 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Milestone Reward for GUI Agents
Feb 12, 2026Reinforcement Learning (RL) has emerged as a mainstream paradigm for training Mobile GUI Agents, yet it struggles with the temporal credit assignment problem inherent in long-horizon tasks. A primary challenge lies in the trade-off between reward fidelity and density: outcome reward offers high fidelity but suffers from signal sparsity, while process reward provides dense supervision but remains prone to bias and reward hacking. To resolve this conflict, we propose the Adaptive Milestone Reward (ADMIRE) mechanism. ADMIRE constructs a verifiable, adaptive reward system by anchoring trajectory to milestones, which are dynamically distilled from successful explorations. Crucially, ADMIRE integrates an asymmetric credit assignment strategy that denoises successful trajectories and scaffolds failed trajectories. Extensive experiments demonstrate that ADMIRE consistently yields over 10% absolute improvement in success rate across different base models on AndroidWorld. Moreover, the method exhibits robust generalizability, achieving strong performance across diverse RL algorithms and heterogeneous environments such as web navigation and embodied tasks.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
Hammer: Robust Function-Calling for On-Device Language Models via Function Masking
Oct 06, 2024
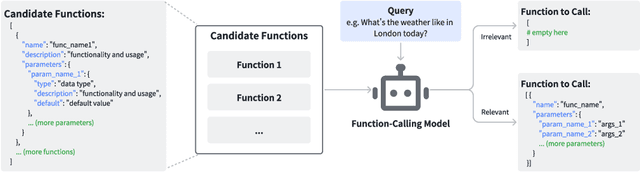


Large language models have demonstrated impressive value in performing as autonomous agents when equipped with external tools and API calls. Nonetheless, effectively harnessing their potential for executing complex tasks crucially relies on enhancements in their function calling capabilities. This paper identifies a critical gap in existing function calling models, where performance varies significantly across benchmarks, often due to being misled by specific naming conventions. To address such an issue, we introduce Hammer, a novel family of foundation models specifically engineered for on-device function calling. Hammer employs an augmented dataset that enhances models' sensitivity to irrelevant functions and incorporates function masking techniques to minimize misleading. Our empirical evaluations reveal that Hammer not only outperforms larger models but also demonstrates robust generalization across diverse benchmarks, achieving sota results. Our open source contributions include a specialized dataset for irrelevance detection, a tuning framework for enhanced generalization, and the Hammer models, establishing a new standard for function calling performance.
Bit Distribution Study and Implementation of Spatial Quality Map in the JPEG-AI Standardization
Feb 27, 2024Currently, there is a high demand for neural network-based image compression codecs. These codecs employ non-linear transforms to create compact bit representations and facilitate faster coding speeds on devices compared to the hand-crafted transforms used in classical frameworks. The scientific and industrial communities are highly interested in these properties, leading to the standardization effort of JPEG-AI. The JPEG-AI verification model has been released and is currently under development for standardization. Utilizing neural networks, it can outperform the classic codec VVC intra by over 10% BD-rate operating at base operation point. Researchers attribute this success to the flexible bit distribution in the spatial domain, in contrast to VVC intra's anchor that is generated with a constant quality point. However, our study reveals that VVC intra displays a more adaptable bit distribution structure through the implementation of various block sizes. As a result of our observations, we have proposed a spatial bit allocation method to optimize the JPEG-AI verification model's bit distribution and enhance the visual quality. Furthermore, by applying the VVC bit distribution strategy, the objective performance of JPEG-AI verification mode can be further improved, resulting in a maximum gain of 0.45 dB in PSNR-Y.
Bit Rate Matching Algorithm Optimization in JPEG-AI Verification Model
Feb 27, 2024The research on neural network (NN) based image compression has shown superior performance compared to classical compression frameworks. Unlike the hand-engineered transforms in the classical frameworks, NN-based models learn the non-linear transforms providing more compact bit representations, and achieve faster coding speed on parallel devices over their classical counterparts. Those properties evoked the attention of both scientific and industrial communities, resulting in the standardization activity JPEG-AI. The verification model for the standardization process of JPEG-AI is already in development and has surpassed the advanced VVC intra codec. To generate reconstructed images with the desired bits per pixel and assess the BD-rate performance of both the JPEG-AI verification model and VVC intra, bit rate matching is employed. However, the current state of the JPEG-AI verification model experiences significant slowdowns during bit rate matching, resulting in suboptimal performance due to an unsuitable model. The proposed methodology offers a gradual algorithmic optimization for matching bit rates, resulting in a fourfold acceleration and over 1% improvement in BD-rate at the base operation point. At the high operation point, the acceleration increases up to sixfold.
Triple Disentangled Representation Learning for Multimodal Affective Analysis
Jan 29, 2024

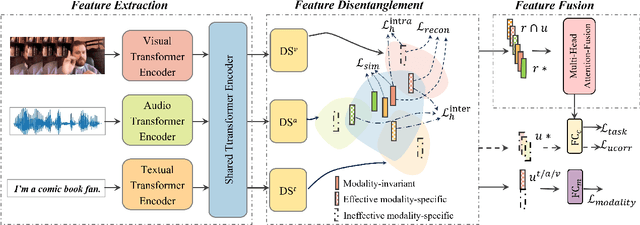

Multimodal learning has exhibited a significant advantage in affective analysis tasks owing to the comprehensive information of various modalities, particularly the complementary information. Thus, many emerging studies focus on disentangling the modality-invariant and modality-specific representations from input data and then fusing them for prediction. However, our study shows that modality-specific representations may contain information that is irrelevant or conflicting with the tasks, which downgrades the effectiveness of learned multimodal representations. We revisit the disentanglement issue, and propose a novel triple disentanglement approach, TriDiRA, which disentangles the modality-invariant, effective modality-specific and ineffective modality-specific representations from input data. By fusing only the modality-invariant and effective modality-specific representations, TriDiRA can significantly alleviate the impact of irrelevant and conflicting information across modalities during model training. Extensive experiments conducted on four benchmark datasets demonstrate the effectiveness and generalization of our triple disentanglement, which outperforms SOTA methods.
Learning Subjective Time-Series Data via Utopia Label Distribution Approximation
Jul 15, 2023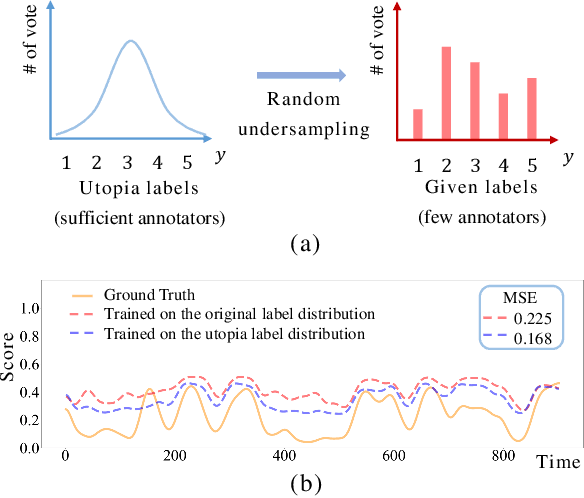
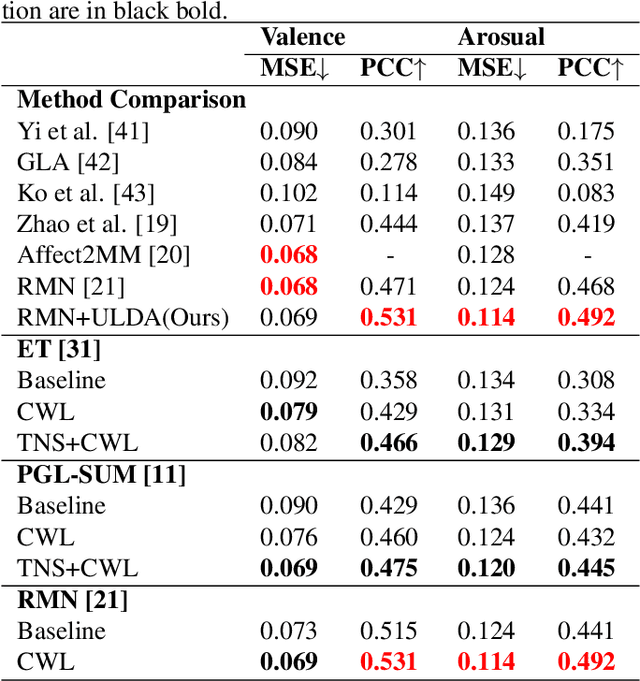
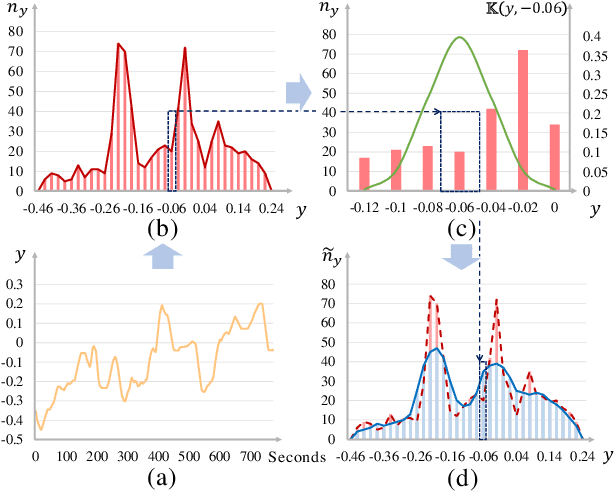
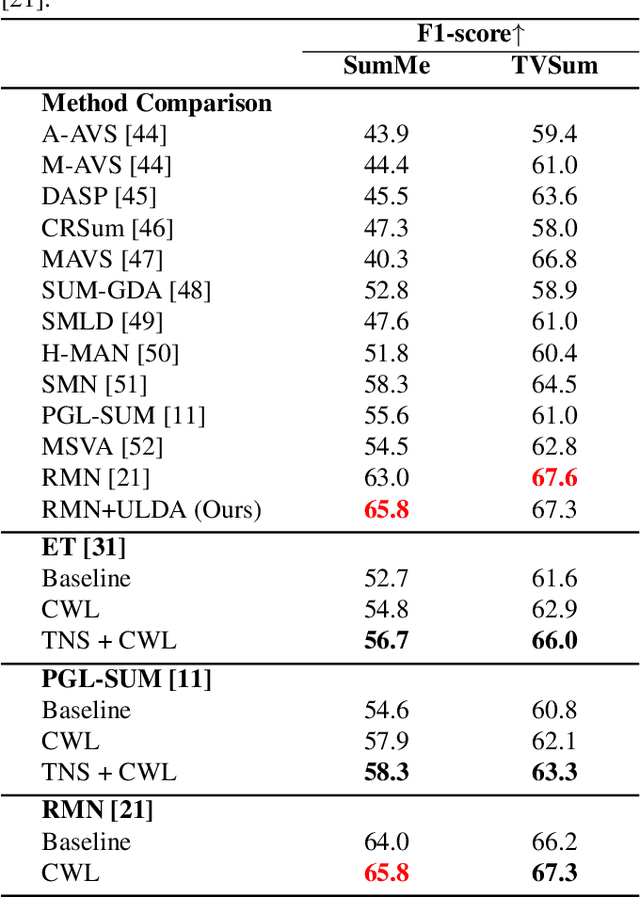
Subjective time-series regression (STR) tasks have gained increasing attention recently. However, most existing methods overlook the label distribution bias in STR data, which results in biased models. Emerging studies on imbalanced regression tasks, such as age estimation and depth estimation, hypothesize that the prior label distribution of the dataset is uniform. However, we observe that the label distributions of training and test sets in STR tasks are likely to be neither uniform nor identical. This distinct feature calls for new approaches that estimate more reasonable distributions to train a fair model. In this work, we propose Utopia Label Distribution Approximation (ULDA) for time-series data, which makes the training label distribution closer to real-world but unknown (utopia) label distribution. This would enhance the model's fairness. Specifically, ULDA first convolves the training label distribution by a Gaussian kernel. After convolution, the required sample quantity at each regression label may change. We further devise the Time-slice Normal Sampling (TNS) to generate new samples when the required sample quantity is greater than the initial sample quantity, and the Convolutional Weighted Loss (CWL) to lower the sample weight when the required sample quantity is less than the initial quantity. These two modules not only assist the model training on the approximated utopia label distribution, but also maintain the sample continuity in temporal context space. To the best of our knowledge, ULDA is the first method to address the label distribution bias in time-series data. Extensive experiments demonstrate that ULDA lifts the state-of-the-art performance on two STR tasks and three benchmark datasets.
Reducing the Covariate Shift by Mirror Samples in Cross Domain Alignment
Oct 13, 2021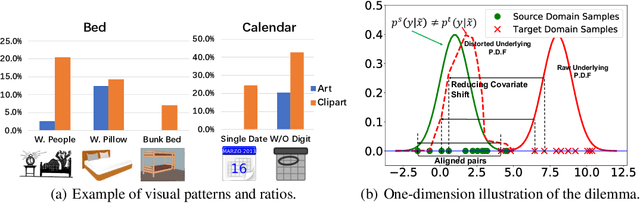
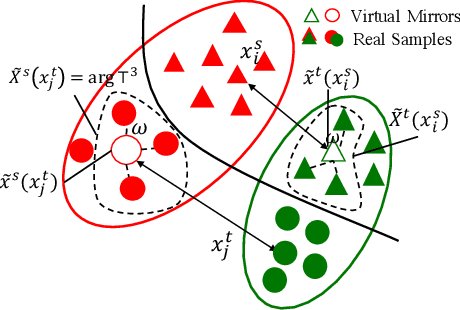

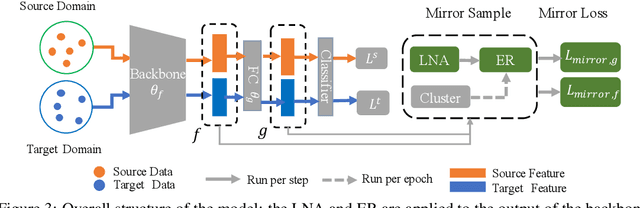
Eliminating the covariate shift cross domains is one of the common methods to deal with the issue of domain shift in visual unsupervised domain adaptation. However, current alignment methods, especially the prototype based or sample-level based methods neglect the structural properties of the underlying distribution and even break the condition of covariate shift. To relieve the limitations and conflicts, we introduce a novel concept named (virtual) mirror, which represents the equivalent sample in another domain. The equivalent sample pairs, named mirror pairs reflect the natural correspondence of the empirical distributions. Then a mirror loss, which aligns the mirror pairs cross domains, is constructed to enhance the alignment of the domains. The proposed method does not distort the internal structure of the underlying distribution. We also provide theoretical proof that the mirror samples and mirror loss have better asymptotic properties in reducing the domain shift. By applying the virtual mirror and mirror loss to the generic unsupervised domain adaptation model, we achieved consistent superior performance on several mainstream benchmarks.
Pairwise Emotional Relationship Recognition in Drama Videos: Dataset and Benchmark
Sep 23, 2021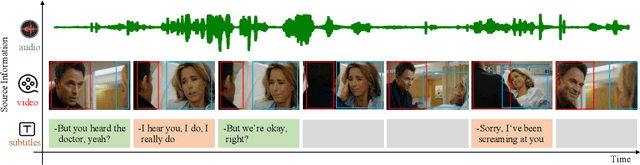
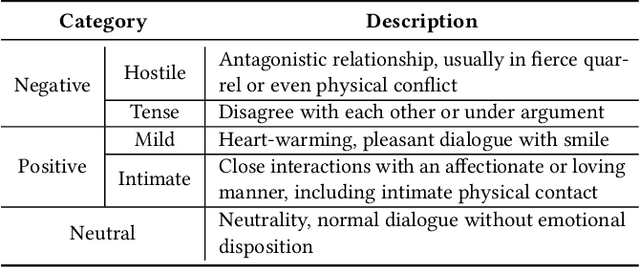
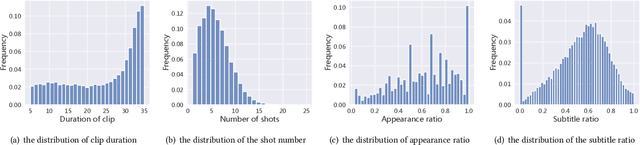
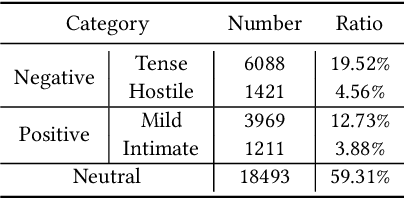
Recognizing the emotional state of people is a basic but challenging task in video understanding. In this paper, we propose a new task in this field, named Pairwise Emotional Relationship Recognition (PERR). This task aims to recognize the emotional relationship between the two interactive characters in a given video clip. It is different from the traditional emotion and social relation recognition task. Varieties of information, consisting of character appearance, behaviors, facial emotions, dialogues, background music as well as subtitles contribute differently to the final results, which makes the task more challenging but meaningful in developing more advanced multi-modal models. To facilitate the task, we develop a new dataset called Emotional RelAtionship of inTeractiOn (ERATO) based on dramas and movies. ERATO is a large-scale multi-modal dataset for PERR task, which has 31,182 video clips, lasting about 203 video hours. Different from the existing datasets, ERATO contains interaction-centric videos with multi-shots, varied video length, and multiple modalities including visual, audio and text. As a minor contribution, we propose a baseline model composed of Synchronous Modal-Temporal Attention (SMTA) unit to fuse the multi-modal information for the PERR task. In contrast to other prevailing attention mechanisms, our proposed SMTA can steadily improve the performance by about 1\%. We expect the ERATO as well as our proposed SMTA to open up a new way for PERR task in video understanding and further improve the research of multi-modal fusion methodology.
Subjective evaluation of traditional and learning-based image coding methods
Jul 28, 2021
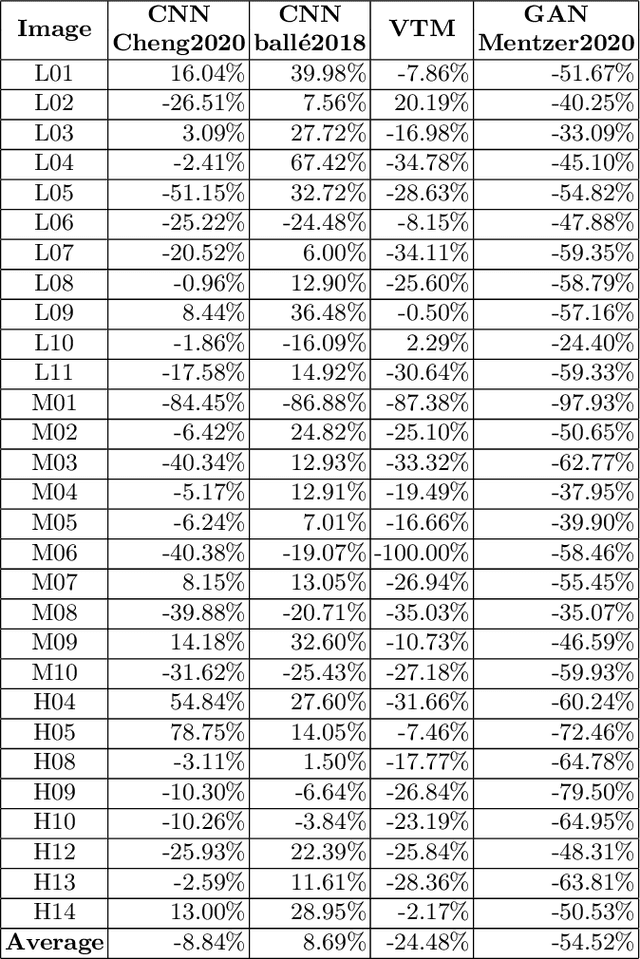
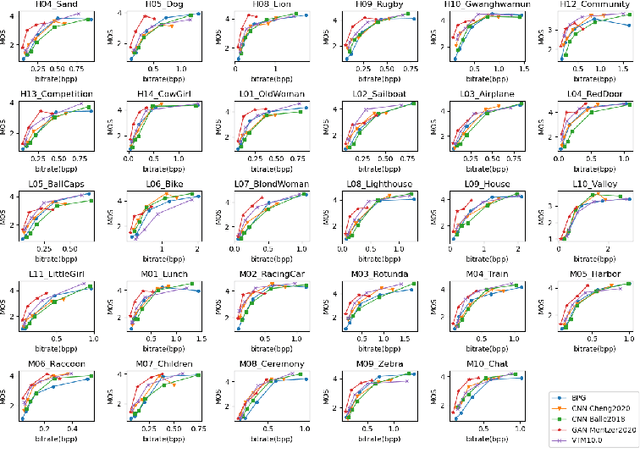

We conduct a subjective experiment to compare the performance of traditional image coding methods and learning-based image coding methods. HEVC and VVC, the state-of-the-art traditional coding methods, are used as the representative traditional methods. The learning-based methods used contain not only CNN-based methods, but also a GAN-based method, all of which are advanced or typical. Single Stimuli (SS), which is also called Absolute Category Rating (ACR), is adopted as the methodology of the experiment to obtain perceptual quality of images. Additionally, we utilize some typical and frequently used objective quality metrics to evaluate the coding methods in the experiment as comparison. The experiment shows that CNN-based and GAN-based methods can perform better than traditional methods in low bit-rates. In high bit-rates, however, it is hard to verify whether CNN-based methods are superior to traditional methods. Because the GAN method does not provide models with high target bit-rates, we cannot exactly tell the performance of the GAN method in high bit-rates. Furthermore, some popular objective quality metrics have not shown the ability well to measure quality of images generated by learning-based coding methods, especially the GAN-based one.