 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Multi-modal 3D Semantic Segmentation in Real-world Autonomous Driving
Oct 13, 2023LiDAR and camera are two critical sensors for multi-modal 3D semantic segmentation and are supposed to be fused efficiently and robustly to promise safety in various real-world scenarios. However, existing multi-modal methods face two key challenges: 1) difficulty with efficient deployment and real-time execution; and 2) drastic performance degradation under weak calibration between LiDAR and cameras. To address these challenges, we propose CPGNet-LCF, a new multi-modal fusion framework extending the LiDAR-only CPGNet. CPGNet-LCF solves the first challenge by inheriting the easy deployment and real-time capabilities of CPGNet. For the second challenge, we introduce a novel weak calibration knowledge distillation strategy during training to improve the robustness against the weak calibration. CPGNet-LCF achieves state-of-the-art performance on the nuScenes and SemanticKITTI benchmarks. Remarkably, it can be easily deployed to run in 20ms per frame on a single Tesla V100 GPU using TensorRT TF16 mode. Furthermore, we benchmark performance over four weak calibration levels, demonstrating the robustness of our proposed approach.
ESA-ReID: Entropy-Based Semantic Feature Alignment for Person re-ID
Jul 09, 2020
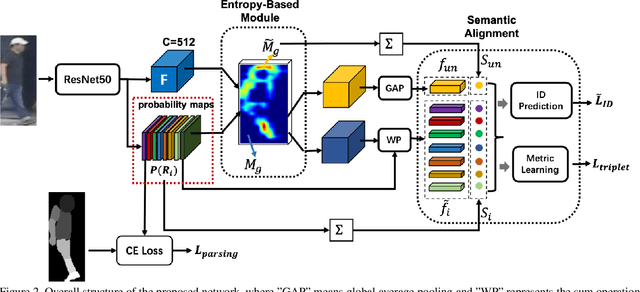
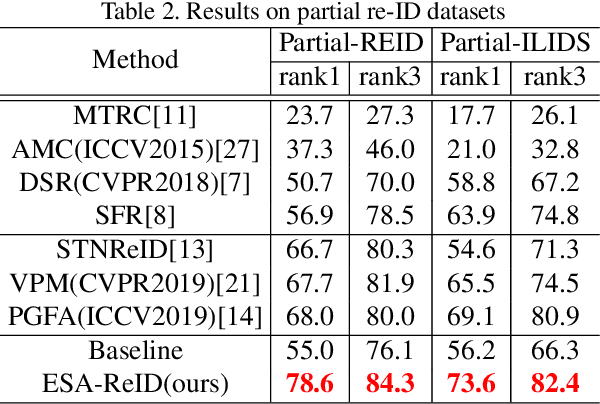
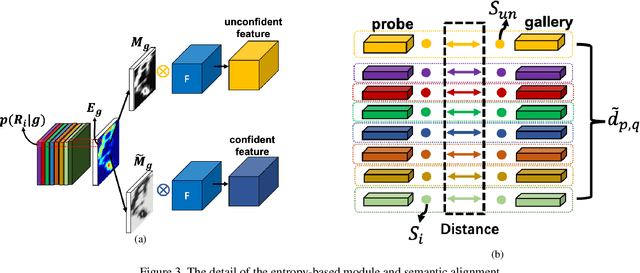
Person re-identification (re-ID) is a challenging task in real-world. Besides the typical application in surveillance system, re-ID also has significant values to improve the recall rate of people identification in content video (TV or Movies). However, the occlusion, shot angle variations and complicated background make it far away from application, especially in content video. In this paper we propose an entropy based semantic feature alignment model, which takes advantages of the detailed information of the human semantic feature. Considering the uncertainty of semantic segmentation, we introduce a semantic alignment with an entropy-based mask which can reduce the negative effects of mask segmentation errors. We construct a new re-ID dataset based on content videos with many cases of occlusion and body part missing, which will be released in future. Extensive studies on both existing datasets and the new dataset demonstrate the superior performance of the proposed model.
Video Affective Effects Prediction with Multi-modal Fusion and Shot-Long Temporal Context
Sep 01, 2019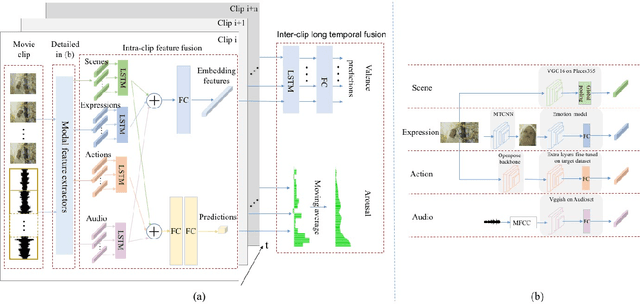
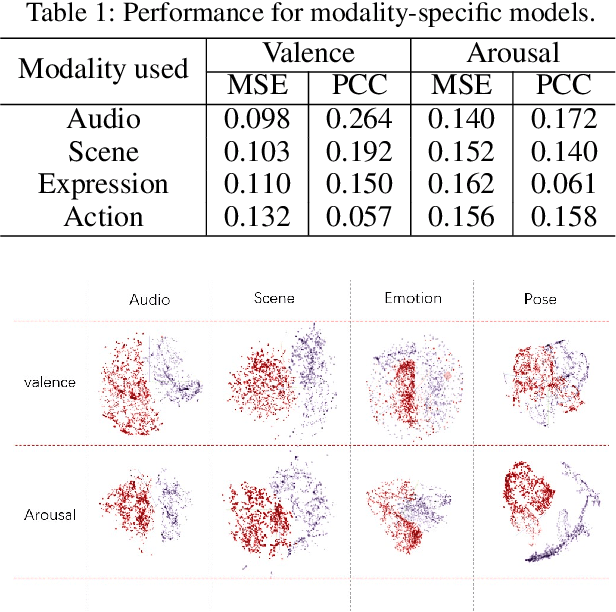
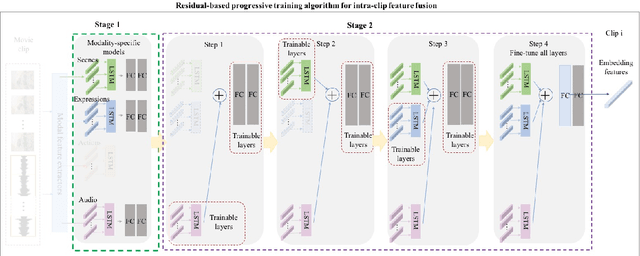
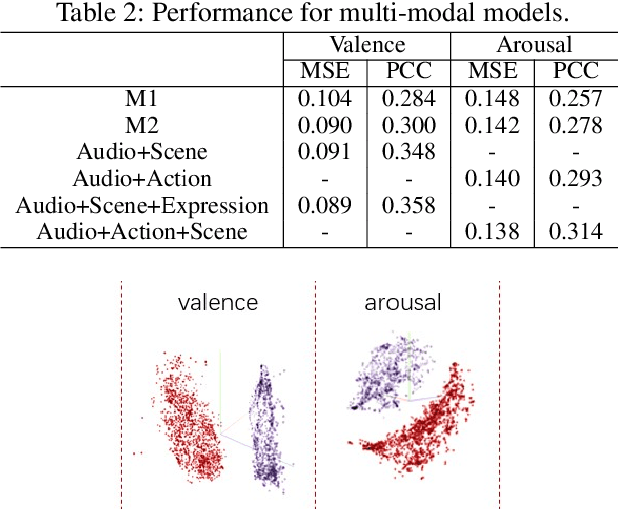
Predicting the emotional impact of videos using machine learning is a challenging task considering the varieties of modalities, the complicated temporal contex of the video as well as the time dependency of the emotional states. Feature extraction, multi-modal fusion and temporal context fusion are crucial stages for predicting valence and arousal values in the emotional impact, but have not been successfully exploited. In this paper, we propose a comprehensive framework with novel designs of modal structure and multi-modal fusion strategy. We select the most suitable modalities for valence and arousal tasks respectively and each modal feature is extracted using the modality-specific pre-trained deep model on large generic dataset. Two-time-scale structures, one for the intra-clip and the other for the inter-clip, are proposed to capture the temporal dependency of video content and emotion states. To combine the complementary information from multiple modalities, an effective and efficient residual-based progressive training strategy is proposed. Each modality is step-wisely combined into the multi-modal model, responsible for completing the missing parts of features. With all those improvements above, our proposed prediction framework achieves better performance on the LIRIS-ACCEDE dataset with a large margin compared to the state-of-the-art.