 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian-smoothed Imbalance Data Improves Speech Emotion Recognition
Paper and Code
Feb 17, 2023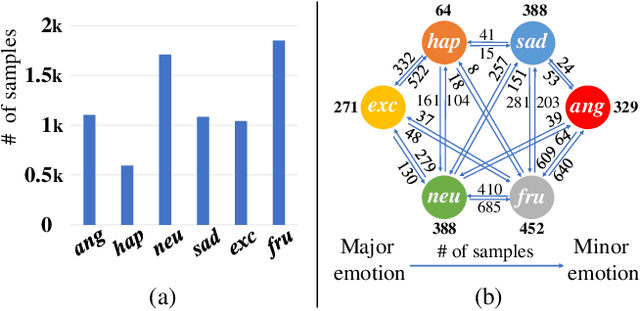
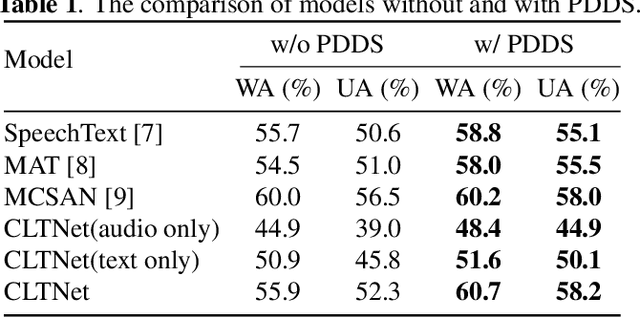
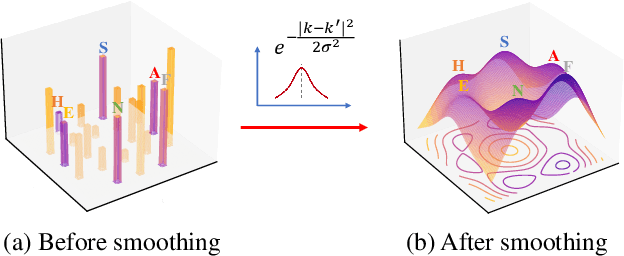

In speech emotion recognition tasks, models learn emotional representations from datasets. We find the data distribution in the IEMOCAP dataset is very imbalanced, which may harm models to learn a better representation. To address this issue, we propose a novel Pairwise-emotion Data Distribution Smoothing (PDDS) method. PDDS considers that the distribution of emotional data should be smooth in reality, then applies Gaussian smoothing to emotion-pairs for constructing a new training set with a smoother distribution. The required new data are complemented using the mixup augmentation. As PDDS is model and modality agnostic, it is evaluated with three SOTA models on the IEMOCAP dataset. The experimental results show that these models are improved by 0.2\% - 4.8\% and 1.5\% - 5.9\% in terms of WA and UA. In addition, an ablation study demonstrates that the key advantage of PDDS is the reasonable data distribution rather than a simple data augmentation.