 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Static Evaluation: Co-Evolutionary Mechanisms for LLM-Driven Strategy Evolution in Adversarial Games
Jun 09, 2026Recent advances in LLM-driven code evolution have enabled automated discovery by iteratively generating and improving programs. However, applying these methods to adversarial multi-agent games introduces a fundamental challenge: the evaluation landscape shifts as strategies improve, causing fixed evaluators to become unreliable and evolution to stagnate. We propose three mechanisms to address this challenge: evaluator co-evolution, which incorporates discovered champions into the opponent pool; hierarchical deep evaluation, which replaces noisy few-game scores with statistically reliable assessments; and weakness pressure, which dynamically up-weights the most difficult opponents to break through plateaus. We implement these mechanisms within FAMOU, a framework built upon the same foundation-model code-evolution paradigm as OpenEvolve and ShinkaEvolve. On the MCTF 2026 3v3 maritime capture-the-flag task, FAMOU consistently outperforms both baselines under two backbone LLMs, achieving the highest combined score (0.526) and the best generalization to unseen opponents (61.7% win rate), while ablations confirm that each mechanism contributes to performance. Notably, the LLM mutation process generates tactical structures entirely absent from the seed strategies -- including lookahead search and adaptive interception -- demonstrating that code-level evolution can produce nontrivial algorithmic innovations in adversarial settings. The FAMOU-evolved strategy further achieved 1st place in the hardware round-robin and 3rd in simulation at the AAMAS 2026 MCTF Competition, validating its real-world transferability. The optimized implementation and corresponding evaluation codes developed through our evolutionary process are available at: https://github.com/1xiangliu1/FAMOU-CoEvo
BiCoord: A Bimanual Manipulation Benchmark towards Long-Horizon Spatial-Temporal Coordination
Apr 07, 2026Bimanual manipulation, i.e., the coordinated use of two robotic arms to complete tasks, is essential for achieving human-level dexterity in robotics. Recent simulation benchmarks, e.g., RoboTwin and RLBench2, have advanced data-driven learning for bimanual manipulation. However, existing tasks are short-horizon and only loosely coordinated, failing to capture the spatial-temporal coupling inherent in real-world bimanual behaviors. To address this gap, we introduce BiCoord, a benchmark for long-horizon and tightly coordinated bimanual manipulation. Specifically, BiCoord comprises diverse tasks that require continuous inter-arm dependency and dynamic role exchange across multiple sub-goals. Also, we propose a suite of quantitative metrics that evaluate coordination from temporal, spatial, and spatial-temporal perspectives, enabling systematic measurement of bimanual cooperation. Experimental results show that representative manipulation policies, e.g., DP, RDT, Pi0, and OpenVLA-OFT, struggle with long-duration and highly coupled tasks, revealing fundamental challenges in achieving long-horizon and tight coordination tasks. We hope BiCoord can serve as a foundation for studying long-horizon cooperative manipulation and inspire future research on coordination-aware robotic learning. All datasets, codes and supplements could be found at https://buaa-colalab.github.io/BiCoord/.
SilLang: Improving Gait Recognition with Silhouette Language Encoding
Mar 25, 2026Gait silhouettes, which can be encoded into binary gait codes, are widely adopted to representing motion patterns of pedestrian. Recent approaches commonly leverage visual backbones to encode gait silhouettes, achieving successful performance. However, they primarily focus on continuous visual features, overlooking the discrete nature of binary silhouettes that inherently share a discrete encoding space with natural language. Large Language Models (LLMs) have demonstrated exceptional capability in extracting discriminative features from discrete sequences and modeling long-range dependencies, highlighting their potential to capture temporal motion patterns by identifying subtle variations. Motivated by these observations, we explore bridging binary gait silhouettes and natural language within a binary encoding space. However, the encoding spaces of text tokens and binary gait silhouettes remain misaligned, primarily due to differences in token frequency and density. To address this issue, we propose the Contour-Velocity Tokenizer, which encodes binary gait silhouettes while reshaping their distribution to better align with the text token space. We then establish a dual-branch framework termed Silhouette Language Model, which enhances visual silhouettes by integrating discrete linguistic embeddings derived from LLMs. Implemented on mainstream gait backbones, SilLang consistently improves state-of-the-art methods across SUSTech1K, GREW, and Gait3D.
A Blueprint for Self-Evolving Coding Agents in Vehicle Aerodynamic Drag Prediction
Mar 23, 2026High-fidelity vehicle drag evaluation is constrained less by solver runtime than by workflow friction: geometry cleanup, meshing retries, queue contention, and reproducibility failures across teams. We present a contract-centric blueprint for self-evolving coding agents that discover executable surrogate pipelines for predicting drag coefficient $C_d$ under industrial constraints. The method formulates surrogate discovery as constrained optimization over programs, not static model instances, and combines Famou-Agent-style evaluator feedback with population-based island evolution, structured mutations (data, model, loss, and split policies), and multi-objective selection balancing ranking quality, stability, and cost. A hard evaluation contract enforces leakage prevention, deterministic replay, multi-seed robustness, and resource budgets before any candidate is admitted. Across eight anonymized evolutionary operators, the best system reaches a Combined Score of 0.9335 with sign-accuracy 0.9180, while trajectory and ablation analyses show that adaptive sampling and island migration are primary drivers of convergence quality. The deployment model is explicitly ``screen-and-escalate'': surrogates provide high-throughput ranking for design exploration, but low-confidence or out-of-distribution cases are automatically escalated to high-fidelity CFD. The resulting contribution is an auditable, reusable workflow for accelerating aerodynamic design iteration while preserving decision-grade reliability, governance traceability, and safety boundaries.
QianfanHuijin Technical Report: A Novel Multi-Stage Training Paradigm for Finance Industrial LLMs
Dec 30, 2025Domain-specific enhancement of Large Language Models (LLMs) within the financial context has long been a focal point of industrial application. While previous models such as BloombergGPT and Baichuan-Finance primarily focused on knowledge enhancement, the deepening complexity of financial services has driven a growing demand for models that possess not only domain knowledge but also robust financial reasoning and agentic capabilities. In this paper, we present QianfanHuijin, a financial domain LLM, and propose a generalizable multi-stage training paradigm for industrial model enhancement. Our approach begins with Continual Pre-training (CPT) on financial corpora to consolidate the knowledge base. This is followed by a fine-grained Post-training pipeline designed with increasing specificity: starting with Financial SFT, progressing to Finance Reasoning RL and Finance Agentic RL, and culminating in General RL aligned with real-world business scenarios. Empirical results demonstrate that QianfanHuijin achieves superior performance across various authoritative financial benchmarks. Furthermore, ablation studies confirm that the targeted Reasoning RL and Agentic RL stages yield significant gains in their respective capabilities. These findings validate our motivation and suggest that this fine-grained, progressive post-training methodology is poised to become a mainstream paradigm for various industrial-enhanced LLMs.
The FM Agent
Oct 30, 2025Large language models (LLMs) are catalyzing the development of autonomous AI research agents for scientific and engineering discovery. We present FM Agent, a novel and general-purpose multi-agent framework that leverages a synergistic combination of LLM-based reasoning and large-scale evolutionary search to address complex real-world challenges. The core of FM Agent integrates several key innovations: 1) a cold-start initialization phase incorporating expert guidance, 2) a novel evolutionary sampling strategy for iterative optimization, 3) domain-specific evaluators that combine correctness, effectiveness, and LLM-supervised feedback, and 4) a distributed, asynchronous execution infrastructure built on Ray. Demonstrating broad applicability, our system has been evaluated across diverse domains, including operations research, machine learning, GPU kernel optimization, and classical mathematical problems. FM Agent reaches state-of-the-art results autonomously, without human interpretation or tuning -- 1976.3 on ALE-Bench (+5.2\%), 43.56\% on MLE-Bench (+4.0pp), up to 20x speedups on KernelBench, and establishes new state-of-the-art(SOTA) results on several classical mathematical problems. Beyond academic benchmarks, FM Agent shows considerable promise for both large-scale enterprise R\&D workflows and fundamental scientific research, where it can accelerate innovation, automate complex discovery processes, and deliver substantial engineering and scientific advances with broader societal impact.
OctoNav: Towards Generalist Embodied Navigation
Jun 11, 2025Embodied navigation stands as a foundation pillar within the broader pursuit of embodied AI. However, previous navigation research is divided into different tasks/capabilities, e.g., ObjNav, ImgNav and VLN, where they differ in task objectives and modalities, making datasets and methods are designed individually. In this work, we take steps toward generalist navigation agents, which can follow free-form instructions that include arbitrary compounds of multi-modal and multi-capability. To achieve this, we propose a large-scale benchmark and corresponding method, termed OctoNav-Bench and OctoNav-R1. Specifically, OctoNav-Bench features continuous environments and is constructed via a designed annotation pipeline. We thoroughly craft instruction-trajectory pairs, where instructions are diverse in free-form with arbitrary modality and capability. Also, we construct a Think-Before-Action (TBA-CoT) dataset within OctoNav-Bench to provide the thinking process behind actions. For OctoNav-R1, we build it upon MLLMs and adapt it to a VLA-type model, which can produce low-level actions solely based on 2D visual observations. Moreover, we design a Hybrid Training Paradigm (HTP) that consists of three stages, i.e., Action-/TBA-SFT, Nav-GPRO, and Online RL stages. Each stage contains specifically designed learning policies and rewards. Importantly, for TBA-SFT and Nav-GRPO designs, we are inspired by the OpenAI-o1 and DeepSeek-R1, which show impressive reasoning ability via thinking-before-answer. Thus, we aim to investigate how to achieve thinking-before-action in the embodied navigation field, to improve model's reasoning ability toward generalists. Specifically, we propose TBA-SFT to utilize the TBA-CoT dataset to fine-tune the model as a cold-start phrase and then leverage Nav-GPRO to improve its thinking ability. Finally, OctoNav-R1 shows superior performance compared with previous methods.
CodeJudge-Eval: Can Large Language Models be Good Judges in Code Understanding?
Aug 20, 2024



Recent advancements in large language models (LLMs) have showcased impressive code generation capabilities, primarily evaluated through language-to-code benchmarks. However, these benchmarks may not fully capture a model's code understanding abilities. We introduce CodeJudge-Eval (CJ-Eval), a novel benchmark designed to assess LLMs' code understanding abilities from the perspective of code judging rather than code generation. CJ-Eval challenges models to determine the correctness of provided code solutions, encompassing various error types and compilation issues. By leveraging a diverse set of problems and a fine-grained judging system, CJ-Eval addresses the limitations of traditional benchmarks, including the potential memorization of solutions. Evaluation of 12 well-known LLMs on CJ-Eval reveals that even state-of-the-art models struggle, highlighting the benchmark's ability to probe deeper into models' code understanding abilities. Our benchmark will be available at \url{https://github.com/CodeLLM-Research/CodeJudge-Eval}.
GLGait: A Global-Local Temporal Receptive Field Network for Gait Recognition in the Wild
Aug 13, 2024



Gait recognition has attracted increasing attention from academia and industry as a human recognition technology from a distance in non-intrusive ways without requiring cooperation. Although advanced methods have achieved impressive success in lab scenarios, most of them perform poorly in the wild. Recently, some Convolution Neural Networks (ConvNets) based methods have been proposed to address the issue of gait recognition in the wild. However, the temporal receptive field obtained by convolution operations is limited for long gait sequences. If directly replacing convolution blocks with visual transformer blocks, the model may not enhance a local temporal receptive field, which is important for covering a complete gait cycle. To address this issue, we design a Global-Local Temporal Receptive Field Network (GLGait). GLGait employs a Global-Local Temporal Module (GLTM) to establish a global-local temporal receptive field, which mainly consists of a Pseudo Global Temporal Self-Attention (PGTA) and a temporal convolution operation. Specifically, PGTA is used to obtain a pseudo global temporal receptive field with less memory and computation complexity compared with a multi-head self-attention (MHSA). The temporal convolution operation is used to enhance the local temporal receptive field. Besides, it can also aggregate pseudo global temporal receptive field to a true holistic temporal receptive field. Furthermore, we also propose a Center-Augmented Triplet Loss (CTL) in GLGait to reduce the intra-class distance and expand the positive samples in the training stage. Extensive experiments show that our method obtains state-of-the-art results on in-the-wild datasets, $i.e.$, Gait3D and GREW. The code is available at https://github.com/bgdpgz/GLGait.
RealGait: Gait Recognition for Person Re-Identification
Jan 13, 2022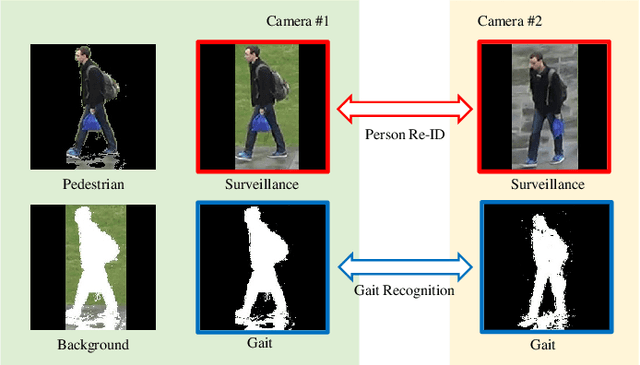
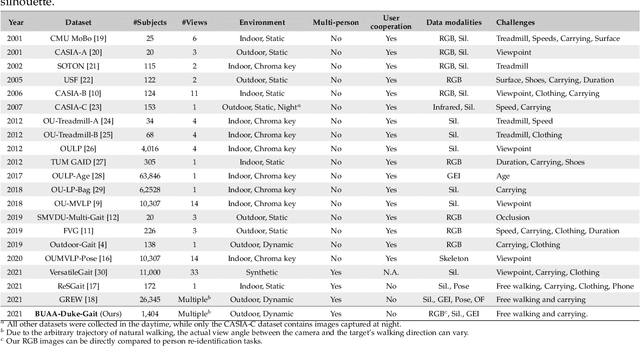


Human gait is considered a unique biometric identifier which can be acquired in a covert manner at a distance. However, models trained on existing public domain gait datasets which are captured in controlled scenarios lead to drastic performance decline when applied to real-world unconstrained gait data. On the other hand, video person re-identification techniques have achieved promising performance on large-scale publicly available datasets. Given the diversity of clothing characteristics, clothing cue is not reliable for person recognition in general. So, it is actually not clear why the state-of-the-art person re-identification methods work as well as they do. In this paper, we construct a new gait dataset by extracting silhouettes from an existing video person re-identification challenge which consists of 1,404 persons walking in an unconstrained manner. Based on this dataset, a consistent and comparative study between gait recognition and person re-identification can be carried out. Given that our experimental results show that current gait recognition approaches designed under data collected in controlled scenarios are inappropriate for real surveillance scenarios, we propose a novel gait recognition method, called RealGait. Our results suggest that recognizing people by their gait in real surveillance scenarios is feasible and the underlying gait pattern is probably the true reason why video person re-idenfification works in practice.