 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation of Synthetic Driving Datasets for Real-World Autonomous Driving
Feb 08, 2023While developing perception based deep learning models, the benefit of synthetic data is enormous. However, performance of networks trained with synthetic data for certain computer vision tasks degrade significantly when tested on real world data due to the domain gap between them. One of the popular solutions in bridging this gap between synthetic and actual world data is to frame it as a domain adaptation task. In this paper, we propose and evaluate novel ways for the betterment of such approaches. In particular we build upon the method of UNIT-GAN. In normal GAN training for the task of domain translation, pairing of images from both the domains (viz, real and synthetic) is done randomly. We propose a novel method to efficiently incorporate semantic supervision into this pair selection, which helps in boosting the performance of the model along with improving the visual quality of such transformed images. We illustrate our empirical findings on Cityscapes \cite{cityscapes} and challenging synthetic dataset Synscapes. Though the findings are reported on the base network of UNIT-GAN, they can be easily extended to any other similar network.
Learning Deep and Compact Models for Gesture Recognition
Dec 29, 2017
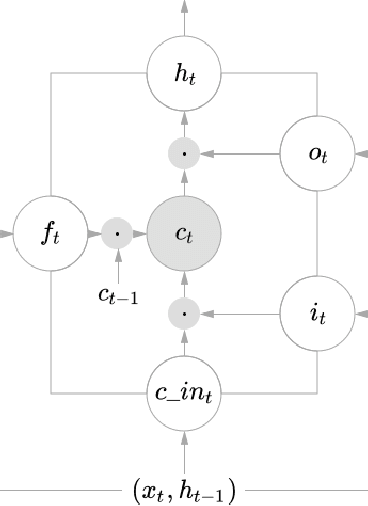
We look at the problem of developing a compact and accurate model for gesture recognition from videos in a deep-learning framework. Towards this we propose a joint 3DCNN-LSTM model that is end-to-end trainable and is shown to be better suited to capture the dynamic information in actions. The solution achieves close to state-of-the-art accuracy on the ChaLearn dataset, with only half the model size. We also explore ways to derive a much more compact representation in a knowledge distillation framework followed by model compression. The final model is less than $1~MB$ in size, which is less than one hundredth of our initial model, with a drop of $7\%$ in accuracy, and is suitable for real-time gesture recognition on mobile devices.