 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDanceTogether! Identity-Preserving Multi-Person Interactive Video Generation
May 23, 2025Controllable video generation (CVG) has advanced rapidly, yet current systems falter when more than one actor must move, interact, and exchange positions under noisy control signals. We address this gap with DanceTogether, the first end-to-end diffusion framework that turns a single reference image plus independent pose-mask streams into long, photorealistic videos while strictly preserving every identity. A novel MaskPoseAdapter binds "who" and "how" at every denoising step by fusing robust tracking masks with semantically rich-but noisy-pose heat-maps, eliminating the identity drift and appearance bleeding that plague frame-wise pipelines. To train and evaluate at scale, we introduce (i) PairFS-4K, 26 hours of dual-skater footage with 7,000+ distinct IDs, (ii) HumanRob-300, a one-hour humanoid-robot interaction set for rapid cross-domain transfer, and (iii) TogetherVideoBench, a three-track benchmark centered on the DanceTogEval-100 test suite covering dance, boxing, wrestling, yoga, and figure skating. On TogetherVideoBench, DanceTogether outperforms the prior arts by a significant margin. Moreover, we show that a one-hour fine-tune yields convincing human-robot videos, underscoring broad generalization to embodied-AI and HRI tasks. Extensive ablations confirm that persistent identity-action binding is critical to these gains. Together, our model, datasets, and benchmark lift CVG from single-subject choreography to compositionally controllable, multi-actor interaction, opening new avenues for digital production, simulation, and embodied intelligence. Our video demos and code are available at https://DanceTog.github.io/.
MVPortrait: Text-Guided Motion and Emotion Control for Multi-view Vivid Portrait Animation
Mar 25, 2025Recent portrait animation methods have made significant strides in generating realistic lip synchronization. However, they often lack explicit control over head movements and facial expressions, and cannot produce videos from multiple viewpoints, resulting in less controllable and expressive animations. Moreover, text-guided portrait animation remains underexplored, despite its user-friendly nature. We present a novel two-stage text-guided framework, MVPortrait (Multi-view Vivid Portrait), to generate expressive multi-view portrait animations that faithfully capture the described motion and emotion. MVPortrait is the first to introduce FLAME as an intermediate representation, effectively embedding facial movements, expressions, and view transformations within its parameter space. In the first stage, we separately train the FLAME motion and emotion diffusion models based on text input. In the second stage, we train a multi-view video generation model conditioned on a reference portrait image and multi-view FLAME rendering sequences from the first stage. Experimental results exhibit that MVPortrait outperforms existing methods in terms of motion and emotion control, as well as view consistency. Furthermore, by leveraging FLAME as a bridge, MVPortrait becomes the first controllable portrait animation framework that is compatible with text, speech, and video as driving signals.
OmniPhysGS: 3D Constitutive Gaussians for General Physics-Based Dynamics Generation
Jan 31, 2025



Recently, significant advancements have been made in the reconstruction and generation of 3D assets, including static cases and those with physical interactions. To recover the physical properties of 3D assets, existing methods typically assume that all materials belong to a specific predefined category (e.g., elasticity). However, such assumptions ignore the complex composition of multiple heterogeneous objects in real scenarios and tend to render less physically plausible animation given a wider range of objects. We propose OmniPhysGS for synthesizing a physics-based 3D dynamic scene composed of more general objects. A key design of OmniPhysGS is treating each 3D asset as a collection of constitutive 3D Gaussians. For each Gaussian, its physical material is represented by an ensemble of 12 physical domain-expert sub-models (rubber, metal, honey, water, etc.), which greatly enhances the flexibility of the proposed model. In the implementation, we define a scene by user-specified prompts and supervise the estimation of material weighting factors via a pretrained video diffusion model. Comprehensive experiments demonstrate that OmniPhysGS achieves more general and realistic physical dynamics across a broader spectrum of materials, including elastic, viscoelastic, plastic, and fluid substances, as well as interactions between different materials. Our method surpasses existing methods by approximately 3% to 16% in metrics of visual quality and text alignment.
Training-free Regional Prompting for Diffusion Transformers
Nov 04, 2024



Diffusion models have demonstrated excellent capabilities in text-to-image generation. Their semantic understanding (i.e., prompt following) ability has also been greatly improved with large language models (e.g., T5, Llama). However, existing models cannot perfectly handle long and complex text prompts, especially when the text prompts contain various objects with numerous attributes and interrelated spatial relationships. While many regional prompting methods have been proposed for UNet-based models (SD1.5, SDXL), but there are still no implementations based on the recent Diffusion Transformer (DiT) architecture, such as SD3 and FLUX.1.In this report, we propose and implement regional prompting for FLUX.1 based on attention manipulation, which enables DiT with fined-grained compositional text-to-image generation capability in a training-free manner. Code is available at https://github.com/antonioo-c/Regional-Prompting-FLUX.
Generalizable Human Gaussians for Sparse View Synthesis
Jul 17, 2024


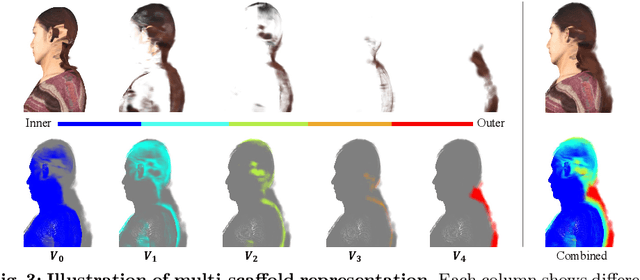
Recent progress in neural rendering has brought forth pioneering methods, such as NeRF and Gaussian Splatting, which revolutionize view rendering across various domains like AR/VR, gaming, and content creation. While these methods excel at interpolating {\em within the training data}, the challenge of generalizing to new scenes and objects from very sparse views persists. Specifically, modeling 3D humans from sparse views presents formidable hurdles due to the inherent complexity of human geometry, resulting in inaccurate reconstructions of geometry and textures. To tackle this challenge, this paper leverages recent advancements in Gaussian Splatting and introduces a new method to learn generalizable human Gaussians that allows photorealistic and accurate view-rendering of a new human subject from a limited set of sparse views in a feed-forward manner. A pivotal innovation of our approach involves reformulating the learning of 3D Gaussian parameters into a regression process defined on the 2D UV space of a human template, which allows leveraging the strong geometry prior and the advantages of 2D convolutions. In addition, a multi-scaffold is proposed to effectively represent the offset details. Our method outperforms recent methods on both within-dataset generalization as well as cross-dataset generalization settings.
Personalized Face Inpainting with Diffusion Models by Parallel Visual Attention
Dec 06, 2023Face inpainting is important in various applications, such as photo restoration, image editing, and virtual reality. Despite the significant advances in face generative models, ensuring that a person's unique facial identity is maintained during the inpainting process is still an elusive goal. Current state-of-the-art techniques, exemplified by MyStyle, necessitate resource-intensive fine-tuning and a substantial number of images for each new identity. Furthermore, existing methods often fall short in accommodating user-specified semantic attributes, such as beard or expression. To improve inpainting results, and reduce the computational complexity during inference, this paper proposes the use of Parallel Visual Attention (PVA) in conjunction with diffusion models. Specifically, we insert parallel attention matrices to each cross-attention module in the denoising network, which attends to features extracted from reference images by an identity encoder. We train the added attention modules and identity encoder on CelebAHQ-IDI, a dataset proposed for identity-preserving face inpainting. Experiments demonstrate that PVA attains unparalleled identity resemblance in both face inpainting and face inpainting with language guidance tasks, in comparison to various benchmarks, including MyStyle, Paint by Example, and Custom Diffusion. Our findings reveal that PVA ensures good identity preservation while offering effective language-controllability. Additionally, in contrast to Custom Diffusion, PVA requires just 40 fine-tuning steps for each new identity, which translates to a significant speed increase of over 20 times.
PATMAT: Person Aware Tuning of Mask-Aware Transformer for Face Inpainting
Apr 12, 2023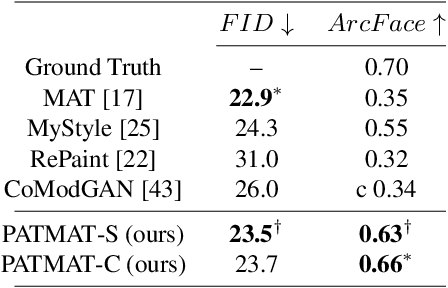
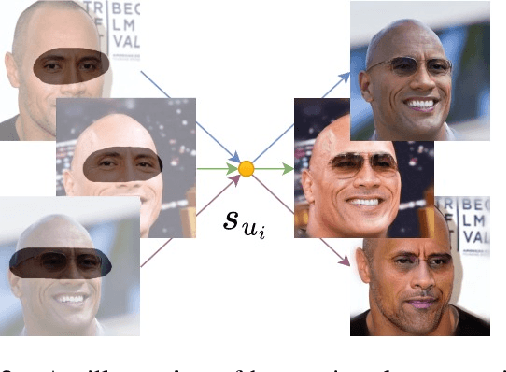

Generative models such as StyleGAN2 and Stable Diffusion have achieved state-of-the-art performance in computer vision tasks such as image synthesis, inpainting, and de-noising. However, current generative models for face inpainting often fail to preserve fine facial details and the identity of the person, despite creating aesthetically convincing image structures and textures. In this work, we propose Person Aware Tuning (PAT) of Mask-Aware Transformer (MAT) for face inpainting, which addresses this issue. Our proposed method, PATMAT, effectively preserves identity by incorporating reference images of a subject and fine-tuning a MAT architecture trained on faces. By using ~40 reference images, PATMAT creates anchor points in MAT's style module, and tunes the model using the fixed anchors to adapt the model to a new face identity. Moreover, PATMAT's use of multiple images per anchor during training allows the model to use fewer reference images than competing methods. We demonstrate that PATMAT outperforms state-of-the-art models in terms of image quality, the preservation of person-specific details, and the identity of the subject. Our results suggest that PATMAT can be a promising approach for improving the quality of personalized face inpainting.
Extracting Semantic Knowledge from GANs with Unsupervised Learning
Nov 30, 2022


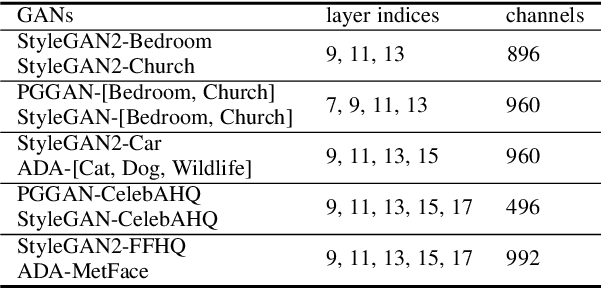
Recently, unsupervised learning has made impressive progress on various tasks. Despite the dominance of discriminative models, increasing attention is drawn to representations learned by generative models and in particular, Generative Adversarial Networks (GANs). Previous works on the interpretation of GANs reveal that GANs encode semantics in feature maps in a linearly separable form. In this work, we further find that GAN's features can be well clustered with the linear separability assumption. We propose a novel clustering algorithm, named KLiSH, which leverages the linear separability to cluster GAN's features. KLiSH succeeds in extracting fine-grained semantics of GANs trained on datasets of various objects, e.g., car, portrait, animals, and so on. With KLiSH, we can sample images from GANs along with their segmentation masks and synthesize paired image-segmentation datasets. Using the synthesized datasets, we enable two downstream applications. First, we train semantic segmentation networks on these datasets and test them on real images, realizing unsupervised semantic segmentation. Second, we train image-to-image translation networks on the synthesized datasets, enabling semantic-conditional image synthesis without human annotations.
Bridging the Gap Between Training and Inference of Bayesian Controllable Language Models
Jun 11, 2022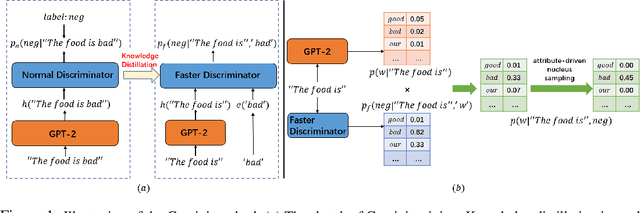

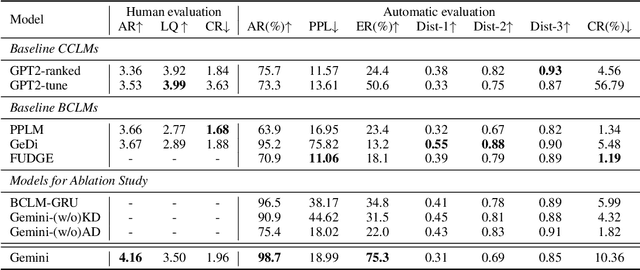
Large-scale pre-trained language models have achieved great success on natural language generation tasks. However, it is difficult to control the pre-trained language models to generate sentences with the desired attribute such as topic and sentiment, etc. Recently, Bayesian Controllable Language Models (BCLMs) have been shown to be efficient in controllable language generation. Rather than fine-tuning the parameters of pre-trained language models, BCLMs use external discriminators to guide the generation of pre-trained language models. However, the mismatch between training and inference of BCLMs limits the performance of the models. To address the problem, in this work we propose a "Gemini Discriminator" for controllable language generation which alleviates the mismatch problem with a small computational cost. We tested our method on two controllable language generation tasks: sentiment control and topic control. On both tasks, our method reached achieved new state-of-the-art results in automatic and human evaluations.
Linear Semantics in Generative Adversarial Networks
Apr 01, 2021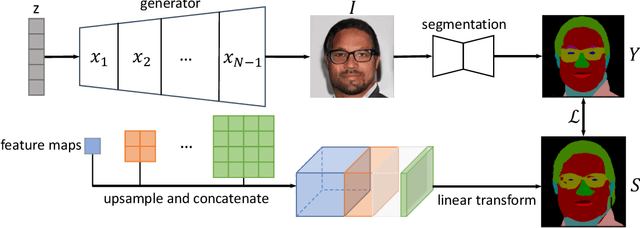

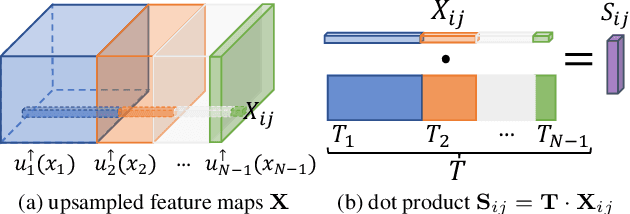

Generative Adversarial Networks (GANs) are able to generate high-quality images, but it remains difficult to explicitly specify the semantics of synthesized images. In this work, we aim to better understand the semantic representation of GANs, and thereby enable semantic control in GAN's generation process. Interestingly, we find that a well-trained GAN encodes image semantics in its internal feature maps in a surprisingly simple way: a linear transformation of feature maps suffices to extract the generated image semantics. To verify this simplicity, we conduct extensive experiments on various GANs and datasets; and thanks to this simplicity, we are able to learn a semantic segmentation model for a trained GAN from a small number (e.g., 8) of labeled images. Last but not least, leveraging our findings, we propose two few-shot image editing approaches, namely Semantic-Conditional Sampling and Semantic Image Editing. Given a trained GAN and as few as eight semantic annotations, the user is able to generate diverse images subject to a user-provided semantic layout, and control the synthesized image semantics. We have made the code publicly available.