 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP4Sketch: Enhancing Sketch to Mugshot Matching through Dataset Augmentation using Diffusion Models
Aug 02, 2024



Forensic sketch-to-mugshot matching is a challenging task in face recognition, primarily hindered by the scarcity of annotated forensic sketches and the modality gap between sketches and photographs. To address this, we propose CLIP4Sketch, a novel approach that leverages diffusion models to generate a large and diverse set of sketch images, which helps in enhancing the performance of face recognition systems in sketch-to-mugshot matching. Our method utilizes Denoising Diffusion Probabilistic Models (DDPMs) to generate sketches with explicit control over identity and style. We combine CLIP and Adaface embeddings of a reference mugshot, along with textual descriptions of style, as the conditions to the diffusion model. We demonstrate the efficacy of our approach by generating a comprehensive dataset of sketches corresponding to mugshots and training a face recognition model on our synthetic data. Our results show significant improvements in sketch-to-mugshot matching accuracy over training on an existing, limited amount of real face sketch data, validating the potential of diffusion models in enhancing the performance of face recognition systems across modalities. We also compare our dataset with datasets generated using GAN-based methods to show its superiority.
AdvGen: Physical Adversarial Attack on Face Presentation Attack Detection Systems
Nov 20, 2023



Evaluating the risk level of adversarial images is essential for safely deploying face authentication models in the real world. Popular approaches for physical-world attacks, such as print or replay attacks, suffer from some limitations, like including physical and geometrical artifacts. Recently, adversarial attacks have gained attraction, which try to digitally deceive the learning strategy of a recognition system using slight modifications to the captured image. While most previous research assumes that the adversarial image could be digitally fed into the authentication systems, this is not always the case for systems deployed in the real world. This paper demonstrates the vulnerability of face authentication systems to adversarial images in physical world scenarios. We propose AdvGen, an automated Generative Adversarial Network, to simulate print and replay attacks and generate adversarial images that can fool state-of-the-art PADs in a physical domain attack setting. Using this attack strategy, the attack success rate goes up to 82.01%. We test AdvGen extensively on four datasets and ten state-of-the-art PADs. We also demonstrate the effectiveness of our attack by conducting experiments in a realistic, physical environment.
Learning Deep and Compact Models for Gesture Recognition
Dec 29, 2017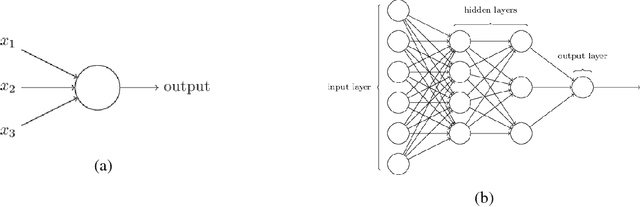
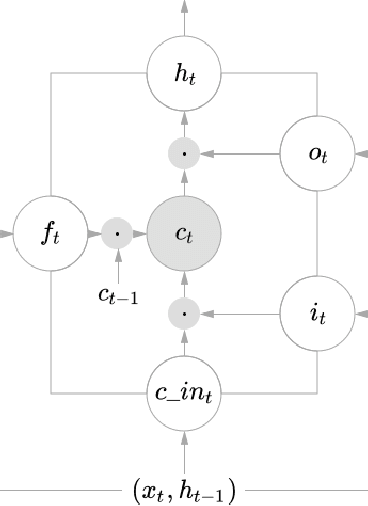
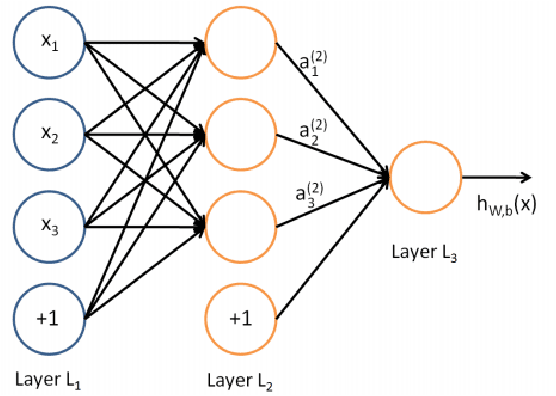
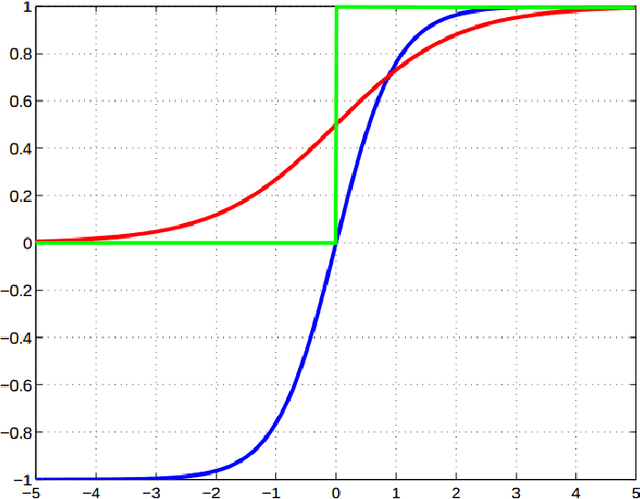
We look at the problem of developing a compact and accurate model for gesture recognition from videos in a deep-learning framework. Towards this we propose a joint 3DCNN-LSTM model that is end-to-end trainable and is shown to be better suited to capture the dynamic information in actions. The solution achieves close to state-of-the-art accuracy on the ChaLearn dataset, with only half the model size. We also explore ways to derive a much more compact representation in a knowledge distillation framework followed by model compression. The final model is less than $1~MB$ in size, which is less than one hundredth of our initial model, with a drop of $7\%$ in accuracy, and is suitable for real-time gesture recognition on mobile devices.