 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view Image Diffusion via Coordinate Noise and Fourier Attention
Dec 04, 2024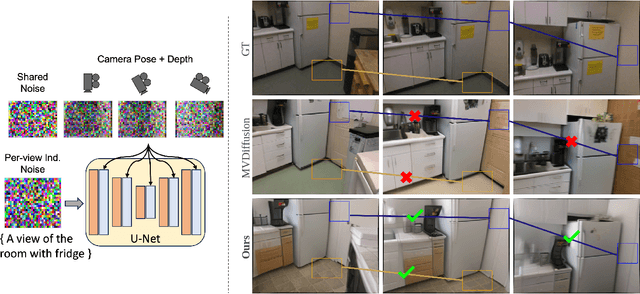

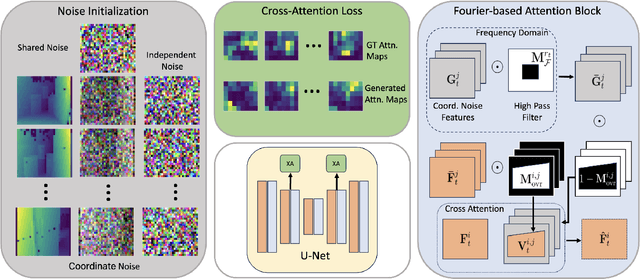
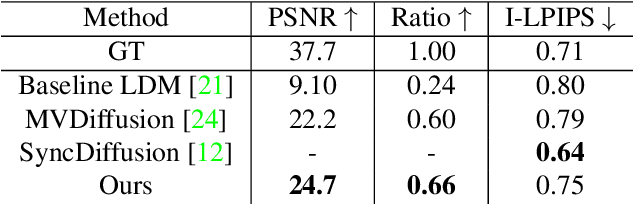
Recently, text-to-image generation with diffusion models has made significant advancements in both higher fidelity and generalization capabilities compared to previous baselines. However, generating holistic multi-view consistent images from prompts still remains an important and challenging task. To address this challenge, we propose a diffusion process that attends to time-dependent spatial frequencies of features with a novel attention mechanism as well as novel noise initialization technique and cross-attention loss. This Fourier-based attention block focuses on features from non-overlapping regions of the generated scene in order to better align the global appearance. Our noise initialization technique incorporates shared noise and low spatial frequency information derived from pixel coordinates and depth maps to induce noise correlations across views. The cross-attention loss further aligns features sharing the same prompt across the scene. Our technique improves SOTA on several quantitative metrics with qualitatively better results when compared to other state-of-the-art approaches for multi-view consistency.
Generalizable Human Gaussians for Sparse View Synthesis
Jul 17, 2024Recent progress in neural rendering has brought forth pioneering methods, such as NeRF and Gaussian Splatting, which revolutionize view rendering across various domains like AR/VR, gaming, and content creation. While these methods excel at interpolating {\em within the training data}, the challenge of generalizing to new scenes and objects from very sparse views persists. Specifically, modeling 3D humans from sparse views presents formidable hurdles due to the inherent complexity of human geometry, resulting in inaccurate reconstructions of geometry and textures. To tackle this challenge, this paper leverages recent advancements in Gaussian Splatting and introduces a new method to learn generalizable human Gaussians that allows photorealistic and accurate view-rendering of a new human subject from a limited set of sparse views in a feed-forward manner. A pivotal innovation of our approach involves reformulating the learning of 3D Gaussian parameters into a regression process defined on the 2D UV space of a human template, which allows leveraging the strong geometry prior and the advantages of 2D convolutions. In addition, a multi-scaffold is proposed to effectively represent the offset details. Our method outperforms recent methods on both within-dataset generalization as well as cross-dataset generalization settings.
Towards Realistic Generative 3D Face Models
Apr 24, 2023In recent years, there has been significant progress in 2D generative face models fueled by applications such as animation, synthetic data generation, and digital avatars. However, due to the absence of 3D information, these 2D models often struggle to accurately disentangle facial attributes like pose, expression, and illumination, limiting their editing capabilities. To address this limitation, this paper proposes a 3D controllable generative face model to produce high-quality albedo and precise 3D shape leveraging existing 2D generative models. By combining 2D face generative models with semantic face manipulation, this method enables editing of detailed 3D rendered faces. The proposed framework utilizes an alternating descent optimization approach over shape and albedo. Differentiable rendering is used to train high-quality shapes and albedo without 3D supervision. Moreover, this approach outperforms the state-of-the-art (SOTA) methods in the well-known NoW benchmark for shape reconstruction. It also outperforms the SOTA reconstruction models in recovering rendered faces' identities across novel poses by an average of 10%. Additionally, the paper demonstrates direct control of expressions in 3D faces by exploiting latent space leading to text-based editing of 3D faces.
Unpaired Image Translation via Vector Symbolic Architectures
Sep 06, 2022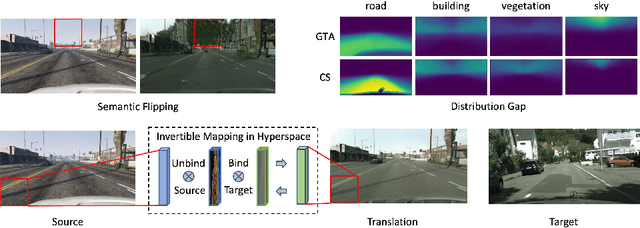
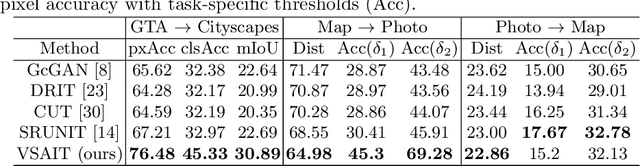


Image-to-image translation has played an important role in enabling synthetic data for computer vision. However, if the source and target domains have a large semantic mismatch, existing techniques often suffer from source content corruption aka semantic flipping. To address this problem, we propose a new paradigm for image-to-image translation using Vector Symbolic Architectures (VSA), a theoretical framework which defines algebraic operations in a high-dimensional vector (hypervector) space. We introduce VSA-based constraints on adversarial learning for source-to-target translations by learning a hypervector mapping that inverts the translation to ensure consistency with source content. We show both qualitatively and quantitatively that our method improves over other state-of-the-art techniques.
Controllable 3D Generative Adversarial Face Model via Disentangling Shape and Appearance
Aug 30, 2022
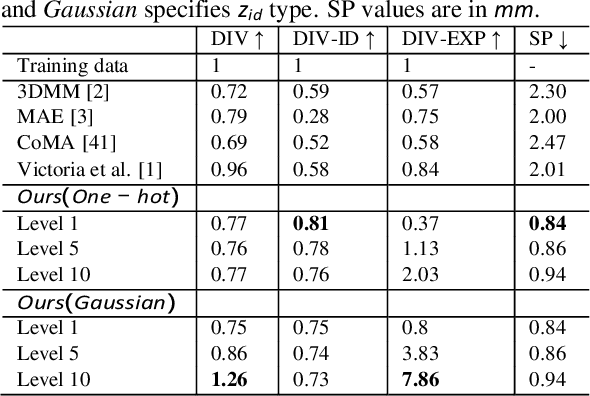
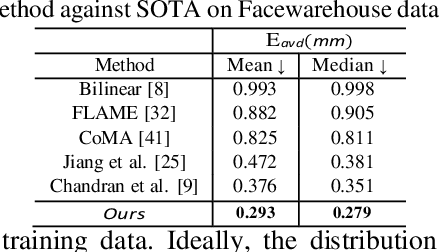
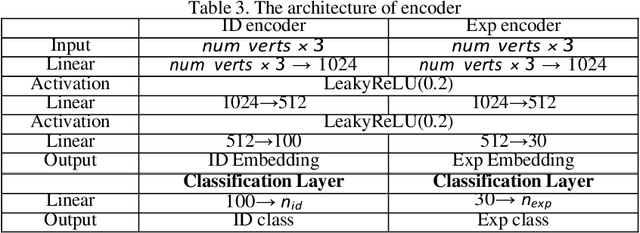
3D face modeling has been an active area of research in computer vision and computer graphics, fueling applications ranging from facial expression transfer in virtual avatars to synthetic data generation. Existing 3D deep learning generative models (e.g., VAE, GANs) allow generating compact face representations (both shape and texture) that can model non-linearities in the shape and appearance space (e.g., scatter effects, specularities, etc.). However, they lack the capability to control the generation of subtle expressions. This paper proposes a new 3D face generative model that can decouple identity and expression and provides granular control over expressions. In particular, we propose using a pair of supervised auto-encoder and generative adversarial networks to produce high-quality 3D faces, both in terms of appearance and shape. Experimental results in the generation of 3D faces learned with holistic expression labels, or Action Unit labels, show how we can decouple identity and expression; gaining fine-control over expressions while preserving identity.
RarePlanes: Synthetic Data Takes Flight
Jun 04, 2020
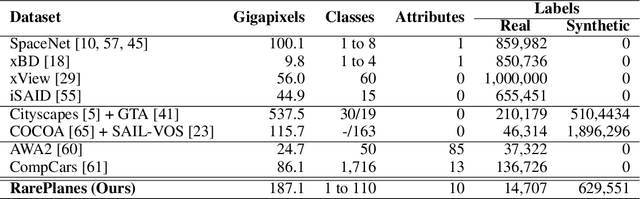

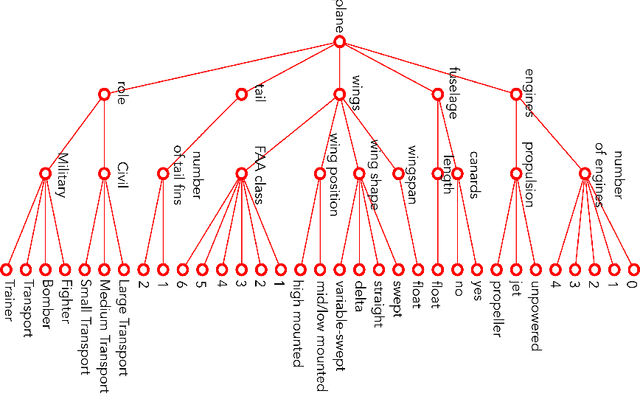
RarePlanes is a unique open-source machine learning dataset that incorporates both real and synthetically generated satellite imagery. The RarePlanes dataset specifically focuses on the value of synthetic data to aid computer vision algorithms in their ability to automatically detect aircraft and their attributes in satellite imagery. Although other synthetic/real combination datasets exist, RarePlanes is the largest openly-available very-high resolution dataset built to test the value of synthetic data from an overhead perspective. Previous research has shown that synthetic data can reduce the amount of real training data needed and potentially improve performance for many tasks in the computer vision domain. The real portion of the dataset consists of 253 Maxar WorldView-3 satellite scenes spanning 112 locations and 2,142 km^2 with 14,700 hand-annotated aircraft. The accompanying synthetic dataset is generated via a novel simulation platform and features 50,000 synthetic satellite images with ~630,000 aircraft annotations. Both the real and synthetically generated aircraft feature 10 fine grain attributes including: aircraft length, wingspan, wing-shape, wing-position, wingspan class, propulsion, number of engines, number of vertical-stabilizers, presence of canards, and aircraft role. Finally, we conduct extensive experiments to evaluate the real and synthetic datasets and compare performances. By doing so, we show the value of synthetic data for the task of detecting and classifying aircraft from an overhead perspective.