 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated Exploration and Sequential Manipulation on Scene Graph with LLM-based Situated Replanning
Feb 04, 2026In partially known environments, robots must combine exploration to gather information with task planning for efficient execution. To address this challenge, we propose EPoG, an Exploration-based sequential manipulation Planning framework on Scene Graphs. EPoG integrates a graph-based global planner with a Large Language Model (LLM)-based situated local planner, continuously updating a belief graph using observations and LLM predictions to represent known and unknown objects. Action sequences are generated by computing graph edit operations between the goal and belief graphs, ordered by temporal dependencies and movement costs. This approach seamlessly combines exploration and sequential manipulation planning. In ablation studies across 46 realistic household scenes and 5 long-horizon daily object transportation tasks, EPoG achieved a success rate of 91.3%, reducing travel distance by 36.1% on average. Furthermore, a physical mobile manipulator successfully executed complex tasks in unknown and dynamic environments, demonstrating EPoG's potential for real-world applications.
From Instruction to Event: Sound-Triggered Mobile Manipulation
Jan 29, 2026Current mobile manipulation research predominantly follows an instruction-driven paradigm, where agents rely on predefined textual commands to execute tasks. However, this setting confines agents to a passive role, limiting their autonomy and ability to react to dynamic environmental events. To address these limitations, we introduce sound-triggered mobile manipulation, where agents must actively perceive and interact with sound-emitting objects without explicit action instructions. To support these tasks, we develop Habitat-Echo, a data platform that integrates acoustic rendering with physical interaction. We further propose a baseline comprising a high-level task planner and low-level policy models to complete these tasks. Extensive experiments show that the proposed baseline empowers agents to actively detect and respond to auditory events, eliminating the need for case-by-case instructions. Notably, in the challenging dual-source scenario, the agent successfully isolates the primary source from overlapping acoustic interference to execute the first interaction, and subsequently proceeds to manipulate the secondary object, verifying the robustness of the baseline.
ACoT-VLA: Action Chain-of-Thought for Vision-Language-Action Models
Jan 16, 2026Vision-Language-Action (VLA) models have emerged as essential generalist robot policies for diverse manipulation tasks, conventionally relying on directly translating multimodal inputs into actions via Vision-Language Model (VLM) embeddings. Recent advancements have introduced explicit intermediary reasoning, such as sub-task prediction (language) or goal image synthesis (vision), to guide action generation. However, these intermediate reasoning are often indirect and inherently limited in their capacity to convey the full, granular information required for precise action execution. Instead, we posit that the most effective form of reasoning is one that deliberates directly in the action space. We introduce Action Chain-of-Thought (ACoT), a paradigm where the reasoning process itself is formulated as a structured sequence of coarse action intents that guide the final policy. In this paper, we propose ACoT-VLA, a novel architecture that materializes the ACoT paradigm. Specifically, we introduce two complementary components: an Explicit Action Reasoner (EAR) and Implicit Action Reasoner (IAR). The former proposes coarse reference trajectories as explicit action-level reasoning steps, while the latter extracts latent action priors from internal representations of multimodal input, co-forming an ACoT that conditions the downstream action head to enable grounded policy learning. Extensive experiments in real-world and simulation environments demonstrate the superiority of our proposed method, which achieves 98.5%, 84.1%, and 47.4% on LIBERO, LIBERO-Plus and VLABench, respectively.
Towards Realistic Earth-Observation Constellation Scheduling: Benchmark and Methodology
Oct 30, 2025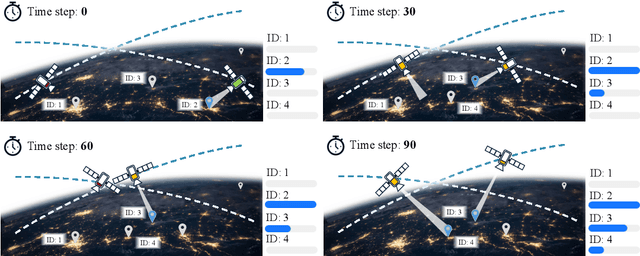
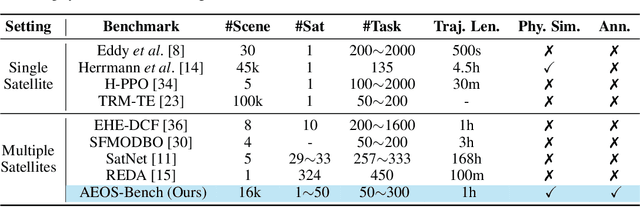
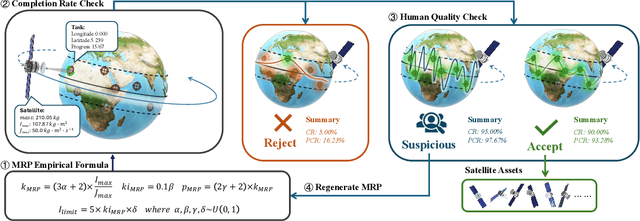
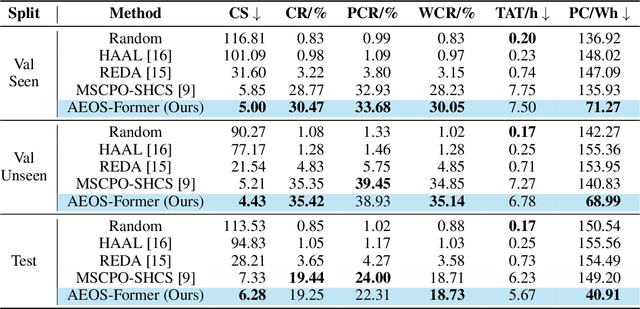
Agile Earth Observation Satellites (AEOSs) constellations offer unprecedented flexibility for monitoring the Earth's surface, but their scheduling remains challenging under large-scale scenarios, dynamic environments, and stringent constraints. Existing methods often simplify these complexities, limiting their real-world performance. We address this gap with a unified framework integrating a standardized benchmark suite and a novel scheduling model. Our benchmark suite, AEOS-Bench, contains $3,907$ finely tuned satellite assets and $16,410$ scenarios. Each scenario features $1$ to $50$ satellites and $50$ to $300$ imaging tasks. These scenarios are generated via a high-fidelity simulation platform, ensuring realistic satellite behavior such as orbital dynamics and resource constraints. Ground truth scheduling annotations are provided for each scenario. To our knowledge, AEOS-Bench is the first large-scale benchmark suite tailored for realistic constellation scheduling. Building upon this benchmark, we introduce AEOS-Former, a Transformer-based scheduling model that incorporates a constraint-aware attention mechanism. A dedicated internal constraint module explicitly models the physical and operational limits of each satellite. Through simulation-based iterative learning, AEOS-Former adapts to diverse scenarios, offering a robust solution for AEOS constellation scheduling. Experimental results demonstrate that AEOS-Former outperforms baseline models in task completion and energy efficiency, with ablation studies highlighting the contribution of each component. Code and data are provided in https://github.com/buaa-colalab/AEOSBench.
MathCanvas: Intrinsic Visual Chain-of-Thought for Multimodal Mathematical Reasoning
Oct 16, 2025While Large Language Models (LLMs) have excelled in textual reasoning, they struggle with mathematical domains like geometry that intrinsically rely on visual aids. Existing approaches to Visual Chain-of-Thought (VCoT) are often limited by rigid external tools or fail to generate the high-fidelity, strategically-timed diagrams necessary for complex problem-solving. To bridge this gap, we introduce MathCanvas, a comprehensive framework designed to endow unified Large Multimodal Models (LMMs) with intrinsic VCoT capabilities for mathematics. Our approach consists of two phases. First, a Visual Manipulation stage pre-trains the model on a novel 15.2M-pair corpus, comprising 10M caption-to-diagram pairs (MathCanvas-Imagen) and 5.2M step-by-step editing trajectories (MathCanvas-Edit), to master diagram generation and editing. Second, a Strategic Visual-Aided Reasoning stage fine-tunes the model on MathCanvas-Instruct, a new 219K-example dataset of interleaved visual-textual reasoning paths, teaching it when and how to leverage visual aids. To facilitate rigorous evaluation, we introduce MathCanvas-Bench, a challenging benchmark with 3K problems that require models to produce interleaved visual-textual solutions. Our model, BAGEL-Canvas, trained under this framework, achieves an 86% relative improvement over strong LMM baselines on MathCanvas-Bench, demonstrating excellent generalization to other public math benchmarks. Our work provides a complete toolkit-framework, datasets, and benchmark-to unlock complex, human-like visual-aided reasoning in LMMs. Project Page: https://mathcanvas.github.io/
Factuality Matters: When Image Generation and Editing Meet Structured Visuals
Oct 06, 2025While modern visual generation models excel at creating aesthetically pleasing natural images, they struggle with producing or editing structured visuals like charts, diagrams, and mathematical figures, which demand composition planning, text rendering, and multimodal reasoning for factual fidelity. To address this, we present the first comprehensive, systematic investigation of this domain, encompassing data construction, model training, and an evaluation benchmark. First, we construct a large-scale dataset of 1.3 million high-quality structured image pairs derived from executable drawing programs and augmented with chain-of-thought reasoning annotations. Building on it, we train a unified model that integrates a VLM with FLUX.1 Kontext via a lightweight connector for enhanced multimodal understanding. A three-stage training curriculum enables progressive feature alignment, knowledge infusion, and reasoning-augmented generation, further boosted by an external reasoner at inference time. Finally, we introduce StructBench, a novel benchmark for generation and editing with over 1,700 challenging instances, and an accompanying evaluation metric, StructScore, which employs a multi-round Q\&A protocol to assess fine-grained factual accuracy. Evaluations of 15 models reveal that even leading closed-source systems remain far from satisfactory. Our model attains strong editing performance, and inference-time reasoning yields consistent gains across diverse architectures. By releasing the dataset, model, and benchmark, we aim to advance unified multimodal foundations for structured visuals.
FLUX-Reason-6M & PRISM-Bench: A Million-Scale Text-to-Image Reasoning Dataset and Comprehensive Benchmark
Sep 11, 2025The advancement of open-source text-to-image (T2I) models has been hindered by the absence of large-scale, reasoning-focused datasets and comprehensive evaluation benchmarks, resulting in a performance gap compared to leading closed-source systems. To address this challenge, We introduce FLUX-Reason-6M and PRISM-Bench (Precise and Robust Image Synthesis Measurement Benchmark). FLUX-Reason-6M is a massive dataset consisting of 6 million high-quality FLUX-generated images and 20 million bilingual (English and Chinese) descriptions specifically designed to teach complex reasoning. The image are organized according to six key characteristics: Imagination, Entity, Text rendering, Style, Affection, and Composition, and design explicit Generation Chain-of-Thought (GCoT) to provide detailed breakdowns of image generation steps. The whole data curation takes 15,000 A100 GPU days, providing the community with a resource previously unattainable outside of large industrial labs. PRISM-Bench offers a novel evaluation standard with seven distinct tracks, including a formidable Long Text challenge using GCoT. Through carefully designed prompts, it utilizes advanced vision-language models for nuanced human-aligned assessment of prompt-image alignment and image aesthetics. Our extensive evaluation of 19 leading models on PRISM-Bench reveals critical performance gaps and highlights specific areas requiring improvement. Our dataset, benchmark, and evaluation code are released to catalyze the next wave of reasoning-oriented T2I generation. Project page: https://flux-reason-6m.github.io/ .
AeroDuo: Aerial Duo for UAV-based Vision and Language Navigation
Aug 21, 2025Aerial Vision-and-Language Navigation (VLN) is an emerging task that enables Unmanned Aerial Vehicles (UAVs) to navigate outdoor environments using natural language instructions and visual cues. However, due to the extended trajectories and complex maneuverability of UAVs, achieving reliable UAV-VLN performance is challenging and often requires human intervention or overly detailed instructions. To harness the advantages of UAVs' high mobility, which could provide multi-grained perspectives, while maintaining a manageable motion space for learning, we introduce a novel task called Dual-Altitude UAV Collaborative VLN (DuAl-VLN). In this task, two UAVs operate at distinct altitudes: a high-altitude UAV responsible for broad environmental reasoning, and a low-altitude UAV tasked with precise navigation. To support the training and evaluation of the DuAl-VLN, we construct the HaL-13k, a dataset comprising 13,838 collaborative high-low UAV demonstration trajectories, each paired with target-oriented language instructions. This dataset includes both unseen maps and an unseen object validation set to systematically evaluate the model's generalization capabilities across novel environments and unfamiliar targets. To consolidate their complementary strengths, we propose a dual-UAV collaborative VLN framework, AeroDuo, where the high-altitude UAV integrates a multimodal large language model (Pilot-LLM) for target reasoning, while the low-altitude UAV employs a lightweight multi-stage policy for navigation and target grounding. The two UAVs work collaboratively and only exchange minimal coordinate information to ensure efficiency.
Genie Envisioner: A Unified World Foundation Platform for Robotic Manipulation
Aug 07, 2025
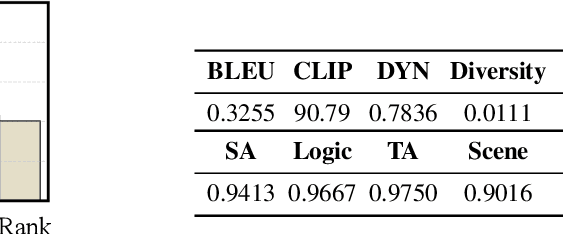

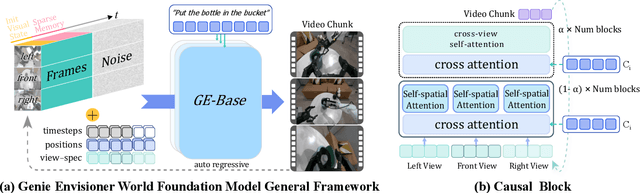
We introduce Genie Envisioner (GE), a unified world foundation platform for robotic manipulation that integrates policy learning, evaluation, and simulation within a single video-generative framework. At its core, GE-Base is a large-scale, instruction-conditioned video diffusion model that captures the spatial, temporal, and semantic dynamics of real-world robotic interactions in a structured latent space. Built upon this foundation, GE-Act maps latent representations to executable action trajectories through a lightweight, flow-matching decoder, enabling precise and generalizable policy inference across diverse embodiments with minimal supervision. To support scalable evaluation and training, GE-Sim serves as an action-conditioned neural simulator, producing high-fidelity rollouts for closed-loop policy development. The platform is further equipped with EWMBench, a standardized benchmark suite measuring visual fidelity, physical consistency, and instruction-action alignment. Together, these components establish Genie Envisioner as a scalable and practical foundation for instruction-driven, general-purpose embodied intelligence. All code, models, and benchmarks will be released publicly.
DOMR: Establishing Cross-View Segmentation via Dense Object Matching
Aug 06, 2025Cross-view object correspondence involves matching objects between egocentric (first-person) and exocentric (third-person) views. It is a critical yet challenging task for visual understanding. In this work, we propose the Dense Object Matching and Refinement (DOMR) framework to establish dense object correspondences across views. The framework centers around the Dense Object Matcher (DOM) module, which jointly models multiple objects. Unlike methods that directly match individual object masks to image features, DOM leverages both positional and semantic relationships among objects to find correspondences. DOM integrates a proposal generation module with a dense matching module that jointly encodes visual, spatial, and semantic cues, explicitly constructing inter-object relationships to achieve dense matching among objects. Furthermore, we combine DOM with a mask refinement head designed to improve the completeness and accuracy of the predicted masks, forming the complete DOMR framework. Extensive evaluations on the Ego-Exo4D benchmark demonstrate that our approach achieves state-of-the-art performance with a mean IoU of 49.7% on Ego$\to$Exo and 55.2% on Exo$\to$Ego. These results outperform those of previous methods by 5.8% and 4.3%, respectively, validating the effectiveness of our integrated approach for cross-view understanding.