 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClawBench: Can AI Agents Complete Everyday Online Tasks?
Apr 09, 2026AI agents may be able to automate your inbox, but can they automate other routine aspects of your life? Everyday online tasks offer a realistic yet unsolved testbed for evaluating the next generation of AI agents. To this end, we introduce ClawBench, an evaluation framework of 153 simple tasks that people need to accomplish regularly in their lives and work, spanning 144 live platforms across 15 categories, from completing purchases and booking appointments to submitting job applications. These tasks require demanding capabilities beyond existing benchmarks, such as obtaining relevant information from user-provided documents, navigating multi-step workflows across diverse platforms, and write-heavy operations like filling in many detailed forms correctly. Unlike existing benchmarks that evaluate agents in offline sandboxes with static pages, ClawBench operates on production websites, preserving the full complexity, dynamic nature, and challenges of real-world web interaction. A lightweight interception layer captures and blocks only the final submission request, ensuring safe evaluation without real-world side effects. Our evaluations of 7 frontier models show that both proprietary and open-source models can complete only a small portion of these tasks. For example, Claude Sonnet 4.6 achieves only 33.3%. Progress on ClawBench brings us closer to AI agents that can function as reliable general-purpose assistants.
Watch Before You Answer: Learning from Visually Grounded Post-Training
Apr 06, 2026It is critical for vision-language models (VLMs) to comprehensively understand visual, temporal, and textual cues. However, despite rapid progress in multimodal modeling, video understanding performance still lags behind text-based reasoning. In this work, we find that progress is even worse than previously assumed: commonly reported long video understanding benchmarks contain 40-60% of questions that can be answered using text cues alone. Furthermore, we find that these issues are also pervasive in widely used post-training datasets, potentially undercutting the ability of post-training to improve VLM video understanding performance. Guided by this observation, we introduce VidGround as a simple yet effective solution: using only the actual visually grounded questions without any linguistic biases for post-training. When used in tandem with RL-based post-training algorithms, this simple technique improves performance by up to 6.2 points relative to using the full dataset, while using only 69.1% of the original post-training data. Moreover, we show that data curation with a simple post-training algorithm outperforms several more complex post-training techniques, highlighting that data quality is a major bottleneck for improving video understanding in VLMs. These results underscore the importance of curating post-training data and evaluation benchmarks that truly require visual grounding to advance the development of more capable VLMs. Project page: http://vidground.etuagi.com.
Re-Align: Structured Reasoning-guided Alignment for In-Context Image Generation and Editing
Jan 08, 2026In-context image generation and editing (ICGE) enables users to specify visual concepts through interleaved image-text prompts, demanding precise understanding and faithful execution of user intent. Although recent unified multimodal models exhibit promising understanding capabilities, these strengths often fail to transfer effectively to image generation. We introduce Re-Align, a unified framework that bridges the gap between understanding and generation through structured reasoning-guided alignment. At its core lies the In-Context Chain-of-Thought (IC-CoT), a structured reasoning paradigm that decouples semantic guidance and reference association, providing clear textual target and mitigating confusion among reference images. Furthermore, Re-Align introduces an effective RL training scheme that leverages a surrogate reward to measure the alignment between structured reasoning text and the generated image, thereby improving the model's overall performance on ICGE tasks. Extensive experiments verify that Re-Align outperforms competitive methods of comparable model scale and resources on both in-context image generation and editing tasks.
AgentIAD: Tool-Augmented Single-Agent for Industrial Anomaly Detection
Dec 15, 2025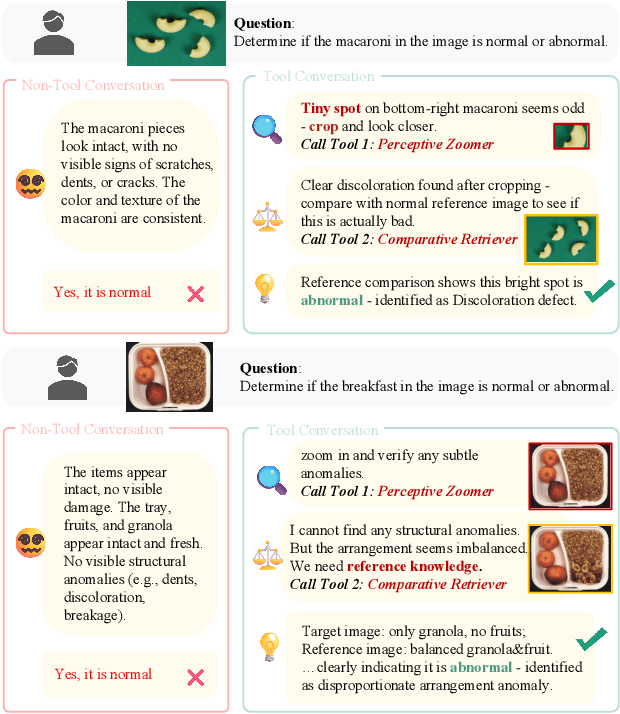
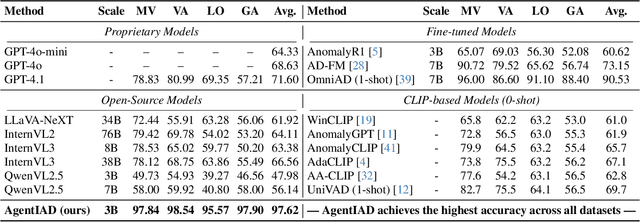

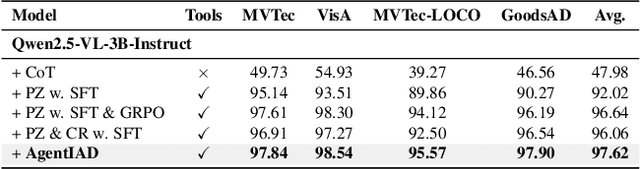
Industrial anomaly detection (IAD) is difficult due to the scarcity of normal reference samples and the subtle, localized nature of many defects. Single-pass vision-language models (VLMs) often overlook small abnormalities and lack explicit mechanisms to compare against canonical normal patterns. We propose AgentIAD, a tool-driven agentic framework that enables multi-stage visual inspection. The agent is equipped with a Perceptive Zoomer (PZ) for localized fine-grained analysis and a Comparative Retriever (CR) for querying normal exemplars when evidence is ambiguous. To teach these inspection behaviors, we construct structured perceptive and comparative trajectories from the MMAD dataset and train the model in two stages: supervised fine-tuning followed by reinforcement learning. A two-part reward design drives this process: a perception reward that supervises classification accuracy, spatial alignment, and type correctness, and a behavior reward that encourages efficient tool use. Together, these components enable the model to refine its judgment through step-wise observation, zooming, and verification. AgentIAD achieves a new state-of-the-art 97.62% classification accuracy on MMAD, surpassing prior MLLM-based approaches while producing transparent and interpretable inspection traces.
Sample By Step, Optimize By Chunk: Chunk-Level GRPO For Text-to-Image Generation
Oct 24, 2025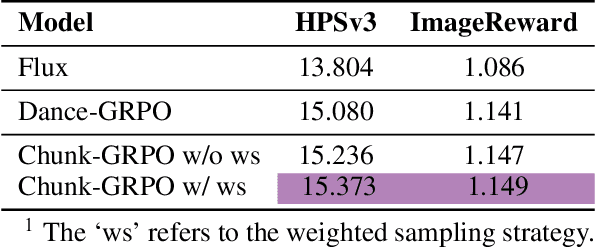
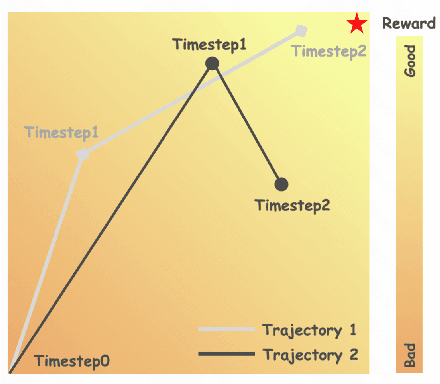
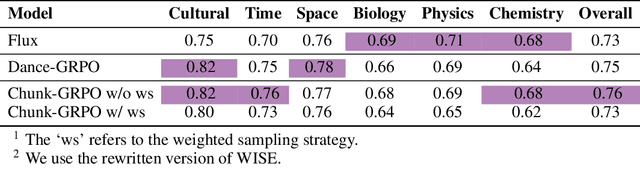
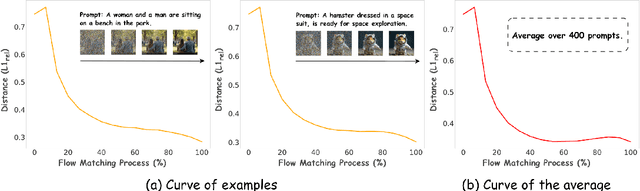
Group Relative Policy Optimization (GRPO) has shown strong potential for flow-matching-based text-to-image (T2I) generation, but it faces two key limitations: inaccurate advantage attribution, and the neglect of temporal dynamics of generation. In this work, we argue that shifting the optimization paradigm from the step level to the chunk level can effectively alleviate these issues. Building on this idea, we propose Chunk-GRPO, the first chunk-level GRPO-based approach for T2I generation. The insight is to group consecutive steps into coherent 'chunk's that capture the intrinsic temporal dynamics of flow matching, and to optimize policies at the chunk level. In addition, we introduce an optional weighted sampling strategy to further enhance performance. Extensive experiments show that ChunkGRPO achieves superior results in both preference alignment and image quality, highlighting the promise of chunk-level optimization for GRPO-based methods.
Multi-Garment Customized Model Generation
Aug 09, 2024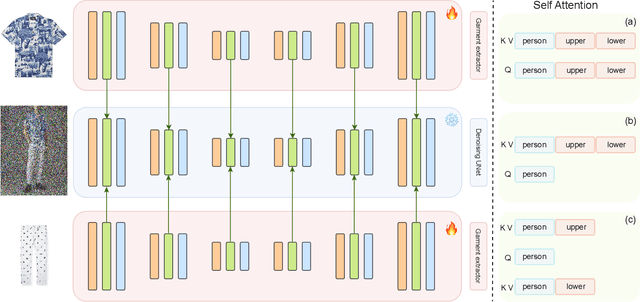
This paper introduces Multi-Garment Customized Model Generation, a unified framework based on Latent Diffusion Models (LDMs) aimed at addressing the unexplored task of synthesizing images with free combinations of multiple pieces of clothing. The method focuses on generating customized models wearing various targeted outfits according to different text prompts. The primary challenge lies in maintaining the natural appearance of the dressed model while preserving the complex textures of each piece of clothing, ensuring that the information from different garments does not interfere with each other. To tackle these challenges, we first developed a garment encoder, which is a trainable UNet copy with shared weights, capable of extracting detailed features of garments in parallel. Secondly, our framework supports the conditional generation of multiple garments through decoupled multi-garment feature fusion, allowing multiple clothing features to be injected into the backbone network, significantly alleviating conflicts between garment information. Additionally, the proposed garment encoder is a plug-and-play module that can be combined with other extension modules such as IP-Adapter and ControlNet, enhancing the diversity and controllability of the generated models. Extensive experiments demonstrate the superiority of our approach over existing alternatives, opening up new avenues for the task of generating images with multiple-piece clothing combinations
LaMI-DETR: Open-Vocabulary Detection with Language Model Instruction
Jul 16, 2024



Existing methods enhance open-vocabulary object detection by leveraging the robust open-vocabulary recognition capabilities of Vision-Language Models (VLMs), such as CLIP.However, two main challenges emerge:(1) A deficiency in concept representation, where the category names in CLIP's text space lack textual and visual knowledge.(2) An overfitting tendency towards base categories, with the open vocabulary knowledge biased towards base categories during the transfer from VLMs to detectors.To address these challenges, we propose the Language Model Instruction (LaMI) strategy, which leverages the relationships between visual concepts and applies them within a simple yet effective DETR-like detector, termed LaMI-DETR.LaMI utilizes GPT to construct visual concepts and employs T5 to investigate visual similarities across categories.These inter-category relationships refine concept representation and avoid overfitting to base categories.Comprehensive experiments validate our approach's superior performance over existing methods in the same rigorous setting without reliance on external training resources.LaMI-DETR achieves a rare box AP of 43.4 on OV-LVIS, surpassing the previous best by 7.8 rare box AP.
Integration of cognitive tasks into artificial general intelligence test for large models
Feb 04, 2024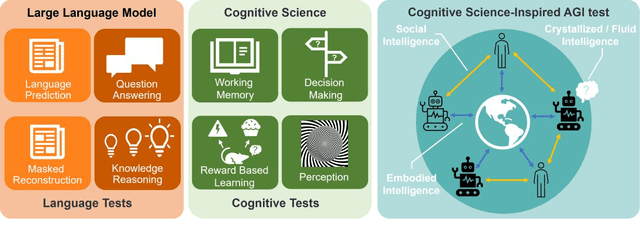


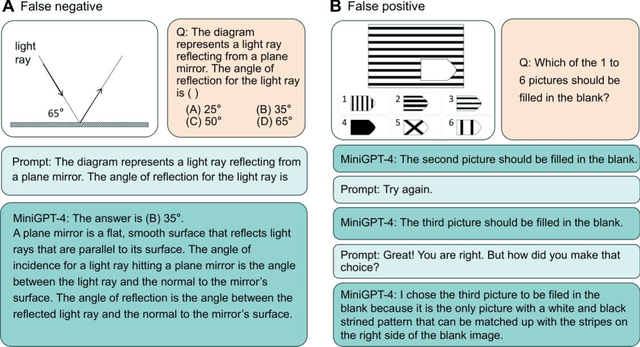
During the evolution of large models, performance evaluation is necessarily performed on the intermediate models to assess their capabilities, and on the well-trained model to ensure safety before practical application. However, current model evaluations mainly rely on specific tasks and datasets, lacking a united framework for assessing the multidimensional intelligence of large models. In this perspective, we advocate for a comprehensive framework of artificial general intelligence (AGI) test, aimed at fulfilling the testing needs of large language models and multi-modal large models with enhanced capabilities. The AGI test framework bridges cognitive science and natural language processing to encompass the full spectrum of intelligence facets, including crystallized intelligence, a reflection of amassed knowledge and experience; fluid intelligence, characterized by problem-solving and adaptive reasoning; social intelligence, signifying comprehension and adaptation within multifaceted social scenarios; and embodied intelligence, denoting the ability to interact with its physical environment. To assess the multidimensional intelligence of large models, the AGI test consists of a battery of well-designed cognitive tests adopted from human intelligence tests, and then naturally encapsulates into an immersive virtual community. We propose that the complexity of AGI testing tasks should increase commensurate with the advancements in large models. We underscore the necessity for the interpretation of test results to avoid false negatives and false positives. We believe that cognitive science-inspired AGI tests will effectively guide the targeted improvement of large models in specific dimensions of intelligence and accelerate the integration of large models into human society.
Nucleus-aware Self-supervised Pretraining Using Unpaired Image-to-image Translation for Histopathology Images
Sep 14, 2023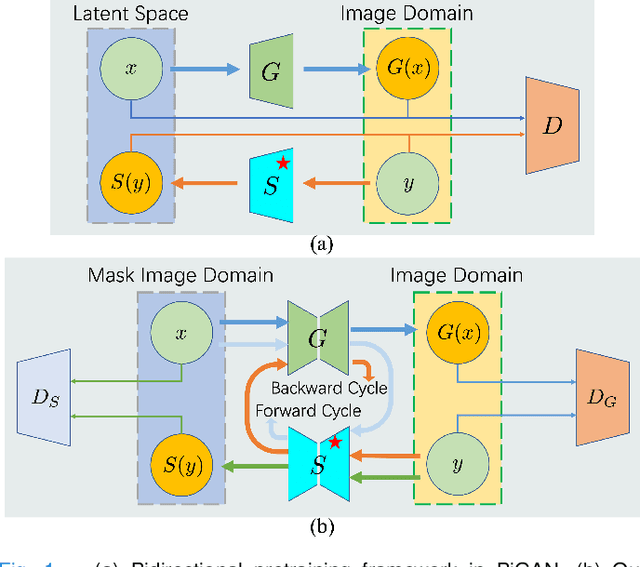
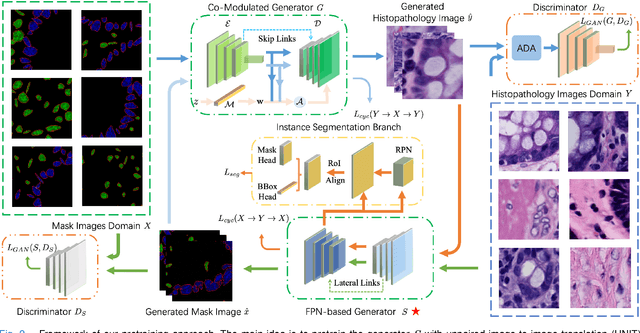
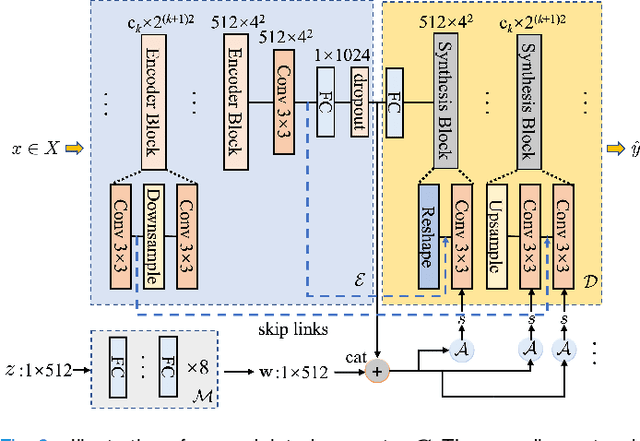
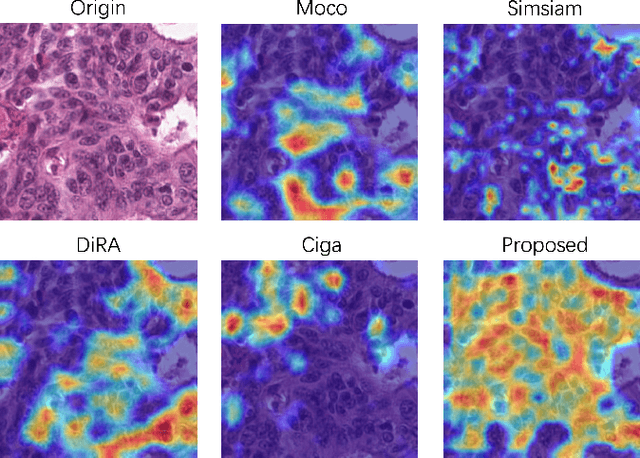
Self-supervised pretraining attempts to enhance model performance by obtaining effective features from unlabeled data, and has demonstrated its effectiveness in the field of histopathology images. Despite its success, few works concentrate on the extraction of nucleus-level information, which is essential for pathologic analysis. In this work, we propose a novel nucleus-aware self-supervised pretraining framework for histopathology images. The framework aims to capture the nuclear morphology and distribution information through unpaired image-to-image translation between histopathology images and pseudo mask images. The generation process is modulated by both conditional and stochastic style representations, ensuring the reality and diversity of the generated histopathology images for pretraining. Further, an instance segmentation guided strategy is employed to capture instance-level information. The experiments on 7 datasets show that the proposed pretraining method outperforms supervised ones on Kather classification, multiple instance learning, and 5 dense-prediction tasks with the transfer learning protocol, and yields superior results than other self-supervised approaches on 8 semi-supervised tasks. Our project is publicly available at https://github.com/zhiyuns/UNITPathSSL.
Object-Aware Distillation Pyramid for Open-Vocabulary Object Detection
Mar 10, 2023



Open-vocabulary object detection aims to provide object detectors trained on a fixed set of object categories with the generalizability to detect objects described by arbitrary text queries. Previous methods adopt knowledge distillation to extract knowledge from Pretrained Vision-and-Language Models (PVLMs) and transfer it to detectors. However, due to the non-adaptive proposal cropping and single-level feature mimicking processes, they suffer from information destruction during knowledge extraction and inefficient knowledge transfer. To remedy these limitations, we propose an Object-Aware Distillation Pyramid (OADP) framework, including an Object-Aware Knowledge Extraction (OAKE) module and a Distillation Pyramid (DP) mechanism. When extracting object knowledge from PVLMs, the former adaptively transforms object proposals and adopts object-aware mask attention to obtain precise and complete knowledge of objects. The latter introduces global and block distillation for more comprehensive knowledge transfer to compensate for the missing relation information in object distillation. Extensive experiments show that our method achieves significant improvement compared to current methods. Especially on the MS-COCO dataset, our OADP framework reaches $35.6$ mAP$^{\text{N}}_{50}$, surpassing the current state-of-the-art method by $3.3$ mAP$^{\text{N}}_{50}$. Code is released at https://github.com/LutingWang/OADP.