 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWill You Ever Become Popular? Learning to Predict Virality of Dance Clips
Nov 06, 2021
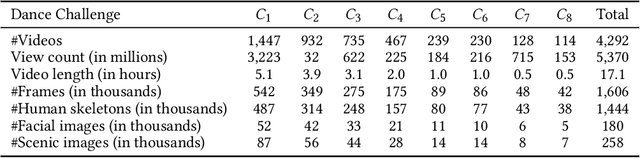
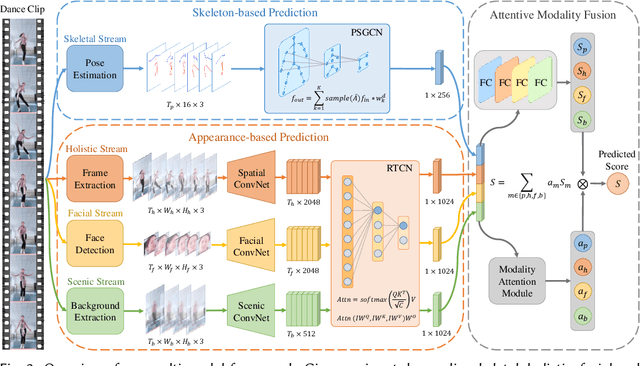
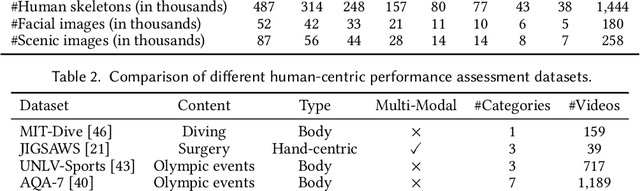
Dance challenges are going viral in video communities like TikTok nowadays. Once a challenge becomes popular, thousands of short-form videos will be uploaded in merely a couple of days. Therefore, virality prediction from dance challenges is of great commercial value and has a wide range of applications, such as smart recommendation and popularity promotion. In this paper, a novel multi-modal framework which integrates skeletal, holistic appearance, facial and scenic cues is proposed for comprehensive dance virality prediction. To model body movements, we propose a pyramidal skeleton graph convolutional network (PSGCN) which hierarchically refines spatio-temporal skeleton graphs. Meanwhile, we introduce a relational temporal convolutional network (RTCN) to exploit appearance dynamics with non-local temporal relations. An attentive fusion approach is finally proposed to adaptively aggregate predictions from different modalities. To validate our method, we introduce a large-scale viral dance video (VDV) dataset, which contains over 4,000 dance clips of eight viral dance challenges. Extensive experiments on the VDV dataset demonstrate the efficacy of our model. Extensive experiments on the VDV dataset well demonstrate the effectiveness of our approach. Furthermore, we show that short video applications like multi-dimensional recommendation and action feedback can be derived from our model.
Linguistic Structure Guided Context Modeling for Referring Image Segmentation
Oct 05, 2020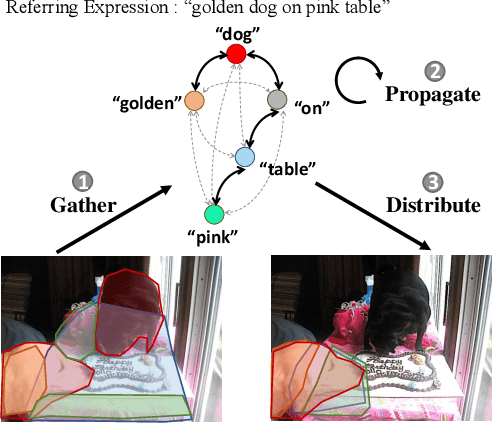
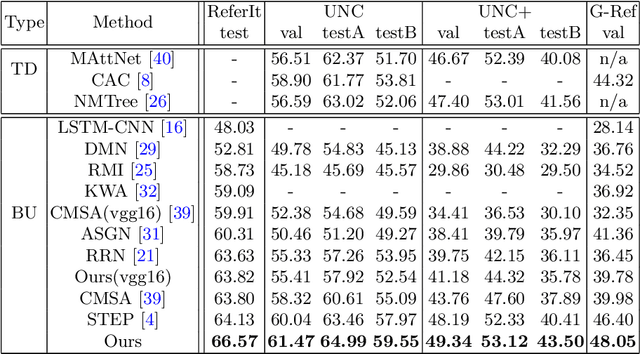
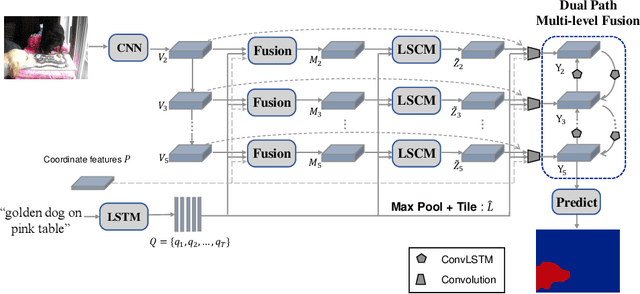
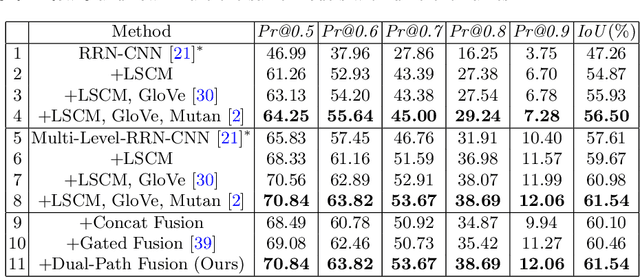
Referring image segmentation aims to predict the foreground mask of the object referred by a natural language sentence. Multimodal context of the sentence is crucial to distinguish the referent from the background. Existing methods either insufficiently or redundantly model the multimodal context. To tackle this problem, we propose a "gather-propagate-distribute" scheme to model multimodal context by cross-modal interaction and implement this scheme as a novel Linguistic Structure guided Context Modeling (LSCM) module. Our LSCM module builds a Dependency Parsing Tree suppressed Word Graph (DPT-WG) which guides all the words to include valid multimodal context of the sentence while excluding disturbing ones through three steps over the multimodal feature, i.e., gathering, constrained propagation and distributing. Extensive experiments on four benchmarks demonstrate that our method outperforms all the previous state-of-the-arts.