 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Sample-Efficient and Stable Reinforcement Learning for LLM-based Recommendation
Jan 31, 2026While Long Chain-of-Thought (Long CoT) reasoning has shown promise in Large Language Models (LLMs), its adoption for enhancing recommendation quality is growing rapidly. In this work, we critically examine this trend and argue that Long CoT is inherently ill-suited for the sequential recommendation domain. We attribute this misalignment to two primary factors: excessive inference latency and the lack of explicit cognitive reasoning patterns in user behavioral data. Driven by these observations, we propose pivoting away from the CoT structure to directly leverage its underlying mechanism: Reinforcement Learning (RL), to explore the item space. However, applying RL directly faces significant obstacles, notably low sample efficiency-where most actions fail to provide learning signals-and training instability. To overcome these limitations, we propose RISER, a novel Reinforced Item Space Exploration framework for Recommendation. RISER is designed to transform non-learnable trajectories into effective pairwise preference data for optimization. Furthermore, it incorporates specific strategies to ensure stability, including the prevention of redundant rollouts and the constraint of token-level update magnitudes. Extensive experiments on three real-world datasets show that RISER significantly outperforms competitive baselines, establishing a robust paradigm for RL-enhanced LLM recommendation. Our code will be available at https://anonymous.4open.science/r/RISER/.
SKETCH: Semantic Key-Point Conditioning for Long-Horizon Vessel Trajectory Prediction
Jan 26, 2026Accurate long-horizon vessel trajectory prediction remains challenging due to compounded uncertainty from complex navigation behaviors and environmental factors. Existing methods often struggle to maintain global directional consistency, leading to drifting or implausible trajectories when extrapolated over long time horizons. To address this issue, we propose a semantic-key-point-conditioned trajectory modeling framework, in which future trajectories are predicted by conditioning on a high-level Next Key Point (NKP) that captures navigational intent. This formulation decomposes long-horizon prediction into global semantic decision-making and local motion modeling, effectively restricting the support of future trajectories to semantically feasible subsets. To efficiently estimate the NKP prior from historical observations, we adopt a pretrain-finetune strategy. Extensive experiments on real-world AIS data demonstrate that the proposed method consistently outperforms state-of-the-art approaches, particularly for long travel durations, directional accuracy, and fine-grained trajectory prediction.
Reinforced Latent Reasoning for LLM-based Recommendation
May 25, 2025Large Language Models (LLMs) have demonstrated impressive reasoning capabilities in complex problem-solving tasks, sparking growing interest in their application to preference reasoning in recommendation systems. Existing methods typically rely on fine-tuning with explicit chain-of-thought (CoT) data. However, these methods face significant practical limitations due to (1) the difficulty of obtaining high-quality CoT data in recommendation and (2) the high inference latency caused by generating CoT reasoning. In this work, we explore an alternative approach that shifts from explicit CoT reasoning to compact, information-dense latent reasoning. This approach eliminates the need for explicit CoT generation and improves inference efficiency, as a small set of latent tokens can effectively capture the entire reasoning process. Building on this idea, we propose $\textit{\underline{R}einforced \underline{Latent} \underline{R}easoning for \underline{R}ecommendation}$ (LatentR$^3$), a novel end-to-end training framework that leverages reinforcement learning (RL) to optimize latent reasoning without relying on any CoT data.LatentR$^3$ adopts a two-stage training strategy: first, supervised fine-tuning to initialize the latent reasoning module, followed by pure RL training to encourage exploration through a rule-based reward design. Our RL implementation is based on a modified GRPO algorithm, which reduces computational overhead during training and introduces continuous reward signals for more efficient learning. Extensive experiments demonstrate that LatentR$^3$ enables effective latent reasoning without any direct supervision of the reasoning process, significantly improving performance when integrated with different LLM-based recommendation methods. Our codes are available at https://anonymous.4open.science/r/R3-A278/.
Learning Subjective Time-Series Data via Utopia Label Distribution Approximation
Jul 15, 2023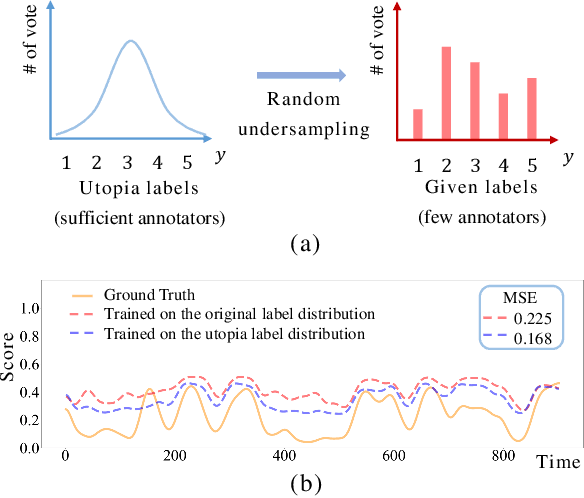
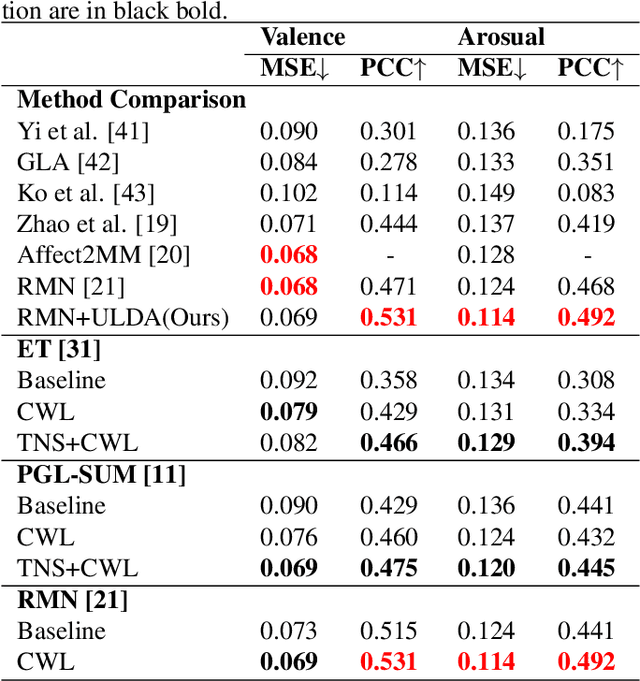
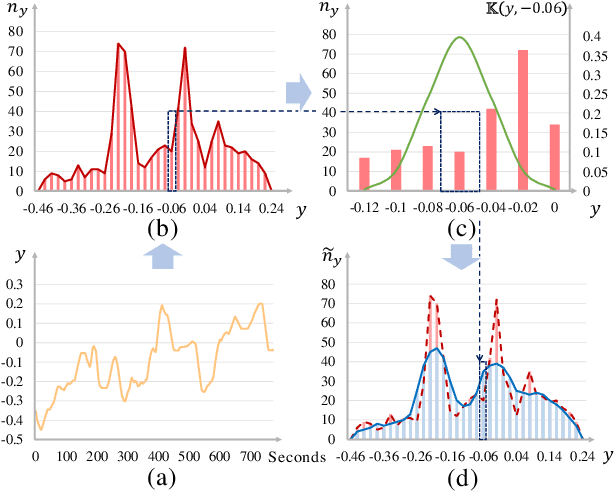
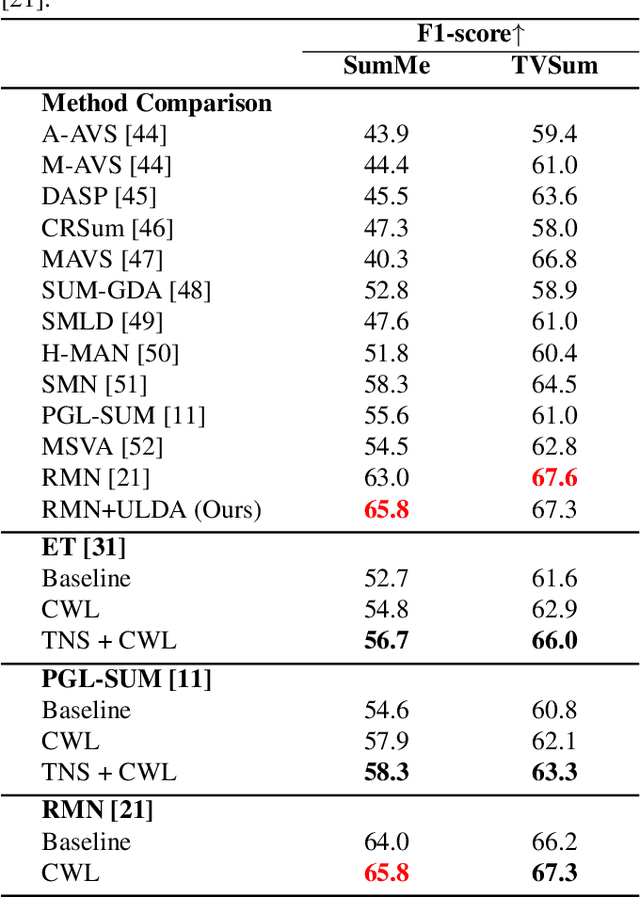
Subjective time-series regression (STR) tasks have gained increasing attention recently. However, most existing methods overlook the label distribution bias in STR data, which results in biased models. Emerging studies on imbalanced regression tasks, such as age estimation and depth estimation, hypothesize that the prior label distribution of the dataset is uniform. However, we observe that the label distributions of training and test sets in STR tasks are likely to be neither uniform nor identical. This distinct feature calls for new approaches that estimate more reasonable distributions to train a fair model. In this work, we propose Utopia Label Distribution Approximation (ULDA) for time-series data, which makes the training label distribution closer to real-world but unknown (utopia) label distribution. This would enhance the model's fairness. Specifically, ULDA first convolves the training label distribution by a Gaussian kernel. After convolution, the required sample quantity at each regression label may change. We further devise the Time-slice Normal Sampling (TNS) to generate new samples when the required sample quantity is greater than the initial sample quantity, and the Convolutional Weighted Loss (CWL) to lower the sample weight when the required sample quantity is less than the initial quantity. These two modules not only assist the model training on the approximated utopia label distribution, but also maintain the sample continuity in temporal context space. To the best of our knowledge, ULDA is the first method to address the label distribution bias in time-series data. Extensive experiments demonstrate that ULDA lifts the state-of-the-art performance on two STR tasks and three benchmark datasets.
Gaussian-smoothed Imbalance Data Improves Speech Emotion Recognition
Feb 17, 2023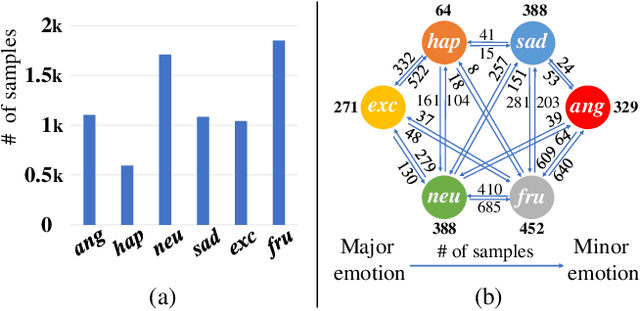
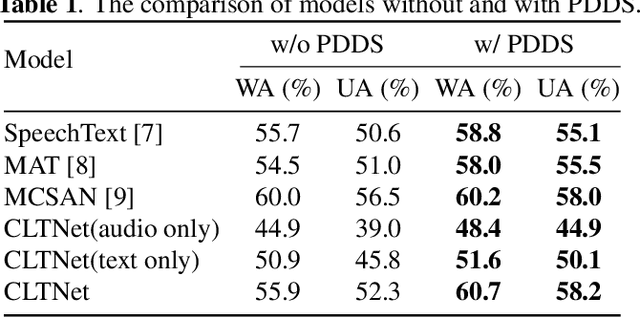
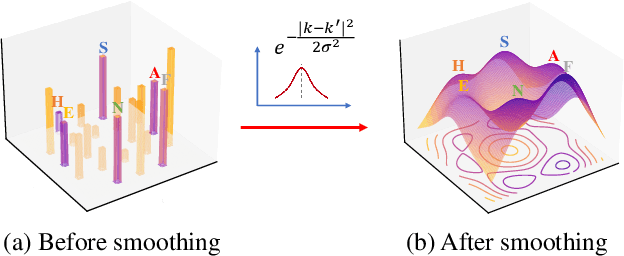

In speech emotion recognition tasks, models learn emotional representations from datasets. We find the data distribution in the IEMOCAP dataset is very imbalanced, which may harm models to learn a better representation. To address this issue, we propose a novel Pairwise-emotion Data Distribution Smoothing (PDDS) method. PDDS considers that the distribution of emotional data should be smooth in reality, then applies Gaussian smoothing to emotion-pairs for constructing a new training set with a smoother distribution. The required new data are complemented using the mixup augmentation. As PDDS is model and modality agnostic, it is evaluated with three SOTA models on the IEMOCAP dataset. The experimental results show that these models are improved by 0.2\% - 4.8\% and 1.5\% - 5.9\% in terms of WA and UA. In addition, an ablation study demonstrates that the key advantage of PDDS is the reasonable data distribution rather than a simple data augmentation.