 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Blurry to Believable: Enhancing Low-quality Talking Heads with 3D Generative Priors
Feb 05, 2026Creating high-fidelity, animatable 3D talking heads is crucial for immersive applications, yet often hindered by the prevalence of low-quality image or video sources, which yield poor 3D reconstructions. In this paper, we introduce SuperHead, a novel framework for enhancing low-resolution, animatable 3D head avatars. The core challenge lies in synthesizing high-quality geometry and textures, while ensuring both 3D and temporal consistency during animation and preserving subject identity. Despite recent progress in image, video and 3D-based super-resolution (SR), existing SR techniques are ill-equipped to handle dynamic 3D inputs. To address this, SuperHead leverages the rich priors from pre-trained 3D generative models via a novel dynamics-aware 3D inversion scheme. This process optimizes the latent representation of the generative model to produce a super-resolved 3D Gaussian Splatting (3DGS) head model, which is subsequently rigged to an underlying parametric head model (e.g., FLAME) for animation. The inversion is jointly supervised using a sparse collection of upscaled 2D face renderings and corresponding depth maps, captured from diverse facial expressions and camera viewpoints, to ensure realism under dynamic facial motions. Experiments demonstrate that SuperHead generates avatars with fine-grained facial details under dynamic motions, significantly outperforming baseline methods in visual quality.
FabricDiffusion: High-Fidelity Texture Transfer for 3D Garments Generation from In-The-Wild Clothing Images
Oct 02, 2024

We introduce FabricDiffusion, a method for transferring fabric textures from a single clothing image to 3D garments of arbitrary shapes. Existing approaches typically synthesize textures on the garment surface through 2D-to-3D texture mapping or depth-aware inpainting via generative models. Unfortunately, these methods often struggle to capture and preserve texture details, particularly due to challenging occlusions, distortions, or poses in the input image. Inspired by the observation that in the fashion industry, most garments are constructed by stitching sewing patterns with flat, repeatable textures, we cast the task of clothing texture transfer as extracting distortion-free, tileable texture materials that are subsequently mapped onto the UV space of the garment. Building upon this insight, we train a denoising diffusion model with a large-scale synthetic dataset to rectify distortions in the input texture image. This process yields a flat texture map that enables a tight coupling with existing Physically-Based Rendering (PBR) material generation pipelines, allowing for realistic relighting of the garment under various lighting conditions. We show that FabricDiffusion can transfer various features from a single clothing image including texture patterns, material properties, and detailed prints and logos. Extensive experiments demonstrate that our model significantly outperforms state-to-the-art methods on both synthetic data and real-world, in-the-wild clothing images while generalizing to unseen textures and garment shapes.
Generalizable Human Gaussians for Sparse View Synthesis
Jul 17, 2024Recent progress in neural rendering has brought forth pioneering methods, such as NeRF and Gaussian Splatting, which revolutionize view rendering across various domains like AR/VR, gaming, and content creation. While these methods excel at interpolating {\em within the training data}, the challenge of generalizing to new scenes and objects from very sparse views persists. Specifically, modeling 3D humans from sparse views presents formidable hurdles due to the inherent complexity of human geometry, resulting in inaccurate reconstructions of geometry and textures. To tackle this challenge, this paper leverages recent advancements in Gaussian Splatting and introduces a new method to learn generalizable human Gaussians that allows photorealistic and accurate view-rendering of a new human subject from a limited set of sparse views in a feed-forward manner. A pivotal innovation of our approach involves reformulating the learning of 3D Gaussian parameters into a regression process defined on the 2D UV space of a human template, which allows leveraging the strong geometry prior and the advantages of 2D convolutions. In addition, a multi-scaffold is proposed to effectively represent the offset details. Our method outperforms recent methods on both within-dataset generalization as well as cross-dataset generalization settings.
Hamba: Single-view 3D Hand Reconstruction with Graph-guided Bi-Scanning Mamba
Jul 12, 2024



3D Hand reconstruction from a single RGB image is challenging due to the articulated motion, self-occlusion, and interaction with objects. Existing SOTA methods employ attention-based transformers to learn the 3D hand pose and shape, but they fail to achieve robust and accurate performance due to insufficient modeling of joint spatial relations. To address this problem, we propose a novel graph-guided Mamba framework, named Hamba, which bridges graph learning and state space modeling. Our core idea is to reformulate Mamba's scanning into graph-guided bidirectional scanning for 3D reconstruction using a few effective tokens. This enables us to learn the joint relations and spatial sequences for enhancing the reconstruction performance. Specifically, we design a novel Graph-guided State Space (GSS) block that learns the graph-structured relations and spatial sequences of joints and uses 88.5% fewer tokens than attention-based methods. Additionally, we integrate the state space features and the global features using a fusion module. By utilizing the GSS block and the fusion module, Hamba effectively leverages the graph-guided state space modeling features and jointly considers global and local features to improve performance. Extensive experiments on several benchmarks and in-the-wild tests demonstrate that Hamba significantly outperforms existing SOTAs, achieving the PA-MPVPE of 5.3mm and F@15mm of 0.992 on FreiHAND. Hamba is currently Rank 1 in two challenging competition leaderboards on 3D hand reconstruction. The code will be available upon acceptance. [Website](https://humansensinglab.github.io/Hamba/).
Taming 3DGS: High-Quality Radiance Fields with Limited Resources
Jun 21, 2024
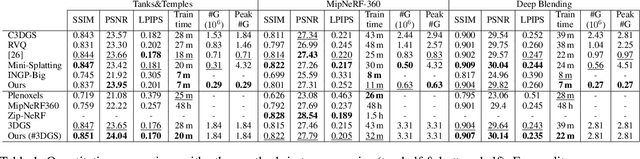
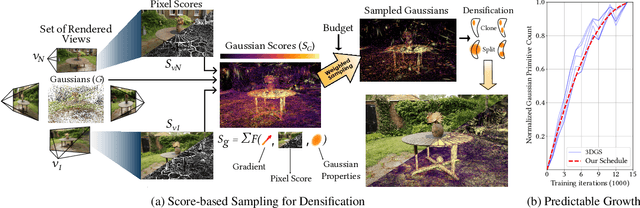
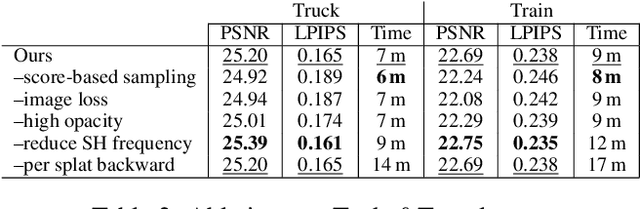
3D Gaussian Splatting (3DGS) has transformed novel-view synthesis with its fast, interpretable, and high-fidelity rendering. However, its resource requirements limit its usability. Especially on constrained devices, training performance degrades quickly and often cannot complete due to excessive memory consumption of the model. The method converges with an indefinite number of Gaussians -- many of them redundant -- making rendering unnecessarily slow and preventing its usage in downstream tasks that expect fixed-size inputs. To address these issues, we tackle the challenges of training and rendering 3DGS models on a budget. We use a guided, purely constructive densification process that steers densification toward Gaussians that raise the reconstruction quality. Model size continuously increases in a controlled manner towards an exact budget, using score-based densification of Gaussians with training-time priors that measure their contribution. We further address training speed obstacles: following a careful analysis of 3DGS' original pipeline, we derive faster, numerically equivalent solutions for gradient computation and attribute updates, including an alternative parallelization for efficient backpropagation. We also propose quality-preserving approximations where suitable to reduce training time even further. Taken together, these enhancements yield a robust, scalable solution with reduced training times, lower compute and memory requirements, and high quality. Our evaluation shows that in a budgeted setting, we obtain competitive quality metrics with 3DGS while achieving a 4--5x reduction in both model size and training time. With more generous budgets, our measured quality surpasses theirs. These advances open the door for novel-view synthesis in constrained environments, e.g., mobile devices.
Towards Realistic Generative 3D Face Models
Apr 24, 2023In recent years, there has been significant progress in 2D generative face models fueled by applications such as animation, synthetic data generation, and digital avatars. However, due to the absence of 3D information, these 2D models often struggle to accurately disentangle facial attributes like pose, expression, and illumination, limiting their editing capabilities. To address this limitation, this paper proposes a 3D controllable generative face model to produce high-quality albedo and precise 3D shape leveraging existing 2D generative models. By combining 2D face generative models with semantic face manipulation, this method enables editing of detailed 3D rendered faces. The proposed framework utilizes an alternating descent optimization approach over shape and albedo. Differentiable rendering is used to train high-quality shapes and albedo without 3D supervision. Moreover, this approach outperforms the state-of-the-art (SOTA) methods in the well-known NoW benchmark for shape reconstruction. It also outperforms the SOTA reconstruction models in recovering rendered faces' identities across novel poses by an average of 10%. Additionally, the paper demonstrates direct control of expressions in 3D faces by exploiting latent space leading to text-based editing of 3D faces.