 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSonicBench: Dissecting the Physical Perception Bottleneck in Large Audio Language Models
Jan 16, 2026Large Audio Language Models (LALMs) excel at semantic and paralinguistic tasks, yet their ability to perceive the fundamental physical attributes of audio such as pitch, loudness, and spatial location remains under-explored. To bridge this gap, we introduce SonicBench, a psychophysically grounded benchmark that systematically evaluates 12 core physical attributes across five perceptual dimensions. Unlike previous datasets, SonicBench uses a controllable generation toolbox to construct stimuli for two complementary paradigms: recognition (absolute judgment) and comparison (relative judgment). This design allows us to probe not only sensory precision but also relational reasoning capabilities, a domain where humans typically exhibit greater proficiency. Our evaluation reveals a substantial deficiency in LALMs' foundational auditory understanding; most models perform near random guessing and, contrary to human patterns, fail to show the expected advantage on comparison tasks. Furthermore, explicit reasoning yields minimal gains. However, our linear probing analysis demonstrates crucially that frozen audio encoders do successfully capture these physical cues (accuracy at least 60%), suggesting that the primary bottleneck lies in the alignment and decoding stages, where models fail to leverage the sensory signals they have already captured.
OrchANN: A Unified I/O Orchestration Framework for Skewed Out-of-Core Vector Search
Dec 28, 2025Approximate nearest neighbor search (ANNS) at billion scale is fundamentally an out-of-core problem: vectors and indexes live on SSD, so performance is dominated by I/O rather than compute. Under skewed semantic embeddings, existing out-of-core systems break down: a uniform local index mismatches cluster scales, static routing misguides queries and inflates the number of probed partitions, and pruning is incomplete at the cluster level and lossy at the vector level, triggering "fetch-to-discard" reranking on raw vectors. We present OrchANN, an out-of-core ANNS engine that uses an I/O orchestration model for unified I/O governance along the route-access-verify pipeline. OrchANN selects a heterogeneous local index per cluster via offline auto-profiling, maintains a query-aware in-memory navigation graph that adapts to skewed workloads, and applies multi-level pruning with geometric bounds to filter both clusters and vectors before issuing SSD reads. Across five standard datasets under strict out-of-core constraints, OrchANN outperforms four baselines including DiskANN, Starling, SPANN, and PipeANN in both QPS and latency while reducing SSD accesses. Furthermore, OrchANN delivers up to 17.2x higher QPS and 25.0x lower latency than competing systems without sacrificing accuracy.
Semantic Co-Speech Gesture Synthesis and Real-Time Control for Humanoid Robots
Dec 19, 2025



We present an innovative end-to-end framework for synthesizing semantically meaningful co-speech gestures and deploying them in real-time on a humanoid robot. This system addresses the challenge of creating natural, expressive non-verbal communication for robots by integrating advanced gesture generation techniques with robust physical control. Our core innovation lies in the meticulous integration of a semantics-aware gesture synthesis module, which derives expressive reference motions from speech input by leveraging a generative retrieval mechanism based on large language models (LLMs) and an autoregressive Motion-GPT model. This is coupled with a high-fidelity imitation learning control policy, the MotionTracker, which enables the Unitree G1 humanoid robot to execute these complex motions dynamically and maintain balance. To ensure feasibility, we employ a robust General Motion Retargeting (GMR) method to bridge the embodiment gap between human motion data and the robot platform. Through comprehensive evaluation, we demonstrate that our combined system produces semantically appropriate and rhythmically coherent gestures that are accurately tracked and executed by the physical robot. To our knowledge, this work represents a significant step toward general real-world use by providing a complete pipeline for automatic, semantic-aware, co-speech gesture generation and synchronized real-time physical deployment on a humanoid robot.
MMAT-1M: A Large Reasoning Dataset for Multimodal Agent Tuning
Jul 29, 2025Large Language Models (LLMs), enhanced through agent tuning, have demonstrated remarkable capabilities in Chain-of-Thought (CoT) and tool utilization, significantly surpassing the performance of standalone models. However, the multimodal domain still lacks a large-scale, high-quality agent tuning dataset to unlock the full potential of multimodal large language models. To bridge this gap, we introduce MMAT-1M, the first million-scale multimodal agent tuning dataset designed to support CoT, reflection, and dynamic tool usage. Our dataset is constructed through a novel four-stage data engine: 1) We first curate publicly available multimodal datasets containing question-answer pairs; 2) Then, leveraging GPT-4o, we generate rationales for the original question-answer pairs and dynamically integrate API calls and Retrieval Augmented Generation (RAG) information through a multi-turn paradigm; 3) Furthermore, we refine the rationales through reflection to ensure logical consistency and accuracy, creating a multi-turn dialogue dataset with both Rationale and Reflection (RR); 4) Finally, to enhance efficiency, we optionally compress multi-turn dialogues into a One-turn Rationale and Reflection (ORR) format. By fine-tuning open-source multimodal models on the MMAT-1M, we observe significant performance gains. For instance, the InternVL2.5-8B-RR model achieves an average improvement of 2.7% across eight public benchmarks and 8.8% on the RAG benchmark Dyn-VQA, demonstrating the dataset's effectiveness in enhancing multimodal reasoning and tool-based capabilities. The dataset is publicly available at https://github.com/VIS-MPU-Agent/MMAT-1M.
On Data Synthesis and Post-training for Visual Abstract Reasoning
Apr 02, 2025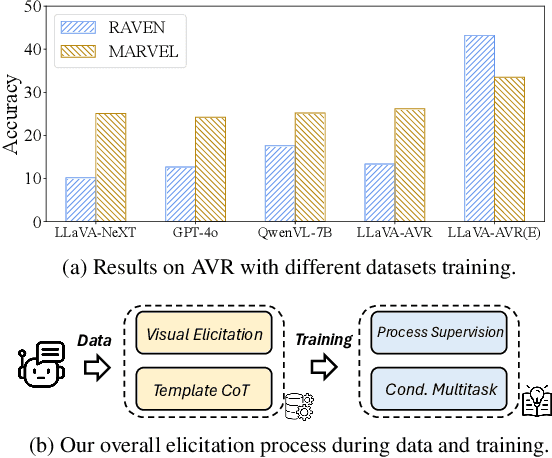



This paper is a pioneering work attempting to address abstract visual reasoning (AVR) problems for large vision-language models (VLMs). We make a common LLaVA-NeXT 7B model capable of perceiving and reasoning about specific AVR problems, surpassing both open-sourced (e.g., Qwen-2-VL-72B) and closed-sourced powerful VLMs (e.g., GPT-4o) with significant margin. This is a great breakthrough since almost all previous VLMs fail or show nearly random performance on representative AVR benchmarks. Our key success is our innovative data synthesis and post-training process, aiming to fully relieve the task difficulty and elicit the model to learn, step by step. Our 7B model is also shown to be behave well on AVR without sacrificing common multimodal comprehension abilities. We hope our paper could serve as an early effort in this area and would inspire further research in abstract visual reasoning.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Interpretable Face Anti-Spoofing: Enhancing Generalization with Multimodal Large Language Models
Jan 03, 2025



Face Anti-Spoofing (FAS) is essential for ensuring the security and reliability of facial recognition systems. Most existing FAS methods are formulated as binary classification tasks, providing confidence scores without interpretation. They exhibit limited generalization in out-of-domain scenarios, such as new environments or unseen spoofing types. In this work, we introduce a multimodal large language model (MLLM) framework for FAS, termed Interpretable Face Anti-Spoofing (I-FAS), which transforms the FAS task into an interpretable visual question answering (VQA) paradigm. Specifically, we propose a Spoof-aware Captioning and Filtering (SCF) strategy to generate high-quality captions for FAS images, enriching the model's supervision with natural language interpretations. To mitigate the impact of noisy captions during training, we develop a Lopsided Language Model (L-LM) loss function that separates loss calculations for judgment and interpretation, prioritizing the optimization of the former. Furthermore, to enhance the model's perception of global visual features, we design a Globally Aware Connector (GAC) to align multi-level visual representations with the language model. Extensive experiments on standard and newly devised One to Eleven cross-domain benchmarks, comprising 12 public datasets, demonstrate that our method significantly outperforms state-of-the-art methods.
Descriptive Caption Enhancement with Visual Specialists for Multimodal Perception
Dec 18, 2024



Training Large Multimodality Models (LMMs) relies on descriptive image caption that connects image and language. Existing methods either distill the caption from the LMM models or construct the captions from the internet images or by human. We propose to leverage off-the-shelf visual specialists, which were trained from annotated images initially not for image captioning, for enhancing the image caption. Our approach, named DCE, explores object low-level and fine-grained attributes (e.g., depth, emotion and fine-grained categories) and object relations (e.g., relative location and human-object-interaction (HOI)), and combine the attributes into the descriptive caption. Experiments demonstrate that such visual specialists are able to improve the performance for visual understanding tasks as well as reasoning that benefits from more accurate visual understanding. We will release the source code and the pipeline so that other visual specialists are easily combined into the pipeline. The complete source code of DCE pipeline and datasets will be available at \url{https://github.com/syp2ysy/DCE}.
ALoRE: Efficient Visual Adaptation via Aggregating Low Rank Experts
Dec 11, 2024



Parameter-efficient transfer learning (PETL) has become a promising paradigm for adapting large-scale vision foundation models to downstream tasks. Typical methods primarily leverage the intrinsic low rank property to make decomposition, learning task-specific weights while compressing parameter size. However, such approaches predominantly manipulate within the original feature space utilizing a single-branch structure, which might be suboptimal for decoupling the learned representations and patterns. In this paper, we propose ALoRE, a novel PETL method that reuses the hypercomplex parameterized space constructed by Kronecker product to Aggregate Low Rank Experts using a multi-branch paradigm, disentangling the learned cognitive patterns during training. Thanks to the artful design, ALoRE maintains negligible extra parameters and can be effortlessly merged into the frozen backbone via re-parameterization in a sequential manner, avoiding additional inference latency. We conduct extensive experiments on 24 image classification tasks using various backbone variants. Experimental results demonstrate that ALoRE outperforms the full fine-tuning strategy and other state-of-the-art PETL methods in terms of performance and parameter efficiency. For instance, ALoRE obtains 3.06% and 9.97% Top-1 accuracy improvement on average compared to full fine-tuning on the FGVC datasets and VTAB-1k benchmark by only updating 0.15M parameters.
Continual SFT Matches Multimodal RLHF with Negative Supervision
Nov 22, 2024
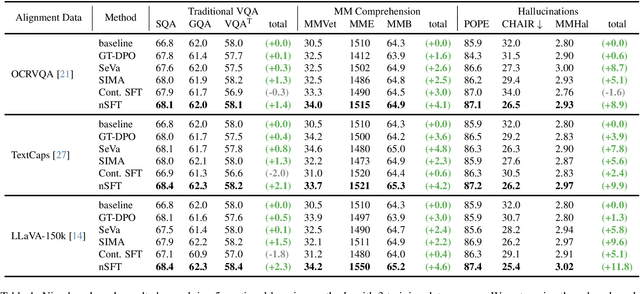
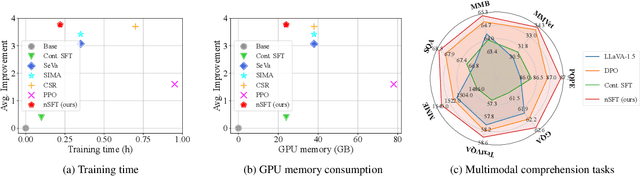
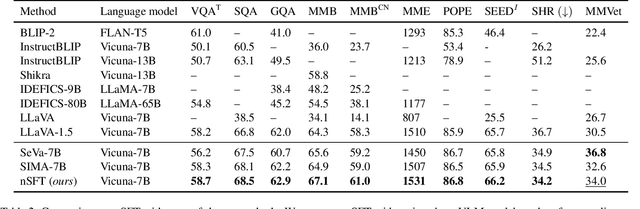
Multimodal RLHF usually happens after supervised finetuning (SFT) stage to continually improve vision-language models' (VLMs) comprehension. Conventional wisdom holds its superiority over continual SFT during this preference alignment stage. In this paper, we observe that the inherent value of multimodal RLHF lies in its negative supervision, the logit of the rejected responses. We thus propose a novel negative supervised finetuning (nSFT) approach that fully excavates these information resided. Our nSFT disentangles this negative supervision in RLHF paradigm, and continually aligns VLMs with a simple SFT loss. This is more memory efficient than multimodal RLHF where 2 (e.g., DPO) or 4 (e.g., PPO) large VLMs are strictly required. The effectiveness of nSFT is rigorously proved by comparing it with various multimodal RLHF approaches, across different dataset sources, base VLMs and evaluation metrics. Besides, fruitful of ablations are provided to support our hypothesis. We hope this paper will stimulate further research to properly align large vision language models.