP-based transformation; and a Global Feature Recalibration (GFR) module that reweights informative feature channels guided by learned spatial cues. The proposed CLNet can jointly capture both high-level semantics and fine-grained alignments. Extensive experiments on four public benchmarks, CVUSA, CVACT, VIGOR, and University-1652, demonstrate that our proposed CLNet achieves state-of-the-art performance while offering better interpretability and generalizability.
Lightweight Adapter Learning for More Generalized Remote Sensing Change Detection
Apr 28, 2025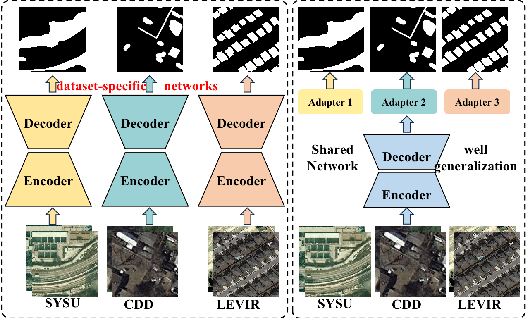

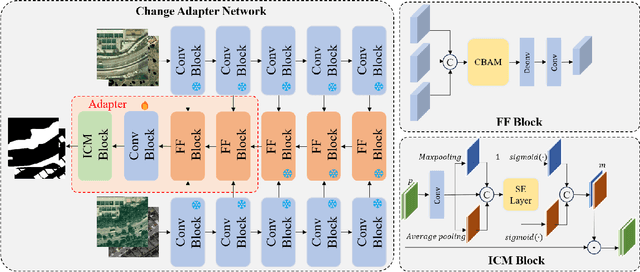
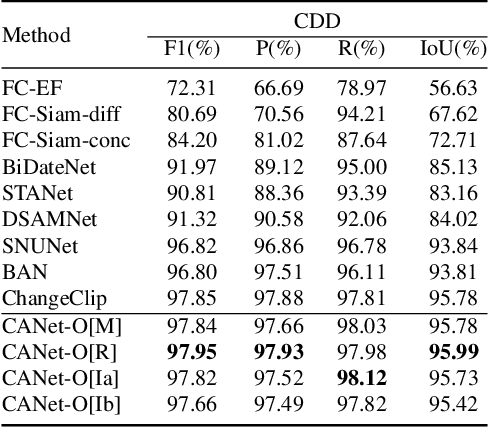
Deep learning methods have shown promising performances in remote sensing image change detection (CD). However, existing methods usually train a dataset-specific deep network for each dataset. Due to the significant differences in the data distribution and labeling between various datasets, the trained dataset-specific deep network has poor generalization performances on other datasets. To solve this problem, this paper proposes a change adapter network (CANet) for a more universal and generalized CD. CANet contains dataset-shared and dataset-specific learning modules. The former explores the discriminative features of images, and the latter designs a lightweight adapter model, to deal with the characteristics of different datasets in data distribution and labeling. The lightweight adapter can quickly generalize the deep network for new CD tasks with a small computation cost. Specifically, this paper proposes an interesting change region mask (ICM) in the adapter, which can adaptively focus on interested change objects and decrease the influence of labeling differences in various datasets. Moreover, CANet adopts a unique batch normalization layer for each dataset to deal with data distribution differences. Compared with existing deep learning methods, CANet can achieve satisfactory CD performances on various datasets simultaneously. Experimental results on several public datasets have verified the effectiveness and advantages of the proposed CANet on CD. CANet has a stronger generalization ability, smaller training costs (merely updating 4.1%-7.7% parameters), and better performances under limited training datasets than other deep learning methods, which also can be flexibly inserted with existing deep models.
Generalization-aware Remote Sensing Change Detection via Domain-agnostic Learning
Apr 01, 2025Change detection has essential significance for the region's development, in which pseudo-changes between bitemporal images induced by imaging environmental factors are key challenges. Existing transformation-based methods regard pseudo-changes as a kind of style shift and alleviate it by transforming bitemporal images into the same style using generative adversarial networks (GANs). However, their efforts are limited by two drawbacks: 1) Transformed images suffer from distortion that reduces feature discrimination. 2) Alignment hampers the model from learning domain-agnostic representations that degrades performance on scenes with domain shifts from the training data. Therefore, oriented from pseudo-changes caused by style differences, we present a generalizable domain-agnostic difference learning network (DonaNet). For the drawback 1), we argue for local-level statistics as style proxies to assist against domain shifts. For the drawback 2), DonaNet learns domain-agnostic representations by removing domain-specific style of encoded features and highlighting the class characteristics of objects. In the removal, we propose a domain difference removal module to reduce feature variance while preserving discriminative properties and propose its enhanced version to provide possibilities for eliminating more style by decorrelating the correlation between features. In the highlighting, we propose a cross-temporal generalization learning strategy to imitate latent domain shifts, thus enabling the model to extract feature representations more robust to shifts actively. Extensive experiments conducted on three public datasets demonstrate that DonaNet outperforms existing state-of-the-art methods with a smaller model size and is more robust to domain shift.
Transcending Fusion: A Multi-Scale Alignment Method for Remote Sensing Image-Text Retrieval
May 29, 2024



Remote Sensing Image-Text Retrieval (RSITR) is pivotal for knowledge services and data mining in the remote sensing (RS) domain. Considering the multi-scale representations in image content and text vocabulary can enable the models to learn richer representations and enhance retrieval. Current multi-scale RSITR approaches typically align multi-scale fused image features with text features, but overlook aligning image-text pairs at distinct scales separately. This oversight restricts their ability to learn joint representations suitable for effective retrieval. We introduce a novel Multi-Scale Alignment (MSA) method to overcome this limitation. Our method comprises three key innovations: (1) Multi-scale Cross-Modal Alignment Transformer (MSCMAT), which computes cross-attention between single-scale image features and localized text features, integrating global textual context to derive a matching score matrix within a mini-batch, (2) a multi-scale cross-modal semantic alignment loss that enforces semantic alignment across scales, and (3) a cross-scale multi-modal semantic consistency loss that uses the matching matrix from the largest scale to guide alignment at smaller scales. We evaluated our method across multiple datasets, demonstrating its efficacy with various visual backbones and establishing its superiority over existing state-of-the-art methods. The GitHub URL for our project is: https://github.com/yr666666/MSA
Relational Representation Learning Network for Cross-Spectral Image Patch Matching
Mar 18, 2024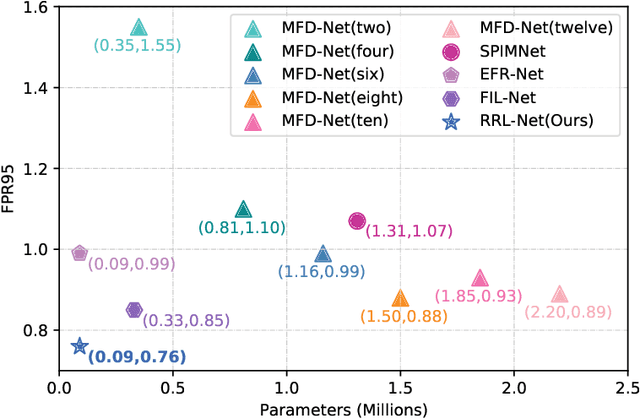
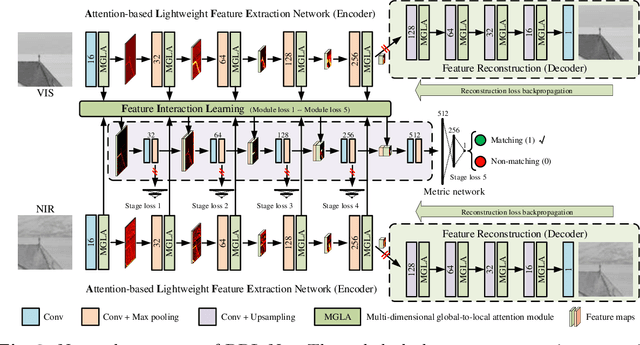
Recently, feature relation learning has drawn widespread attention in cross-spectral image patch matching. However, existing related research focuses on extracting diverse relations between image patch features and ignores sufficient intrinsic feature representations of individual image patches. Therefore, an innovative relational representation learning idea is proposed for the first time, which simultaneously focuses on sufficiently mining the intrinsic features of individual image patches and the relations between image patch features. Based on this, we construct a lightweight Relational Representation Learning Network (RRL-Net). Specifically, we innovatively construct an autoencoder to fully characterize the individual intrinsic features, and introduce a Feature Interaction Learning (FIL) module to extract deep-level feature relations. To further fully mine individual intrinsic features, a lightweight Multi-dimensional Global-to-Local Attention (MGLA) module is constructed to enhance the global feature extraction of individual image patches and capture local dependencies within global features. By combining the MGLA module, we further explore the feature extraction network and construct an Attention-based Lightweight Feature Extraction (ALFE) network. In addition, we propose a Multi-Loss Post-Pruning (MLPP) optimization strategy, which greatly promotes network optimization while avoiding increases in parameters and inference time. Extensive experiments demonstrate that our RRL-Net achieves state-of-the-art (SOTA) performance on multiple public datasets. Our code will be made public later.
Unsupervised Outlier Detection using Memory and Contrastive Learning
Jul 27, 2021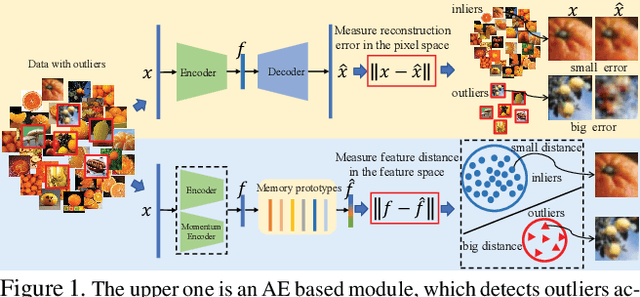
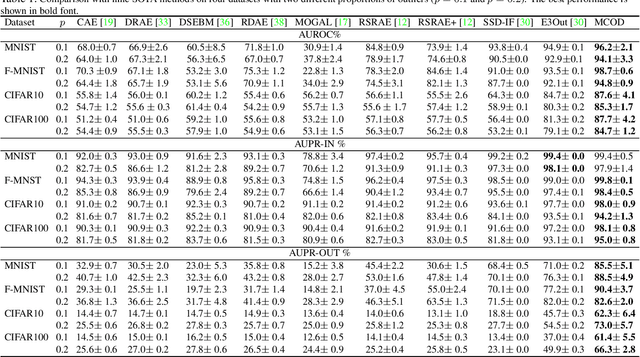


Outlier detection is one of the most important processes taken to create good, reliable data in machine learning. The most methods of outlier detection leverage an auxiliary reconstruction task by assuming that outliers are more difficult to be recovered than normal samples (inliers). However, it is not always true, especially for auto-encoder (AE) based models. They may recover certain outliers even outliers are not in the training data, because they do not constrain the feature learning. Instead, we think outlier detection can be done in the feature space by measuring the feature distance between outliers and inliers. We then propose a framework, MCOD, using a memory module and a contrastive learning module. The memory module constrains the consistency of features, which represent the normal data. The contrastive learning module learns more discriminating features, which boosts the distinction between outliers and inliers. Extensive experiments on four benchmark datasets show that our proposed MCOD achieves a considerable performance and outperforms nine state-of-the-art methods.