 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealGait: Gait Recognition for Person Re-Identification
Jan 13, 2022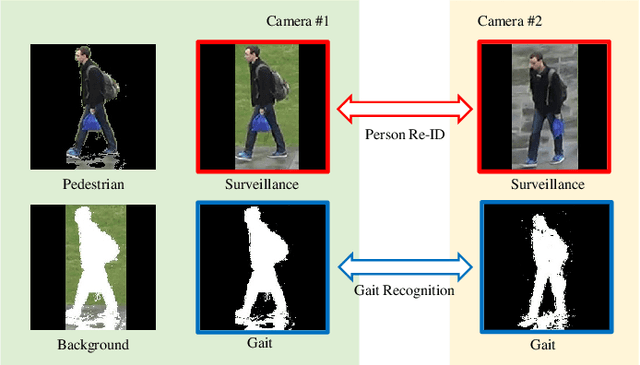
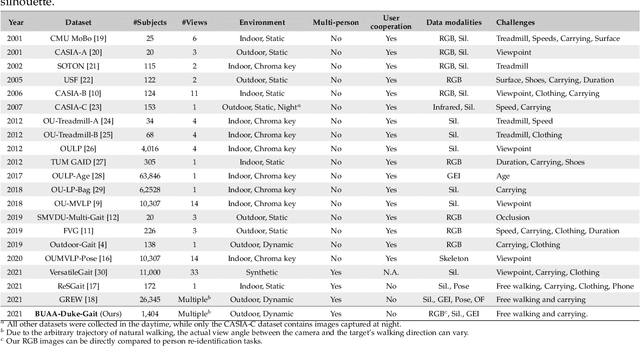


Human gait is considered a unique biometric identifier which can be acquired in a covert manner at a distance. However, models trained on existing public domain gait datasets which are captured in controlled scenarios lead to drastic performance decline when applied to real-world unconstrained gait data. On the other hand, video person re-identification techniques have achieved promising performance on large-scale publicly available datasets. Given the diversity of clothing characteristics, clothing cue is not reliable for person recognition in general. So, it is actually not clear why the state-of-the-art person re-identification methods work as well as they do. In this paper, we construct a new gait dataset by extracting silhouettes from an existing video person re-identification challenge which consists of 1,404 persons walking in an unconstrained manner. Based on this dataset, a consistent and comparative study between gait recognition and person re-identification can be carried out. Given that our experimental results show that current gait recognition approaches designed under data collected in controlled scenarios are inappropriate for real surveillance scenarios, we propose a novel gait recognition method, called RealGait. Our results suggest that recognizing people by their gait in real surveillance scenarios is feasible and the underlying gait pattern is probably the true reason why video person re-idenfification works in practice.
Will You Ever Become Popular? Learning to Predict Virality of Dance Clips
Nov 06, 2021
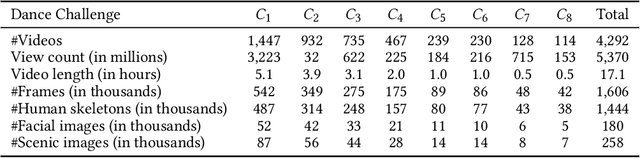
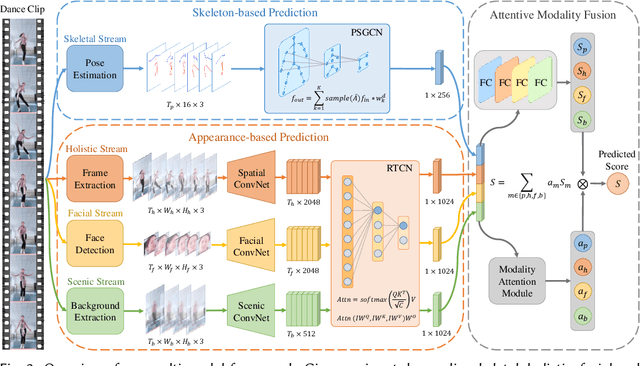
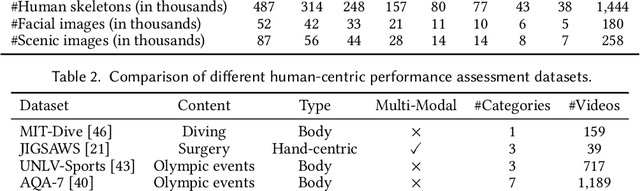
Dance challenges are going viral in video communities like TikTok nowadays. Once a challenge becomes popular, thousands of short-form videos will be uploaded in merely a couple of days. Therefore, virality prediction from dance challenges is of great commercial value and has a wide range of applications, such as smart recommendation and popularity promotion. In this paper, a novel multi-modal framework which integrates skeletal, holistic appearance, facial and scenic cues is proposed for comprehensive dance virality prediction. To model body movements, we propose a pyramidal skeleton graph convolutional network (PSGCN) which hierarchically refines spatio-temporal skeleton graphs. Meanwhile, we introduce a relational temporal convolutional network (RTCN) to exploit appearance dynamics with non-local temporal relations. An attentive fusion approach is finally proposed to adaptively aggregate predictions from different modalities. To validate our method, we introduce a large-scale viral dance video (VDV) dataset, which contains over 4,000 dance clips of eight viral dance challenges. Extensive experiments on the VDV dataset demonstrate the efficacy of our model. Extensive experiments on the VDV dataset well demonstrate the effectiveness of our approach. Furthermore, we show that short video applications like multi-dimensional recommendation and action feedback can be derived from our model.
Video Person Re-identification using Attribute-enhanced Features
Aug 16, 2021
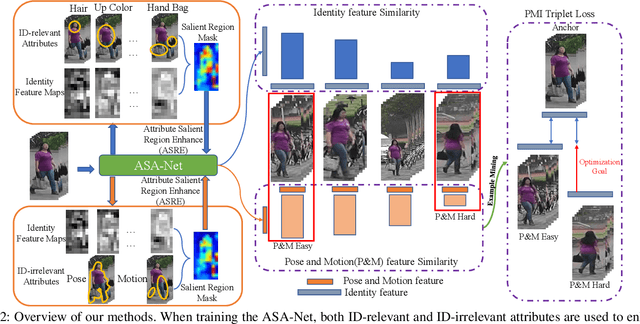
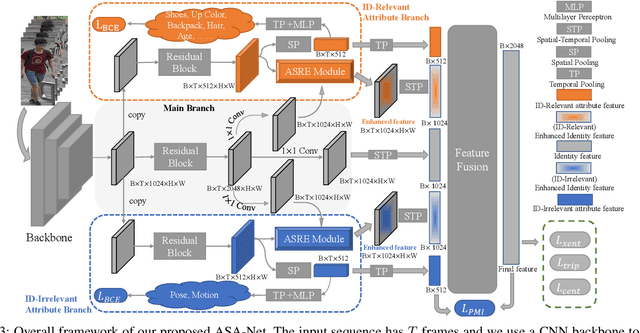
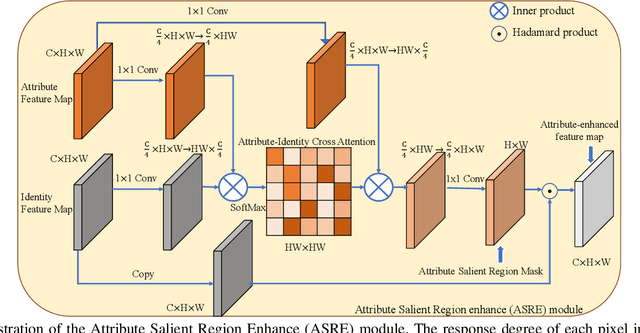
Video-based person re-identification (Re-ID) which aims to associate people across non-overlapping cameras using surveillance video is a challenging task. Pedestrian attribute, such as gender, age and clothing characteristics contains rich and supplementary information but is less explored in video person Re-ID. In this work, we propose a novel network architecture named Attribute Salience Assisted Network (ASA-Net) for attribute-assisted video person Re-ID, which achieved considerable improvement to existing works by two methods.First, to learn a better separation of the target from background, we propose to learn the visual attention from middle-level attribute instead of high-level identities. The proposed Attribute Salient Region Enhance (ASRE) module can attend more accurately on the body of pedestrian. Second, we found that many identity-irrelevant but object or subject-relevant factors like the view angle and movement of the target pedestrian can greatly influence the two dimensional appearance of a pedestrian. This problem can be mitigated by investigating both identity-relevant and identity-irrelevant attributes via a novel triplet loss which is referred as the Pose~\&~Motion-Invariant (PMI) triplet loss.
Silhouette based View embeddings for Gait Recognition under Multiple Views
Aug 12, 2021
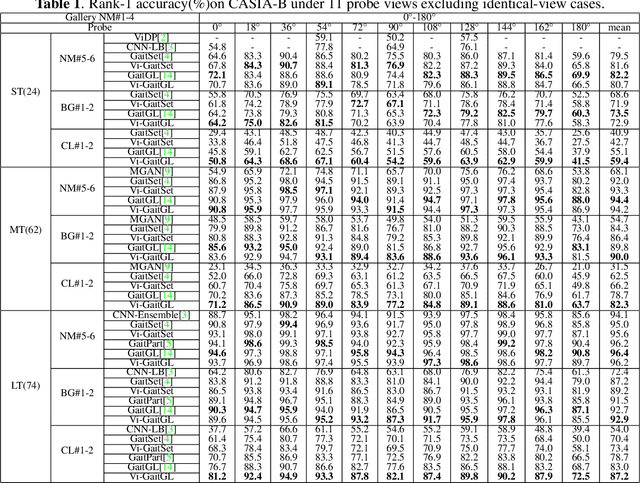

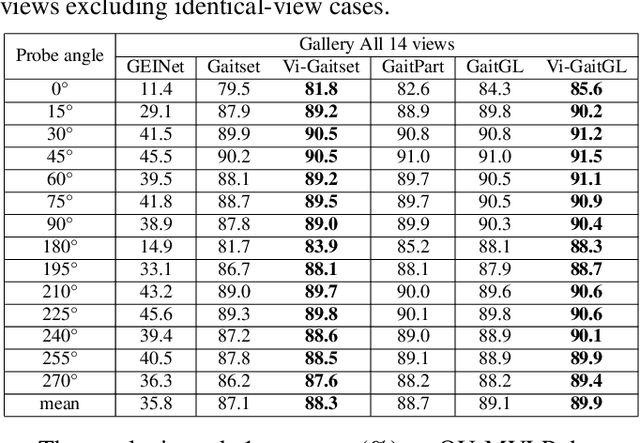
Gait recognition under multiple views is an important computer vision and pattern recognition task. In the emerging convolutional neural network based approaches, the information of view angle is ignored to some extent. Instead of direct view estimation and training view-specific recognition models, we propose a compatible framework that can embed view information into existing architectures of gait recognition. The embedding is simply achieved by a selective projection layer. Experimental results on two large public datasets show that the proposed framework is very effective.