 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Transport-Guided Source-Free Adaptation for Face Anti-Spoofing
Mar 29, 2025Developing a face anti-spoofing model that meets the security requirements of clients worldwide is challenging due to the domain gap between training datasets and diverse end-user test data. Moreover, for security and privacy reasons, it is undesirable for clients to share a large amount of their face data with service providers. In this work, we introduce a novel method in which the face anti-spoofing model can be adapted by the client itself to a target domain at test time using only a small sample of data while keeping model parameters and training data inaccessible to the client. Specifically, we develop a prototype-based base model and an optimal transport-guided adaptor that enables adaptation in either a lightweight training or training-free fashion, without updating base model's parameters. Furthermore, we propose geodesic mixup, an optimal transport-based synthesis method that generates augmented training data along the geodesic path between source prototypes and target data distribution. This allows training a lightweight classifier to effectively adapt to target-specific characteristics while retaining essential knowledge learned from the source domain. In cross-domain and cross-attack settings, compared with recent methods, our method achieves average relative improvements of 19.17% in HTER and 8.58% in AUC, respectively.
Towards Effective Usage of Human-Centric Priors in Diffusion Models for Text-based Human Image Generation
Mar 08, 2024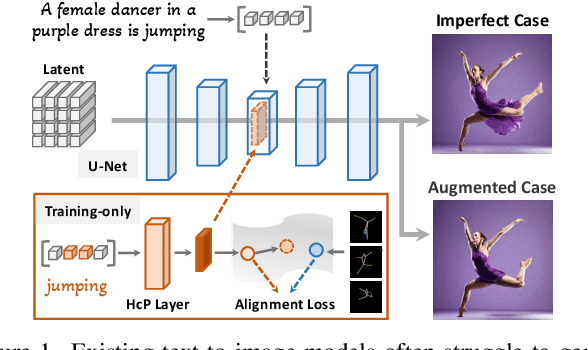
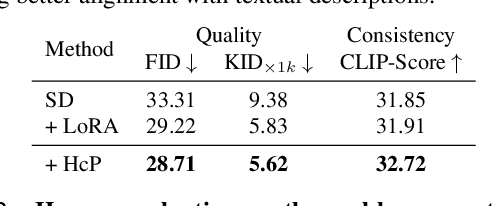
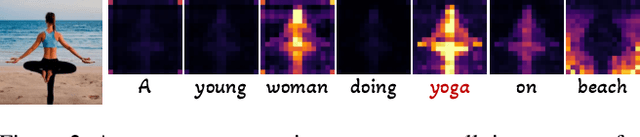
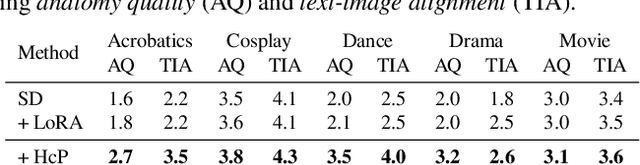
Vanilla text-to-image diffusion models struggle with generating accurate human images, commonly resulting in imperfect anatomies such as unnatural postures or disproportionate limbs.Existing methods address this issue mostly by fine-tuning the model with extra images or adding additional controls -- human-centric priors such as pose or depth maps -- during the image generation phase. This paper explores the integration of these human-centric priors directly into the model fine-tuning stage, essentially eliminating the need for extra conditions at the inference stage. We realize this idea by proposing a human-centric alignment loss to strengthen human-related information from the textual prompts within the cross-attention maps. To ensure semantic detail richness and human structural accuracy during fine-tuning, we introduce scale-aware and step-wise constraints within the diffusion process, according to an in-depth analysis of the cross-attention layer. Extensive experiments show that our method largely improves over state-of-the-art text-to-image models to synthesize high-quality human images based on user-written prompts. Project page: \url{https://hcplayercvpr2024.github.io}.
ITI-GEN: Inclusive Text-to-Image Generation
Sep 11, 2023



Text-to-image generative models often reflect the biases of the training data, leading to unequal representations of underrepresented groups. This study investigates inclusive text-to-image generative models that generate images based on human-written prompts and ensure the resulting images are uniformly distributed across attributes of interest. Unfortunately, directly expressing the desired attributes in the prompt often leads to sub-optimal results due to linguistic ambiguity or model misrepresentation. Hence, this paper proposes a drastically different approach that adheres to the maxim that "a picture is worth a thousand words". We show that, for some attributes, images can represent concepts more expressively than text. For instance, categories of skin tones are typically hard to specify by text but can be easily represented by example images. Building upon these insights, we propose a novel approach, ITI-GEN, that leverages readily available reference images for Inclusive Text-to-Image GENeration. The key idea is learning a set of prompt embeddings to generate images that can effectively represent all desired attribute categories. More importantly, ITI-GEN requires no model fine-tuning, making it computationally efficient to augment existing text-to-image models. Extensive experiments demonstrate that ITI-GEN largely improves over state-of-the-art models to generate inclusive images from a prompt. Project page: https://czhang0528.github.io/iti-gen.
Controllable 3D Generative Adversarial Face Model via Disentangling Shape and Appearance
Aug 30, 2022
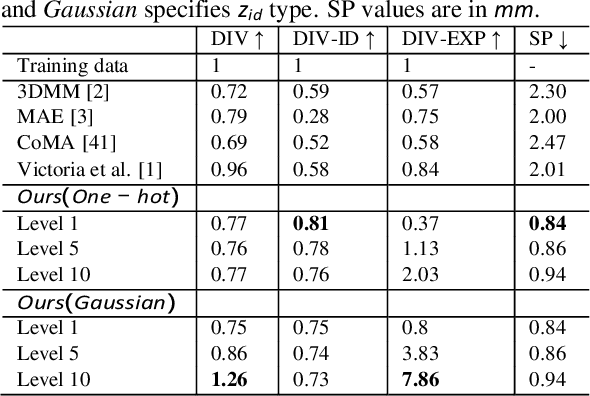
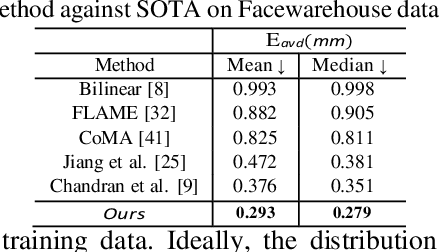
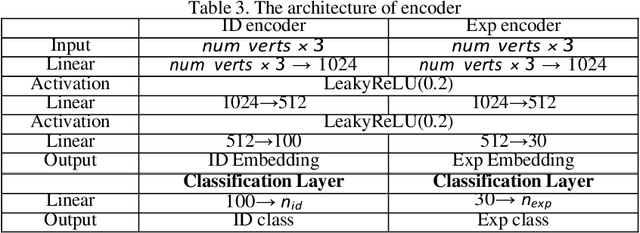
3D face modeling has been an active area of research in computer vision and computer graphics, fueling applications ranging from facial expression transfer in virtual avatars to synthetic data generation. Existing 3D deep learning generative models (e.g., VAE, GANs) allow generating compact face representations (both shape and texture) that can model non-linearities in the shape and appearance space (e.g., scatter effects, specularities, etc.). However, they lack the capability to control the generation of subtle expressions. This paper proposes a new 3D face generative model that can decouple identity and expression and provides granular control over expressions. In particular, we propose using a pair of supervised auto-encoder and generative adversarial networks to produce high-quality 3D faces, both in terms of appearance and shape. Experimental results in the generation of 3D faces learned with holistic expression labels, or Action Unit labels, show how we can decouple identity and expression; gaining fine-control over expressions while preserving identity.
Emotional Semantics-Preserved and Feature-Aligned CycleGAN for Visual Emotion Adaptation
Nov 25, 2020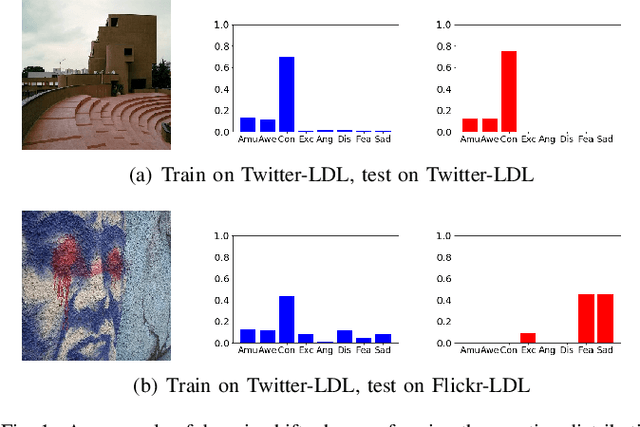

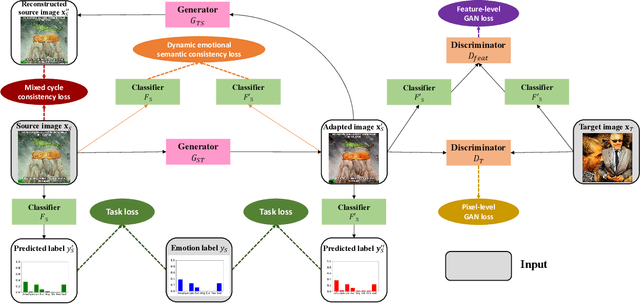
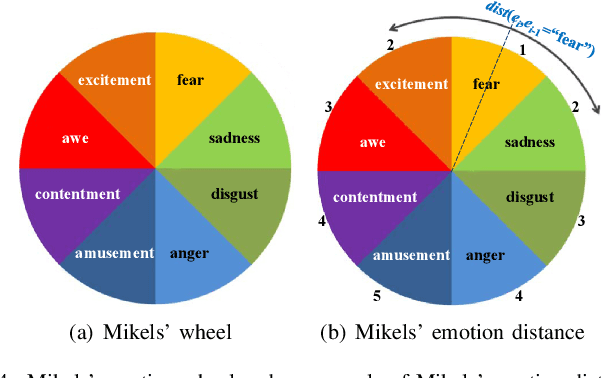
Thanks to large-scale labeled training data, deep neural networks (DNNs) have obtained remarkable success in many vision and multimedia tasks. However, because of the presence of domain shift, the learned knowledge of the well-trained DNNs cannot be well generalized to new domains or datasets that have few labels. Unsupervised domain adaptation (UDA) studies the problem of transferring models trained on one labeled source domain to another unlabeled target domain. In this paper, we focus on UDA in visual emotion analysis for both emotion distribution learning and dominant emotion classification. Specifically, we design a novel end-to-end cycle-consistent adversarial model, termed CycleEmotionGAN++. First, we generate an adapted domain to align the source and target domains on the pixel-level by improving CycleGAN with a multi-scale structured cycle-consistency loss. During the image translation, we propose a dynamic emotional semantic consistency loss to preserve the emotion labels of the source images. Second, we train a transferable task classifier on the adapted domain with feature-level alignment between the adapted and target domains. We conduct extensive UDA experiments on the Flickr-LDL & Twitter-LDL datasets for distribution learning and ArtPhoto & FI datasets for emotion classification. The results demonstrate the significant improvements yielded by the proposed CycleEmotionGAN++ as compared to state-of-the-art UDA approaches.