 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-oriented Order Learning for Facial Beauty Prediction
Sep 01, 2024



Previous Facial Beauty Prediction (FBP) methods generally model FB feature of an image as a point on the latent space, and learn a mapping from the point to a precise score. Although existing regression methods perform well on a single dataset, they are inclined to be sensitive to test data and have weak generalization ability. We think they underestimate two inconsistencies existing in the FBP problem: 1. inconsistency of FB standards among multiple datasets, and 2. inconsistency of human cognition on FB of an image. To address these issues, we propose a new Uncertainty-oriented Order Learning (UOL), where the order learning addresses the inconsistency of FB standards by learning the FB order relations among face images rather than a mapping, and the uncertainty modeling represents the inconsistency in human cognition. The key contribution of UOL is a designed distribution comparison module, which enables conventional order learning to learn the order of uncertain data. Extensive experiments on five datasets show that UOL outperforms the state-of-the-art methods on both accuracy and generalization ability.
WeKnow-RAG: An Adaptive Approach for Retrieval-Augmented Generation Integrating Web Search and Knowledge Graphs
Aug 14, 2024



Large Language Models (LLMs) have greatly contributed to the development of adaptive intelligent agents and are positioned as an important way to achieve Artificial General Intelligence (AGI). However, LLMs are prone to produce factually incorrect information and often produce "phantom" content that undermines their reliability, which poses a serious challenge for their deployment in real-world scenarios. Enhancing LLMs by combining external databases and information retrieval mechanisms is an effective path. To address the above challenges, we propose a new approach called WeKnow-RAG, which integrates Web search and Knowledge Graphs into a "Retrieval-Augmented Generation (RAG)" system. First, the accuracy and reliability of LLM responses are improved by combining the structured representation of Knowledge Graphs with the flexibility of dense vector retrieval. WeKnow-RAG then utilizes domain-specific knowledge graphs to satisfy a variety of queries and domains, thereby improving performance on factual information and complex reasoning tasks by employing multi-stage web page retrieval techniques using both sparse and dense retrieval methods. Our approach effectively balances the efficiency and accuracy of information retrieval, thus improving the overall retrieval process. Finally, we also integrate a self-assessment mechanism for the LLM to evaluate the trustworthiness of the answers it generates. Our approach proves its outstanding effectiveness in a wide range of offline experiments and online submissions.
Triple Disentangled Representation Learning for Multimodal Affective Analysis
Jan 29, 2024Multimodal learning has exhibited a significant advantage in affective analysis tasks owing to the comprehensive information of various modalities, particularly the complementary information. Thus, many emerging studies focus on disentangling the modality-invariant and modality-specific representations from input data and then fusing them for prediction. However, our study shows that modality-specific representations may contain information that is irrelevant or conflicting with the tasks, which downgrades the effectiveness of learned multimodal representations. We revisit the disentanglement issue, and propose a novel triple disentanglement approach, TriDiRA, which disentangles the modality-invariant, effective modality-specific and ineffective modality-specific representations from input data. By fusing only the modality-invariant and effective modality-specific representations, TriDiRA can significantly alleviate the impact of irrelevant and conflicting information across modalities during model training. Extensive experiments conducted on four benchmark datasets demonstrate the effectiveness and generalization of our triple disentanglement, which outperforms SOTA methods.
Learning Subjective Time-Series Data via Utopia Label Distribution Approximation
Jul 15, 2023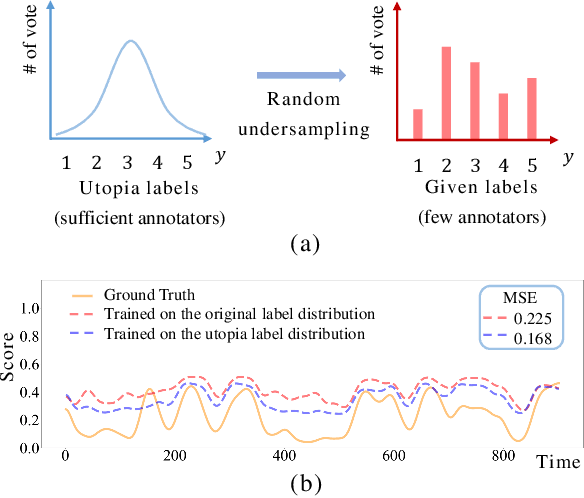
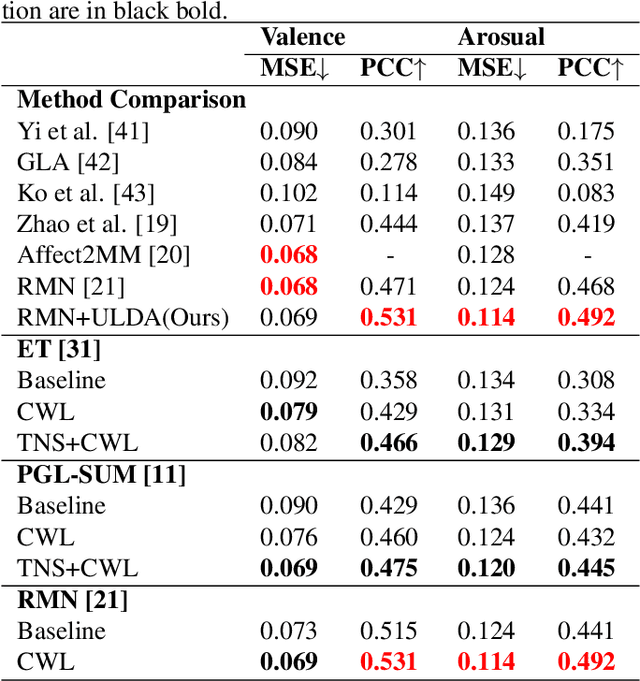
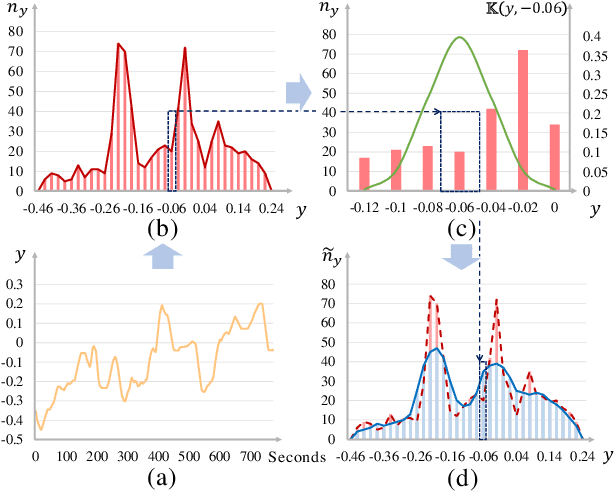
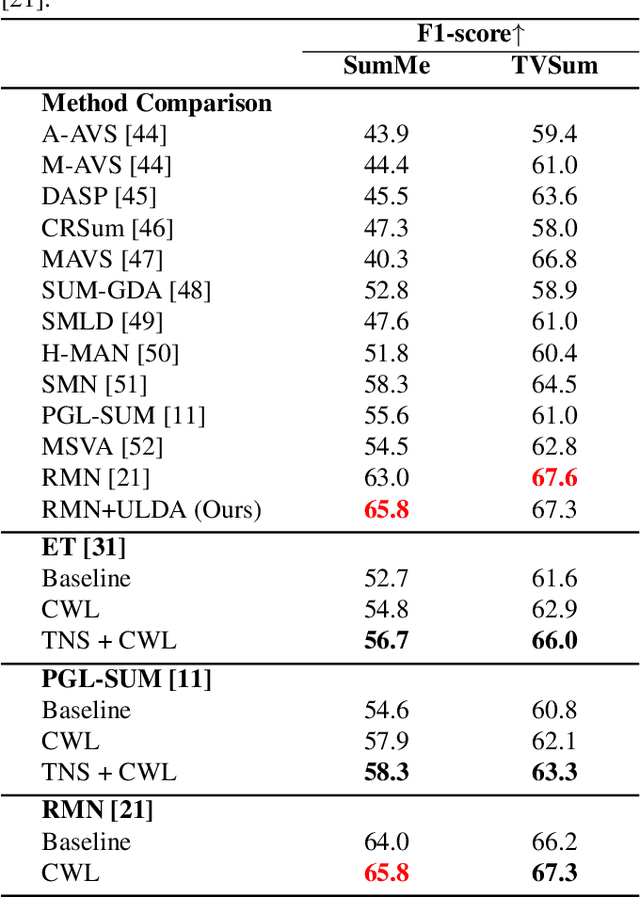
Subjective time-series regression (STR) tasks have gained increasing attention recently. However, most existing methods overlook the label distribution bias in STR data, which results in biased models. Emerging studies on imbalanced regression tasks, such as age estimation and depth estimation, hypothesize that the prior label distribution of the dataset is uniform. However, we observe that the label distributions of training and test sets in STR tasks are likely to be neither uniform nor identical. This distinct feature calls for new approaches that estimate more reasonable distributions to train a fair model. In this work, we propose Utopia Label Distribution Approximation (ULDA) for time-series data, which makes the training label distribution closer to real-world but unknown (utopia) label distribution. This would enhance the model's fairness. Specifically, ULDA first convolves the training label distribution by a Gaussian kernel. After convolution, the required sample quantity at each regression label may change. We further devise the Time-slice Normal Sampling (TNS) to generate new samples when the required sample quantity is greater than the initial sample quantity, and the Convolutional Weighted Loss (CWL) to lower the sample weight when the required sample quantity is less than the initial quantity. These two modules not only assist the model training on the approximated utopia label distribution, but also maintain the sample continuity in temporal context space. To the best of our knowledge, ULDA is the first method to address the label distribution bias in time-series data. Extensive experiments demonstrate that ULDA lifts the state-of-the-art performance on two STR tasks and three benchmark datasets.
Gaussian-smoothed Imbalance Data Improves Speech Emotion Recognition
Feb 17, 2023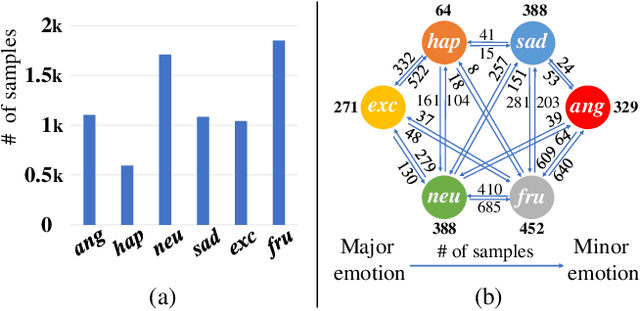
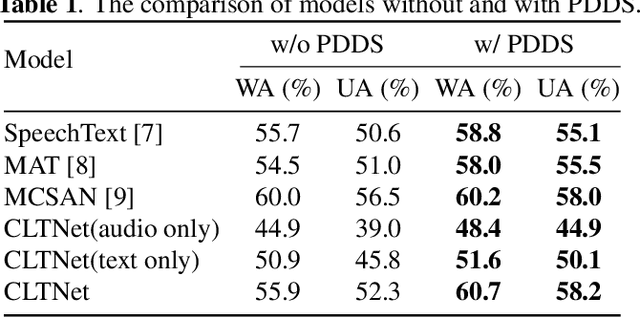
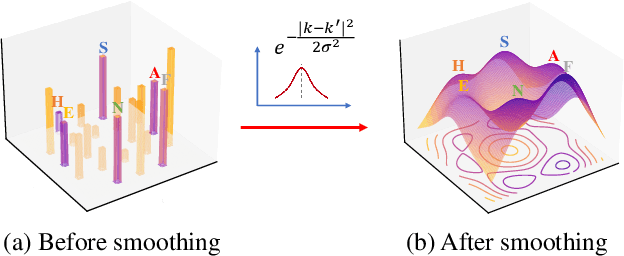

In speech emotion recognition tasks, models learn emotional representations from datasets. We find the data distribution in the IEMOCAP dataset is very imbalanced, which may harm models to learn a better representation. To address this issue, we propose a novel Pairwise-emotion Data Distribution Smoothing (PDDS) method. PDDS considers that the distribution of emotional data should be smooth in reality, then applies Gaussian smoothing to emotion-pairs for constructing a new training set with a smoother distribution. The required new data are complemented using the mixup augmentation. As PDDS is model and modality agnostic, it is evaluated with three SOTA models on the IEMOCAP dataset. The experimental results show that these models are improved by 0.2\% - 4.8\% and 1.5\% - 5.9\% in terms of WA and UA. In addition, an ablation study demonstrates that the key advantage of PDDS is the reasonable data distribution rather than a simple data augmentation.
Tripartite: Tackle Noisy Labels by a More Precise Partition
Feb 19, 2022



Samples in large-scale datasets may be mislabeled due to various reasons, and Deep Neural Networks can easily over-fit to the noisy label data. To tackle this problem, the key point is to alleviate the harm of these noisy labels. Many existing methods try to divide training data into clean and noisy subsets in terms of loss values, and then process the noisy label data varied. One of the reasons hindering a better performance is the hard samples. As hard samples always have relatively large losses whether their labels are clean or noisy, these methods could not divide them precisely. Instead, we propose a Tripartite solution to partition training data more precisely into three subsets: hard, noisy, and clean. The partition criteria are based on the inconsistent predictions of two networks, and the inconsistency between the prediction of a network and the given label. To minimize the harm of noisy labels but maximize the value of noisy label data, we apply a low-weight learning on hard data and a self-supervised learning on noisy label data without using the given labels. Extensive experiments demonstrate that Tripartite can filter out noisy label data more precisely, and outperforms most state-of-the-art methods on five benchmark datasets, especially on real-world datasets.
Unsupervised Outlier Detection using Memory and Contrastive Learning
Jul 27, 2021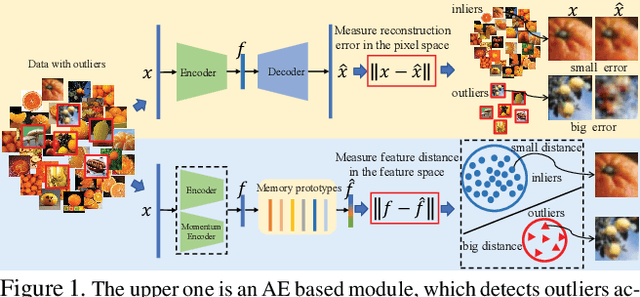
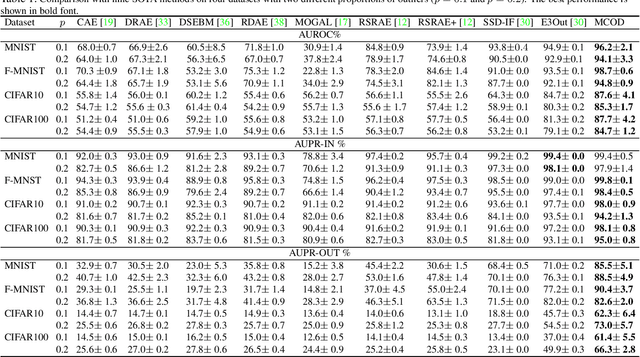


Outlier detection is one of the most important processes taken to create good, reliable data in machine learning. The most methods of outlier detection leverage an auxiliary reconstruction task by assuming that outliers are more difficult to be recovered than normal samples (inliers). However, it is not always true, especially for auto-encoder (AE) based models. They may recover certain outliers even outliers are not in the training data, because they do not constrain the feature learning. Instead, we think outlier detection can be done in the feature space by measuring the feature distance between outliers and inliers. We then propose a framework, MCOD, using a memory module and a contrastive learning module. The memory module constrains the consistency of features, which represent the normal data. The contrastive learning module learns more discriminating features, which boosts the distinction between outliers and inliers. Extensive experiments on four benchmark datasets show that our proposed MCOD achieves a considerable performance and outperforms nine state-of-the-art methods.
Multi-Classifier Interactive Learning for Ambiguous Speech Emotion Recognition
Dec 12, 2020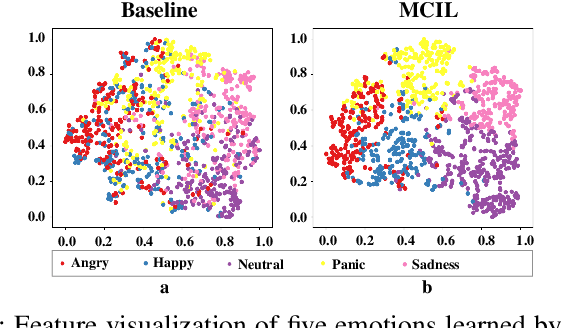
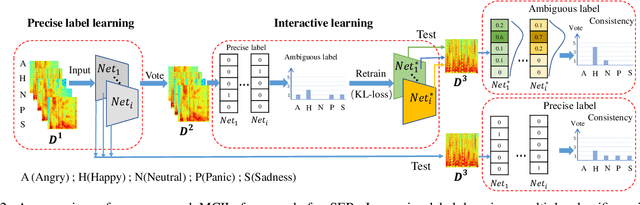
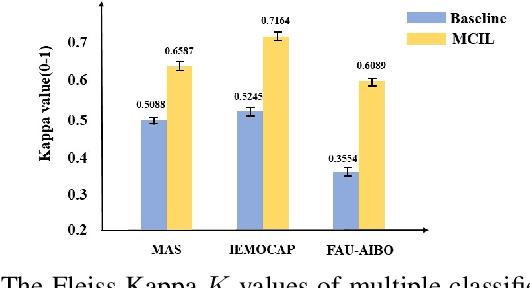
In recent years, speech emotion recognition technology is of great significance in industrial applications such as call centers, social robots and health care. The combination of speech recognition and speech emotion recognition can improve the feedback efficiency and the quality of service. Thus, the speech emotion recognition has been attracted much attention in both industry and academic. Since emotions existing in an entire utterance may have varied probabilities, speech emotion is likely to be ambiguous, which poses great challenges to recognition tasks. However, previous studies commonly assigned a single-label or multi-label to each utterance in certain. Therefore, their algorithms result in low accuracies because of the inappropriate representation. Inspired by the optimally interacting theory, we address the ambiguous speech emotions by proposing a novel multi-classifier interactive learning (MCIL) method. In MCIL, multiple different classifiers first mimic several individuals, who have inconsistent cognitions of ambiguous emotions, and construct new ambiguous labels (the emotion probability distribution). Then, they are retrained with the new labels to interact with their cognitions. This procedure enables each classifier to learn better representations of ambiguous data from others, and further improves the recognition ability. The experiments on three benchmark corpora (MAS, IEMOCAP, and FAU-AIBO) demonstrate that MCIL does not only improve each classifier's performance, but also raises their recognition consistency from moderate to substantial.
Happy Travelers Take Big Pictures: A Psychological Study with Machine Learning and Big Data
Sep 22, 2017
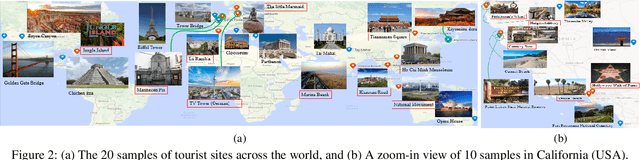
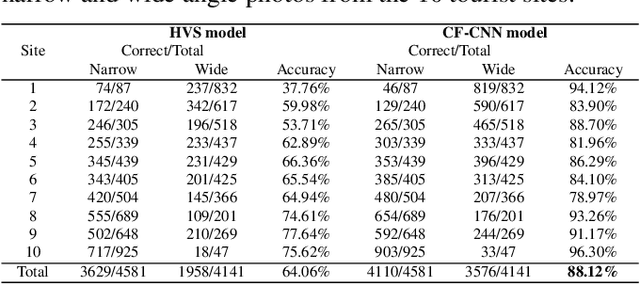
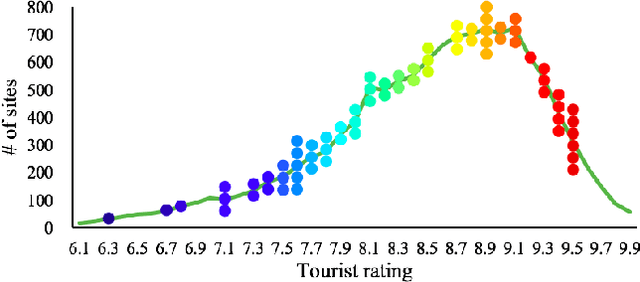
In psychology, theory-driven researches are usually conducted with extensive laboratory experiments, yet rarely tested or disproved with big data. In this paper, we make use of 418K travel photos with traveler ratings to test the influential "broaden-and-build" theory, that suggests positive emotions broaden one's visual attention. The core hypothesis examined in this study is that positive emotion is associated with a wider attention, hence highly-rated sites would trigger wide-angle photographs. By analyzing travel photos, we find a strong correlation between a preference for wide-angle photos and the high rating of tourist sites on TripAdvisor. We are able to carry out this analysis through the use of deep learning algorithms to classify the photos into wide and narrow angles, and present this study as an exemplar of how big data and deep learning can be used to test laboratory findings in the wild.
How Does the Low-Rank Matrix Decomposition Help Internal and External Learnings for Super-Resolution
Jun 30, 2017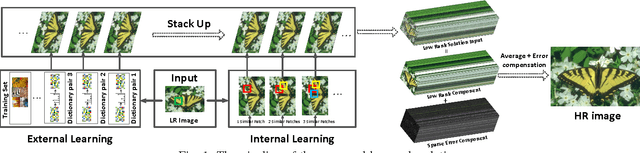
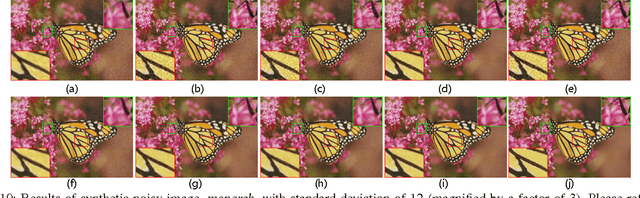
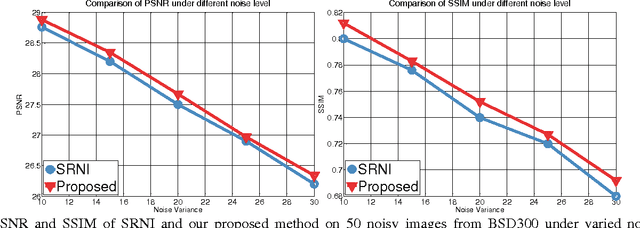

Wisely utilizing the internal and external learning methods is a new challenge in super-resolution problem. To address this issue, we analyze the attributes of two methodologies and find two observations of their recovered details: 1) they are complementary in both feature space and image plane, 2) they distribute sparsely in the spatial space. These inspire us to propose a low-rank solution which effectively integrates two learning methods and then achieves a superior result. To fit this solution, the internal learning method and the external learning method are tailored to produce multiple preliminary results. Our theoretical analysis and experiment prove that the proposed low-rank solution does not require massive inputs to guarantee the performance, and thereby simplifying the design of two learning methods for the solution. Intensive experiments show the proposed solution improves the single learning method in both qualitative and quantitative assessments. Surprisingly, it shows more superior capability on noisy images and outperforms state-of-the-art methods.