 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Realistic Earth-Observation Constellation Scheduling: Benchmark and Methodology
Oct 30, 2025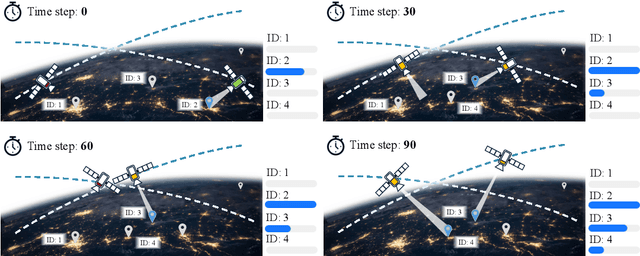
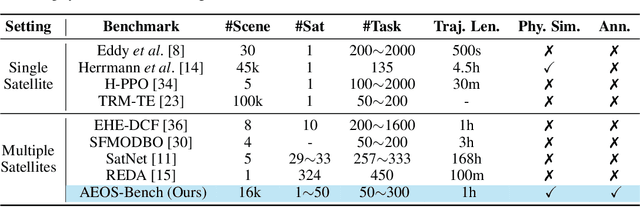
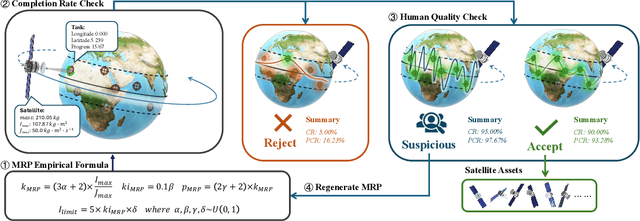
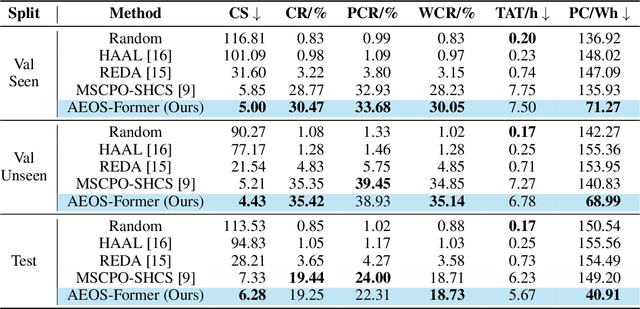
Agile Earth Observation Satellites (AEOSs) constellations offer unprecedented flexibility for monitoring the Earth's surface, but their scheduling remains challenging under large-scale scenarios, dynamic environments, and stringent constraints. Existing methods often simplify these complexities, limiting their real-world performance. We address this gap with a unified framework integrating a standardized benchmark suite and a novel scheduling model. Our benchmark suite, AEOS-Bench, contains $3,907$ finely tuned satellite assets and $16,410$ scenarios. Each scenario features $1$ to $50$ satellites and $50$ to $300$ imaging tasks. These scenarios are generated via a high-fidelity simulation platform, ensuring realistic satellite behavior such as orbital dynamics and resource constraints. Ground truth scheduling annotations are provided for each scenario. To our knowledge, AEOS-Bench is the first large-scale benchmark suite tailored for realistic constellation scheduling. Building upon this benchmark, we introduce AEOS-Former, a Transformer-based scheduling model that incorporates a constraint-aware attention mechanism. A dedicated internal constraint module explicitly models the physical and operational limits of each satellite. Through simulation-based iterative learning, AEOS-Former adapts to diverse scenarios, offering a robust solution for AEOS constellation scheduling. Experimental results demonstrate that AEOS-Former outperforms baseline models in task completion and energy efficiency, with ablation studies highlighting the contribution of each component. Code and data are provided in https://github.com/buaa-colalab/AEOSBench.
Image Understanding Makes for A Good Tokenizer for Image Generation
Nov 07, 2024Abstract Modern image generation (IG) models have been shown to capture rich semantics valuable for image understanding (IU) tasks. However, the potential of IU models to improve IG performance remains uncharted. We address this issue using a token-based IG framework, which relies on effective tokenizers to project images into token sequences. Currently, pixel reconstruction (e.g., VQGAN) dominates the training objective for image tokenizers. In contrast, our approach adopts the feature reconstruction objective, where tokenizers are trained by distilling knowledge from pretrained IU encoders. Comprehensive comparisons indicate that tokenizers with strong IU capabilities achieve superior IG performance across a variety of metrics, datasets, tasks, and proposal networks. Notably, VQ-KD CLIP achieves $4.10$ FID on ImageNet-1k (IN-1k). Visualization suggests that the superiority of VQ-KD can be partly attributed to the rich semantics within the VQ-KD codebook. We further introduce a straightforward pipeline to directly transform IU encoders into tokenizers, demonstrating exceptional effectiveness for IG tasks. These discoveries may energize further exploration into image tokenizer research and inspire the community to reassess the relationship between IU and IG. The code is released at https://github.com/magic-research/vector_quantization.
Knowledge Distillation via Query Selection for Detection Transformer
Sep 10, 2024



Transformers have revolutionized the object detection landscape by introducing DETRs, acclaimed for their simplicity and efficacy. Despite their advantages, the substantial size of these models poses significant challenges for practical deployment, particularly in resource-constrained environments. This paper addresses the challenge of compressing DETR by leveraging knowledge distillation, a technique that holds promise for maintaining model performance while reducing size. A critical aspect of DETRs' performance is their reliance on queries to interpret object representations accurately. Traditional distillation methods often focus exclusively on positive queries, identified through bipartite matching, neglecting the rich information present in hard-negative queries. Our visual analysis indicates that hard-negative queries, focusing on foreground elements, are crucial for enhancing distillation outcomes. To this end, we introduce a novel Group Query Selection strategy, which diverges from traditional query selection in DETR distillation by segmenting queries based on their Generalized Intersection over Union (GIoU) with ground truth objects, thereby uncovering valuable hard-negative queries for distillation. Furthermore, we present the Knowledge Distillation via Query Selection for DETR (QSKD) framework, which incorporates Attention-Guided Feature Distillation (AGFD) and Local Alignment Prediction Distillation (LAPD). These components optimize the distillation process by focusing on the most informative aspects of the teacher model's intermediate features and output. Our comprehensive experimental evaluation of the MS-COCO dataset demonstrates the effectiveness of our approach, significantly improving average precision (AP) across various DETR architectures without incurring substantial computational costs. Specifically, the AP of Conditional DETR ResNet-18 increased from 35.8 to 39.9.
LaMI-DETR: Open-Vocabulary Detection with Language Model Instruction
Jul 16, 2024



Existing methods enhance open-vocabulary object detection by leveraging the robust open-vocabulary recognition capabilities of Vision-Language Models (VLMs), such as CLIP.However, two main challenges emerge:(1) A deficiency in concept representation, where the category names in CLIP's text space lack textual and visual knowledge.(2) An overfitting tendency towards base categories, with the open vocabulary knowledge biased towards base categories during the transfer from VLMs to detectors.To address these challenges, we propose the Language Model Instruction (LaMI) strategy, which leverages the relationships between visual concepts and applies them within a simple yet effective DETR-like detector, termed LaMI-DETR.LaMI utilizes GPT to construct visual concepts and employs T5 to investigate visual similarities across categories.These inter-category relationships refine concept representation and avoid overfitting to base categories.Comprehensive experiments validate our approach's superior performance over existing methods in the same rigorous setting without reliance on external training resources.LaMI-DETR achieves a rare box AP of 43.4 on OV-LVIS, surpassing the previous best by 7.8 rare box AP.
Object-Aware Distillation Pyramid for Open-Vocabulary Object Detection
Mar 10, 2023



Open-vocabulary object detection aims to provide object detectors trained on a fixed set of object categories with the generalizability to detect objects described by arbitrary text queries. Previous methods adopt knowledge distillation to extract knowledge from Pretrained Vision-and-Language Models (PVLMs) and transfer it to detectors. However, due to the non-adaptive proposal cropping and single-level feature mimicking processes, they suffer from information destruction during knowledge extraction and inefficient knowledge transfer. To remedy these limitations, we propose an Object-Aware Distillation Pyramid (OADP) framework, including an Object-Aware Knowledge Extraction (OAKE) module and a Distillation Pyramid (DP) mechanism. When extracting object knowledge from PVLMs, the former adaptively transforms object proposals and adopts object-aware mask attention to obtain precise and complete knowledge of objects. The latter introduces global and block distillation for more comprehensive knowledge transfer to compensate for the missing relation information in object distillation. Extensive experiments show that our method achieves significant improvement compared to current methods. Especially on the MS-COCO dataset, our OADP framework reaches $35.6$ mAP$^{\text{N}}_{50}$, surpassing the current state-of-the-art method by $3.3$ mAP$^{\text{N}}_{50}$. Code is released at https://github.com/LutingWang/OADP.
HEAD: HEtero-Assists Distillation for Heterogeneous Object Detectors
Jul 12, 2022
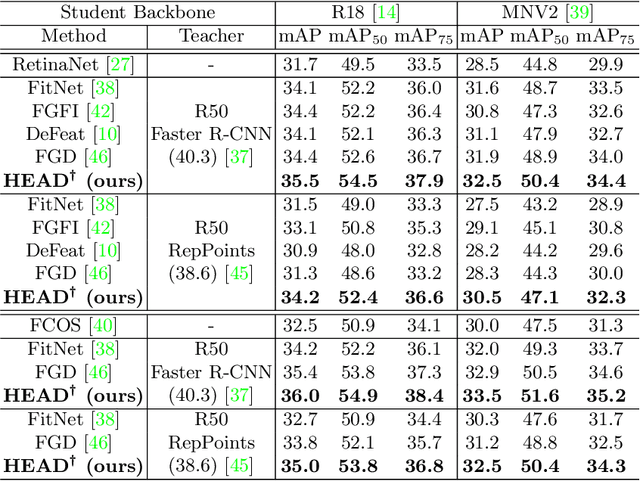
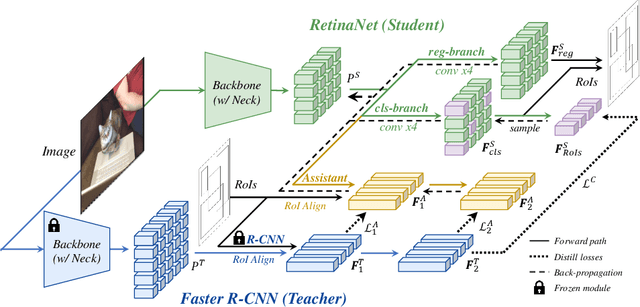
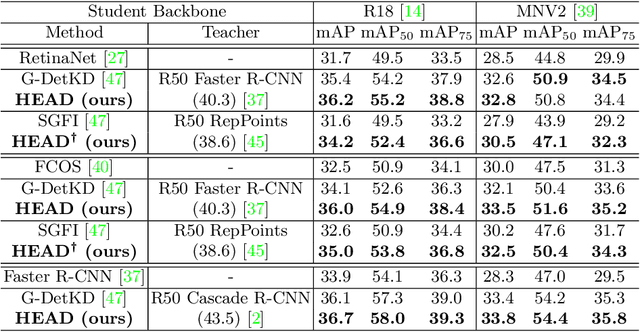
Conventional knowledge distillation (KD) methods for object detection mainly concentrate on homogeneous teacher-student detectors. However, the design of a lightweight detector for deployment is often significantly different from a high-capacity detector. Thus, we investigate KD among heterogeneous teacher-student pairs for a wide application. We observe that the core difficulty for heterogeneous KD (hetero-KD) is the significant semantic gap between the backbone features of heterogeneous detectors due to the different optimization manners. Conventional homogeneous KD (homo-KD) methods suffer from such a gap and are hard to directly obtain satisfactory performance for hetero-KD. In this paper, we propose the HEtero-Assists Distillation (HEAD) framework, leveraging heterogeneous detection heads as assistants to guide the optimization of the student detector to reduce this gap. In HEAD, the assistant is an additional detection head with the architecture homogeneous to the teacher head attached to the student backbone. Thus, a hetero-KD is transformed into a homo-KD, allowing efficient knowledge transfer from the teacher to the student. Moreover, we extend HEAD into a Teacher-Free HEAD (TF-HEAD) framework when a well-trained teacher detector is unavailable. Our method has achieved significant improvement compared to current detection KD methods. For example, on the MS-COCO dataset, TF-HEAD helps R18 RetinaNet achieve 33.9 mAP (+2.2), while HEAD further pushes the limit to 36.2 mAP (+4.5).