 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Humans: Multispecies Animal Face Recognition Using Transfer Learning
Jun 08, 2026Individual animal recognition can be useful in the search for lost or stolen pets, the tracking of individuals of endangered species, and the recognition of animals in crowded farms. Present recognition techniques mostly use physical devices, e.g., microchips, often impractical and difficult to apply. These could be replaced by remote recognition via the animal's face; if accurate enough, it provides several advantages: it is non-invasive, can work at a distance, and is difficult to counterfeit, as, for instance, in the case of substituting sick animals for healthy ones in the food industry. The few existing datasets with sufficient per-subject images annotated with a single animal identity are not large enough to train current deep learning architectures. We rather investigate the possibility of transfer learning, exploiting pre-trained network models as backbones. Our experiments compared FaceNet, which is specifically trained on large databases of human faces, with the Vision Transformer (ViT) pre-trained on ImageNet, i.e., on object categories. We used three face datasets of very different animals: dogs, primates (lemurs, golden monkeys, and chimpanzees), and cattle. We report the results and, for each dataset, compare them with the state of the art (SOTA) ad hoc-trained deep networks. The capture conditions differ among the three datasets. Image quality (resolution, motion blur, diverse poses, etc.) decreases from dogs to cattle to primates. The best performance was achieved with dogs, where ViT reached a mean verification accuracy of 96.85% and a Rank-1 Identification Rate of 84.34%. The results for endangered primates are still encouraging, but performance varies across animal classes and tasks (verification or identification), and does not always outperform SOTA. For cattle, the ViT results outperform SOTA, while FaceNet is still competitive.
CoDA: Color Distribution Probing for Efficient and Generalizable AI-Generated Image Detection
May 23, 2026AI-generated image detection faces a persistent trade-off between generalization and efficiency: lightweight artifact-based methods often degrade on unseen generators or domains, whereas more robust large-scale models are computationally expensive. Meanwhile, existing benchmarks mainly focus on cross-model evaluation in photorealistic settings, leaving cross-domain robustness underexplored. To address this gap, we introduce FakeForm, a large-scale benchmark with approximately 370,000 images across 62 diverse domains for both cross-model and cross-domain evaluation. Motivated by this broader setting, we revisit color-distribution probing as an efficient complementary cue for AI-generated image detection. We observe that, especially for photographic content, real photographs tend to exhibit smoother and more stable color patterns, whereas synthetic images often show characteristic color imbalances introduced by neural generation. Based on this observation, we propose CoDA, a compact 1.48M-parameter detector built on a Noise-Quantization Probe, together with a theoretical analysis linking probe responses to color non-uniformity. Experiments show that CoDA achieves state-of-the-art performance on standard benchmarks and the best results on the challenging cross-domain evaluation of FakeForm, while remaining highly competitive in cross-model photorealistic settings. These results suggest that persistent generative artifacts can provide a practical foundation for efficient and robust AI-generated image detection. The models and FakeForm benchmark will be made publicly available.
Intra-finger Variability of Diffusion-based Latent Fingerprint Generation
Apr 11, 2026The primary goal of this work is to systematically evaluate the intra-finger variability of synthetic fingerprints (particularly latent prints) generated using a state-of-the-art diffusion model. Specifically, we focus on enhancing the latent style diversity of the generative model by constructing a comprehensive \textit{latent style bank} curated from seven diverse datasets, which enables the precise synthesis of latent prints with over 40 distinct styles encapsulating different surfaces and processing techniques. We also implement a semi-automated framework to understand the integrity of fingerprint ridges and minutiae in the generated impressions. Our analysis indicates that though the generation process largely preserves the identity, a small number of local inconsistencies (addition and removal of minutiae) are introduced, especially when there are poor quality regions in the reference image. Furthermore, mismatch between the reference image and the chosen style embedding that guides the generation process introduces global inconsistencies in the form of hallucinated ridge patterns. These insights highlight the limitations of existing synthetic fingerprint generators and the need to further improve these models to simultaneously enhance both diversity and identity consistency.
Continual Few-shot Adaptation for Synthetic Fingerprint Detection
Mar 15, 2026The quality and realism of synthetically generated fingerprint images have increased significantly over the past decade fueled by advancements in generative artificial intelligence (GenAI). This has exacerbated the vulnerability of fingerprint recognition systems to data injection attacks, where synthetic fingerprints are maliciously inserted during enrollment or authentication. Hence, there is an urgent need for methods to detect if a fingerprint image is real or synthetic. While it is straightforward to train deep neural network (DNN) models to classify images as real or synthetic, often such DNN models overfit the training data and fail to generalize well when applied to synthetic fingerprints generated using unseen GenAI models. In this work, we formulate synthetic fingerprint detection as a continual few-shot adaptation problem, where the objective is to rapidly evolve a base detector to identify new types of synthetic data. To enable continual few-shot adaptation, we employ a combination of binary cross-entropy and supervised contrastive (applied to the feature representation) losses and replay a few samples from previously known styles during fine-tuning to mitigate catastrophic forgetting. Experiments based on several DNN backbones (as feature extractors) and a variety of real and synthetic fingerprint datasets indicate that the proposed approach achieves a good trade-off between fast adaptation for detecting unseen synthetic styles and forgetting of known styles.
Optimal Transport-Guided Source-Free Adaptation for Face Anti-Spoofing
Mar 29, 2025Developing a face anti-spoofing model that meets the security requirements of clients worldwide is challenging due to the domain gap between training datasets and diverse end-user test data. Moreover, for security and privacy reasons, it is undesirable for clients to share a large amount of their face data with service providers. In this work, we introduce a novel method in which the face anti-spoofing model can be adapted by the client itself to a target domain at test time using only a small sample of data while keeping model parameters and training data inaccessible to the client. Specifically, we develop a prototype-based base model and an optimal transport-guided adaptor that enables adaptation in either a lightweight training or training-free fashion, without updating base model's parameters. Furthermore, we propose geodesic mixup, an optimal transport-based synthesis method that generates augmented training data along the geodesic path between source prototypes and target data distribution. This allows training a lightweight classifier to effectively adapt to target-specific characteristics while retaining essential knowledge learned from the source domain. In cross-domain and cross-attack settings, compared with recent methods, our method achieves average relative improvements of 19.17% in HTER and 8.58% in AUC, respectively.
CLIP4Sketch: Enhancing Sketch to Mugshot Matching through Dataset Augmentation using Diffusion Models
Aug 02, 2024



Forensic sketch-to-mugshot matching is a challenging task in face recognition, primarily hindered by the scarcity of annotated forensic sketches and the modality gap between sketches and photographs. To address this, we propose CLIP4Sketch, a novel approach that leverages diffusion models to generate a large and diverse set of sketch images, which helps in enhancing the performance of face recognition systems in sketch-to-mugshot matching. Our method utilizes Denoising Diffusion Probabilistic Models (DDPMs) to generate sketches with explicit control over identity and style. We combine CLIP and Adaface embeddings of a reference mugshot, along with textual descriptions of style, as the conditions to the diffusion model. We demonstrate the efficacy of our approach by generating a comprehensive dataset of sketches corresponding to mugshots and training a face recognition model on our synthetic data. Our results show significant improvements in sketch-to-mugshot matching accuracy over training on an existing, limited amount of real face sketch data, validating the potential of diffusion models in enhancing the performance of face recognition systems across modalities. We also compare our dataset with datasets generated using GAN-based methods to show its superiority.
GenPalm: Contactless Palmprint Generation with Diffusion Models
Jun 01, 2024
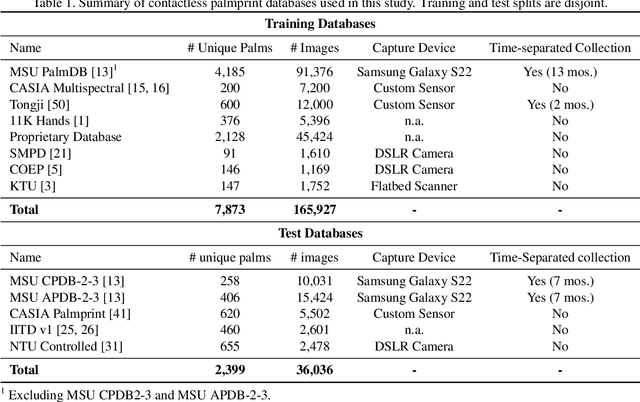
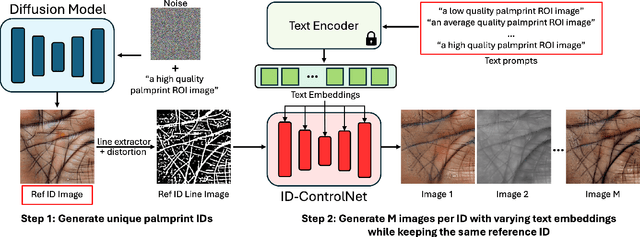
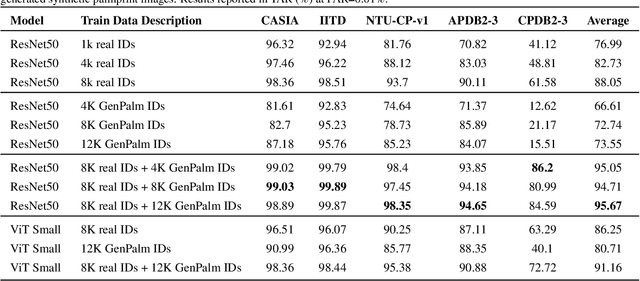
The scarcity of large-scale palmprint databases poses a significant bottleneck to advancements in contactless palmprint recognition. To address this, researchers have turned to synthetic data generation. While Generative Adversarial Networks (GANs) have been widely used, they suffer from instability and mode collapse. Recently, diffusion probabilistic models have emerged as a promising alternative, offering stable training and better distribution coverage. This paper introduces a novel palmprint generation method using diffusion probabilistic models, develops an end-to-end framework for synthesizing multiple palm identities, and validates the realism and utility of the generated palmprints. Experimental results demonstrate the effectiveness of our approach in generating palmprint images which enhance contactless palmprint recognition performance across several test databases utilizing challenging cross-database and time-separated evaluation protocols.
Universal Fingerprint Generation: Controllable Diffusion Model with Multimodal Conditions
Apr 21, 2024



The utilization of synthetic data for fingerprint recognition has garnered increased attention due to its potential to alleviate privacy concerns surrounding sensitive biometric data. However, current methods for generating fingerprints have limitations in creating impressions of the same finger with useful intra-class variations. To tackle this challenge, we present GenPrint, a framework to produce fingerprint images of various types while maintaining identity and offering humanly understandable control over different appearance factors such as fingerprint class, acquisition type, sensor device, and quality level. Unlike previous fingerprint generation approaches, GenPrint is not confined to replicating style characteristics from the training dataset alone: it enables the generation of novel styles from unseen devices without requiring additional fine-tuning. To accomplish these objectives, we developed GenPrint using latent diffusion models with multimodal conditions (text and image) for consistent generation of style and identity. Our experiments leverage a variety of publicly available datasets for training and evaluation. Results demonstrate the benefits of GenPrint in terms of identity preservation, explainable control, and universality of generated images. Importantly, the GenPrint-generated images yield comparable or even superior accuracy to models trained solely on real data and further enhances performance when augmenting the diversity of existing real fingerprint datasets.
Mobile Contactless Palmprint Recognition: Use of Multiscale, Multimodel Embeddings
Jan 16, 2024



Contactless palmprints are comprised of both global and local discriminative features. Most prior work focuses on extracting global features or local features alone for palmprint matching, whereas this research introduces a novel framework that combines global and local features for enhanced palmprint matching accuracy. Leveraging recent advancements in deep learning, this study integrates a vision transformer (ViT) and a convolutional neural network (CNN) to extract complementary local and global features. Next, a mobile-based, end-to-end palmprint recognition system is developed, referred to as Palm-ID. On top of the ViT and CNN features, Palm-ID incorporates a palmprint enhancement module and efficient dimensionality reduction (for faster matching). Palm-ID balances the trade-off between accuracy and latency, requiring just 18ms to extract a template of size 516 bytes, which can be efficiently searched against a 10,000 palmprint gallery in 0.33ms on an AMD EPYC 7543 32-Core CPU utilizing 128-threads. Cross-database matching protocols and evaluations on large-scale operational datasets demonstrate the robustness of the proposed method, achieving a TAR of 98.06% at FAR=0.01% on a newly collected, time-separated dataset. To show a practical deployment of the end-to-end system, the entire recognition pipeline is embedded within a mobile device for enhanced user privacy and security.
AdvGen: Physical Adversarial Attack on Face Presentation Attack Detection Systems
Nov 20, 2023



Evaluating the risk level of adversarial images is essential for safely deploying face authentication models in the real world. Popular approaches for physical-world attacks, such as print or replay attacks, suffer from some limitations, like including physical and geometrical artifacts. Recently, adversarial attacks have gained attraction, which try to digitally deceive the learning strategy of a recognition system using slight modifications to the captured image. While most previous research assumes that the adversarial image could be digitally fed into the authentication systems, this is not always the case for systems deployed in the real world. This paper demonstrates the vulnerability of face authentication systems to adversarial images in physical world scenarios. We propose AdvGen, an automated Generative Adversarial Network, to simulate print and replay attacks and generate adversarial images that can fool state-of-the-art PADs in a physical domain attack setting. Using this attack strategy, the attack success rate goes up to 82.01%. We test AdvGen extensively on four datasets and ten state-of-the-art PADs. We also demonstrate the effectiveness of our attack by conducting experiments in a realistic, physical environment.