 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Binary Moral Judgment: Modeling Ethical Pluralism in AI
May 27, 2026Critical decision-making in socially consequential spaces is increasingly involving AI systems at varying capacities. Yet, despite the ubiquity of autonomous systems, most approaches to handling autonomous moral decision-making resort to scalar or binary judgments. These methods are insufficient for acceptable moral reasoning, as they provide little explanation, leaving out imperative contextual and theoretical information that must be included to support accountability. For this, we propose a framework to model moral reasoning as a distribution over normative ethical theories or ethical pluralism. We introduce a normative ethics simplex that integrates these theories. A benchmark of 450 cases across 15 fine-grained subtheories was also prepared for the purposes of stacked ensemble learning. These cases describe ethical dilemmas in natural language and have associated extracted contextual features. The implementation of the simplex was achieved via a two-stream normative-semantic architecture. This is followed by the fusion of normative information and a sequential, stacking ensemble to learn the best fit of the three broad theories: consequentialism, virtue ethics, and deontology, and the 15 subcategories. Our experiments demonstrate that the integration of contextual and normative priors with the semantic embeddings significantly improves the performance of the classification, displaying an accuracy of 88.89%. We conducted ablation studies to show that structured ethical representations contribute beyond analogical reasoning, and the chosen stacking architecture gives the best results due to the gradual learning of granularity. Ethical pluralism is also analyzed through entropy, confidence, and visualization. Thus, modeling ethical pluralism as a probabilistic normative distribution supports human-like moral reasoning, ethical disagreement analysis, and future alignment in AI systems.
Taming 3DGS: High-Quality Radiance Fields with Limited Resources
Jun 21, 2024
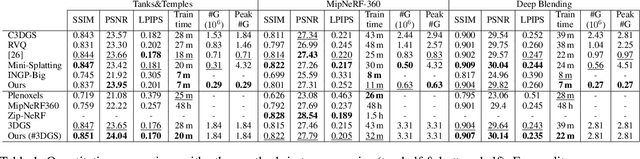
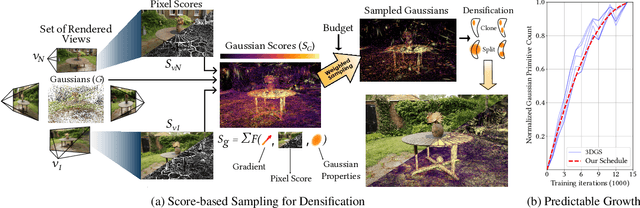
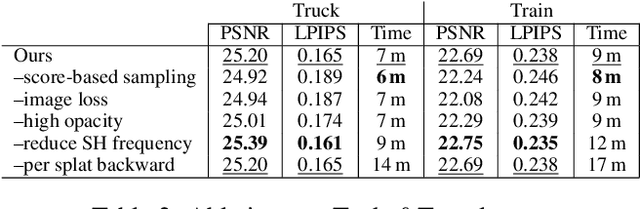
3D Gaussian Splatting (3DGS) has transformed novel-view synthesis with its fast, interpretable, and high-fidelity rendering. However, its resource requirements limit its usability. Especially on constrained devices, training performance degrades quickly and often cannot complete due to excessive memory consumption of the model. The method converges with an indefinite number of Gaussians -- many of them redundant -- making rendering unnecessarily slow and preventing its usage in downstream tasks that expect fixed-size inputs. To address these issues, we tackle the challenges of training and rendering 3DGS models on a budget. We use a guided, purely constructive densification process that steers densification toward Gaussians that raise the reconstruction quality. Model size continuously increases in a controlled manner towards an exact budget, using score-based densification of Gaussians with training-time priors that measure their contribution. We further address training speed obstacles: following a careful analysis of 3DGS' original pipeline, we derive faster, numerically equivalent solutions for gradient computation and attribute updates, including an alternative parallelization for efficient backpropagation. We also propose quality-preserving approximations where suitable to reduce training time even further. Taken together, these enhancements yield a robust, scalable solution with reduced training times, lower compute and memory requirements, and high quality. Our evaluation shows that in a budgeted setting, we obtain competitive quality metrics with 3DGS while achieving a 4--5x reduction in both model size and training time. With more generous budgets, our measured quality surpasses theirs. These advances open the door for novel-view synthesis in constrained environments, e.g., mobile devices.
GSN: Generalisable Segmentation in Neural Radiance Field
Feb 07, 2024


Traditional Radiance Field (RF) representations capture details of a specific scene and must be trained afresh on each scene. Semantic feature fields have been added to RFs to facilitate several segmentation tasks. Generalised RF representations learn the principles of view interpolation. A generalised RF can render new views of an unknown and untrained scene, given a few views. We present a way to distil feature fields into the generalised GNT representation. Our GSN representation generates new views of unseen scenes on the fly along with consistent, per-pixel semantic features. This enables multi-view segmentation of arbitrary new scenes. We show different semantic features being distilled into generalised RFs. Our multi-view segmentation results are on par with methods that use traditional RFs. GSN closes the gap between standard and generalisable RF methods significantly. Project Page: https://vinayak-vg.github.io/GSN/
FusedRF: Fusing Multiple Radiance Fields
Jun 07, 2023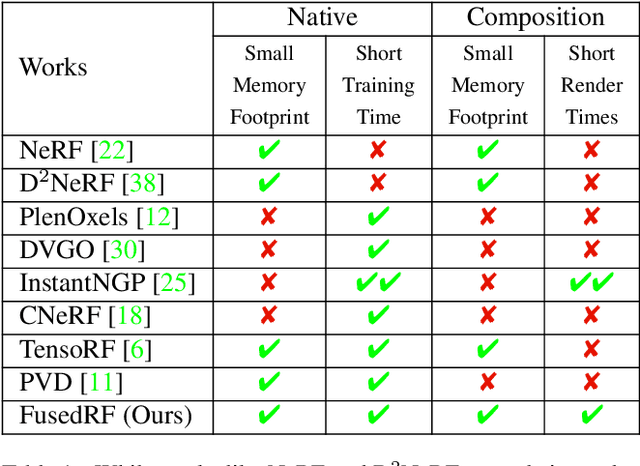
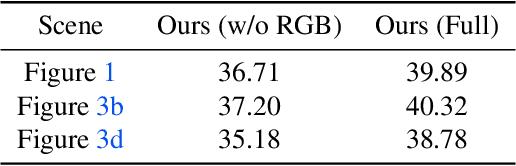
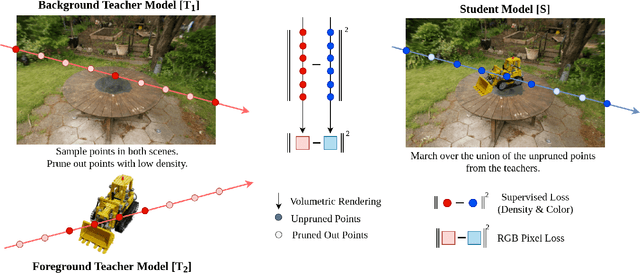

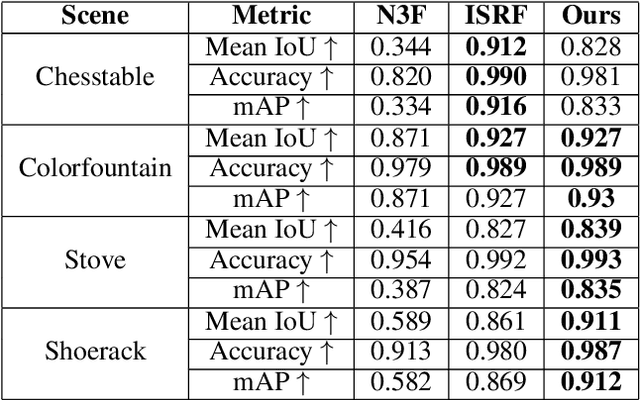
Radiance Fields (RFs) have shown great potential to represent scenes from casually captured discrete views. Compositing parts or whole of multiple captured scenes could greatly interest several XR applications. Prior works can generate new views of such scenes by tracing each scene in parallel. This increases the render times and memory requirements with the number of components. In this work, we provide a method to create a single, compact, fused RF representation for a scene composited using multiple RFs. The fused RF has the same render times and memory utilizations as a single RF. Our method distills information from multiple teacher RFs into a single student RF while also facilitating further manipulations like addition and deletion into the fused representation.
PRESTO: A Multilingual Dataset for Parsing Realistic Task-Oriented Dialogs
Mar 17, 2023



Research interest in task-oriented dialogs has increased as systems such as Google Assistant, Alexa and Siri have become ubiquitous in everyday life. However, the impact of academic research in this area has been limited by the lack of datasets that realistically capture the wide array of user pain points. To enable research on some of the more challenging aspects of parsing realistic conversations, we introduce PRESTO, a public dataset of over 550K contextual multilingual conversations between humans and virtual assistants. PRESTO contains a diverse array of challenges that occur in real-world NLU tasks such as disfluencies, code-switching, and revisions. It is the only large scale human generated conversational parsing dataset that provides structured context such as a user's contacts and lists for each example. Our mT5 model based baselines demonstrate that the conversational phenomenon present in PRESTO are challenging to model, which is further pronounced in a low-resource setup.
Predicting Socio-Economic Well-being Using Mobile Apps Data: A Case Study of France
Jan 15, 2023Socio-economic indicators provide context for assessing a country's overall condition. These indicators contain information about education, gender, poverty, employment, and other factors. Therefore, reliable and accurate information is critical for social research and government policing. Most data sources available today, such as censuses, have sparse population coverage or are updated infrequently. Nonetheless, alternative data sources, such as call data records (CDR) and mobile app usage, can serve as cost-effective and up-to-date sources for identifying socio-economic indicators. This work investigates mobile app data to predict socio-economic features. We present a large-scale study using data that captures the traffic of thousands of mobile applications by approximately 30 million users distributed over 550,000 km square and served by over 25,000 base stations. The dataset covers the whole France territory and spans more than 2.5 months, starting from 16th March 2019 to 6th June 2019. Using the app usage patterns, our best model can estimate socio-economic indicators (attaining an R-squared score upto 0.66). Furthermore, using models' explainability, we discover that mobile app usage patterns have the potential to reveal socio-economic disparities in IRIS. Insights of this study provide several avenues for future interventions, including users' temporal network analysis and exploration of alternative data sources.
Interactive Segmentation of Radiance Fields
Dec 27, 2022
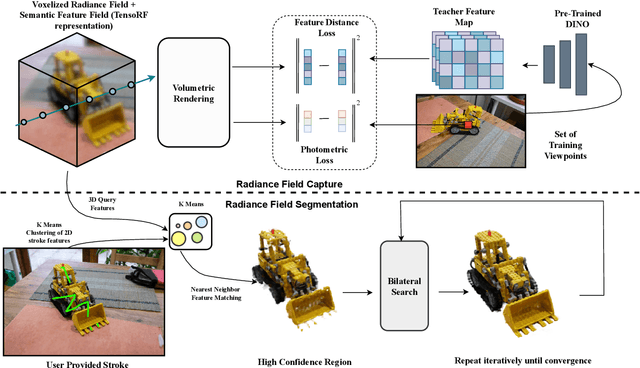
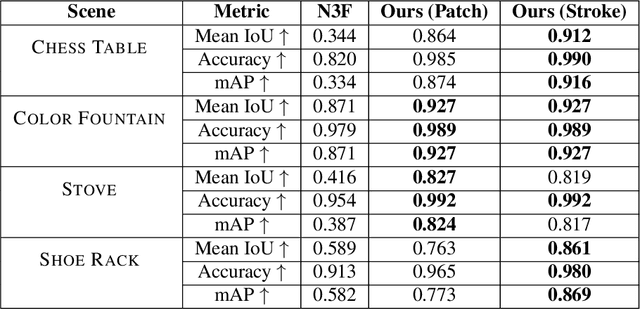

Radiance Fields (RF) are popular to represent casually-captured scenes for new view generation and have been used for applications beyond it. Understanding and manipulating scenes represented as RFs have to naturally follow to facilitate mixed reality on personal spaces. Semantic segmentation of objects in the 3D scene is an important step for that. Prior segmentation efforts using feature distillation show promise but don't scale to complex objects with diverse appearance. We present a framework to interactively segment objects with fine structure. Nearest neighbor feature matching identifies high-confidence regions of the objects using distilled features. Bilateral filtering in a joint spatio-semantic space grows the region to recover accurate segmentation. We show state-of-the-art results of segmenting objects from RFs and compositing them to another scene, changing appearance, etc., moving closer to rich scene manipulation and understanding. Project Page: https://rahul-goel.github.io/isrf/
StyleTRF: Stylizing Tensorial Radiance Fields
Dec 19, 2022Stylized view generation of scenes captured casually using a camera has received much attention recently. The geometry and appearance of the scene are typically captured as neural point sets or neural radiance fields in the previous work. An image stylization method is used to stylize the captured appearance by training its network jointly or iteratively with the structure capture network. The state-of-the-art SNeRF method trains the NeRF and stylization network in an alternating manner. These methods have high training time and require joint optimization. In this work, we present StyleTRF, a compact, quick-to-optimize strategy for stylized view generation using TensoRF. The appearance part is fine-tuned using sparse stylized priors of a few views rendered using the TensoRF representation for a few iterations. Our method thus effectively decouples style-adaption from view capture and is much faster than the previous methods. We show state-of-the-art results on several scenes used for this purpose.
DAMP: Doubly Aligned Multilingual Parser for Task-Oriented Dialogue
Dec 15, 2022Modern virtual assistants use internal semantic parsing engines to convert user utterances to actionable commands. However, prior work has demonstrated that semantic parsing is a difficult multilingual transfer task with low transfer efficiency compared to other tasks. In global markets such as India and Latin America, this is a critical issue as switching between languages is prevalent for bilingual users. In this work we dramatically improve the zero-shot performance of a multilingual and codeswitched semantic parsing system using two stages of multilingual alignment. First, we show that constrastive alignment pretraining improves both English performance and transfer efficiency. We then introduce a constrained optimization approach for hyperparameter-free adversarial alignment during finetuning. Our Doubly Aligned Multilingual Parser (DAMP) improves mBERT transfer performance by 3x, 6x, and 81x on the Spanglish, Hinglish and Multilingual Task Oriented Parsing benchmarks respectively and outperforms XLM-R and mT5-Large using 3.2x fewer parameters.
CST5: Data Augmentation for Code-Switched Semantic Parsing
Nov 14, 2022
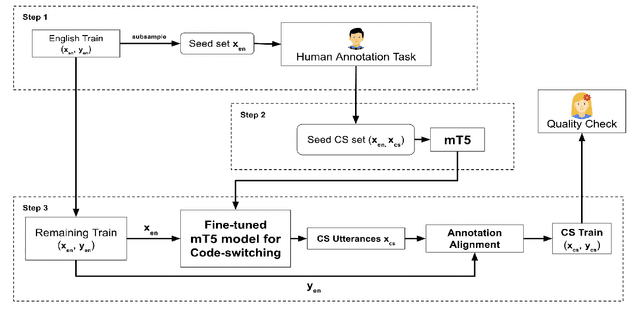
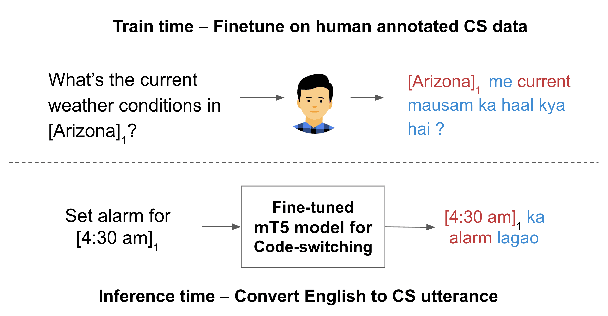

Extending semantic parsers to code-switched input has been a challenging problem, primarily due to a lack of supervised training data. In this work, we introduce CST5, a new data augmentation technique that finetunes a T5 model using a small seed set ($\approx$100 utterances) to generate code-switched utterances from English utterances. We show that CST5 generates high quality code-switched data, both intrinsically (per human evaluation) and extrinsically by comparing baseline models which are trained without data augmentation to models which are trained with augmented data. Empirically we observe that using CST5, one can achieve the same semantic parsing performance by using up to 20x less labeled data. To aid further research in this area, we are also releasing (a) Hinglish-TOP, the largest human annotated code-switched semantic parsing dataset to date, containing 10k human annotated Hindi-English (Hinglish) code-switched utterances, and (b) Over 170K CST5 generated code-switched utterances from the TOPv2 dataset. Human evaluation shows that both the human annotated data as well as the CST5 generated data is of good quality.