 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Ambient Scene Dynamics for Free-view Synthesis
Jun 13, 2024



We introduce a novel method for dynamic free-view synthesis of an ambient scenes from a monocular capture bringing a immersive quality to the viewing experience. Our method builds upon the recent advancements in 3D Gaussian Splatting (3DGS) that can faithfully reconstruct complex static scenes. Previous attempts to extend 3DGS to represent dynamics have been confined to bounded scenes or require multi-camera captures, and often fail to generalize to unseen motions, limiting their practical application. Our approach overcomes these constraints by leveraging the periodicity of ambient motions to learn the motion trajectory model, coupled with careful regularization. We also propose important practical strategies to improve the visual quality of the baseline 3DGS static reconstructions and to improve memory efficiency critical for GPU-memory intensive learning. We demonstrate high-quality photorealistic novel view synthesis of several ambient natural scenes with intricate textures and fine structural elements.
FusedRF: Fusing Multiple Radiance Fields
Jun 07, 2023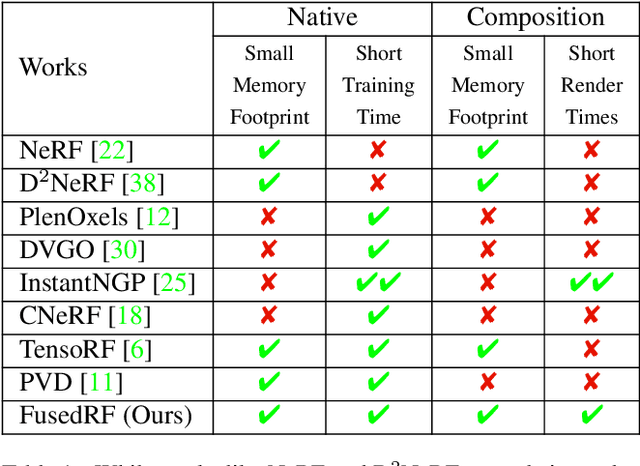
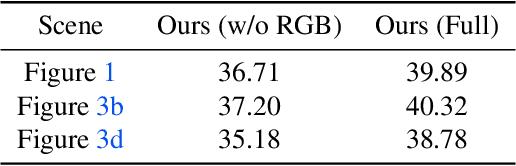
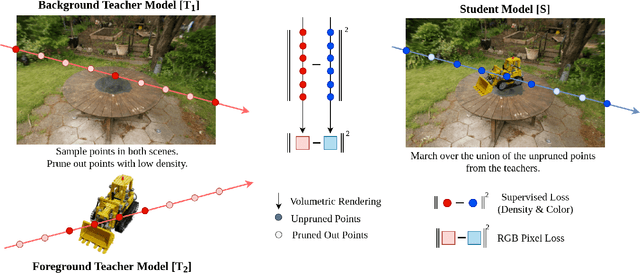

Radiance Fields (RFs) have shown great potential to represent scenes from casually captured discrete views. Compositing parts or whole of multiple captured scenes could greatly interest several XR applications. Prior works can generate new views of such scenes by tracing each scene in parallel. This increases the render times and memory requirements with the number of components. In this work, we provide a method to create a single, compact, fused RF representation for a scene composited using multiple RFs. The fused RF has the same render times and memory utilizations as a single RF. Our method distills information from multiple teacher RFs into a single student RF while also facilitating further manipulations like addition and deletion into the fused representation.
Long-term Visual Map Sparsification with Heterogeneous GNN
Mar 29, 2022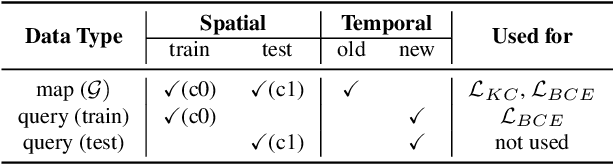
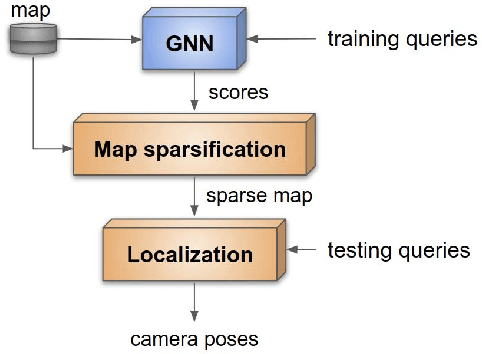
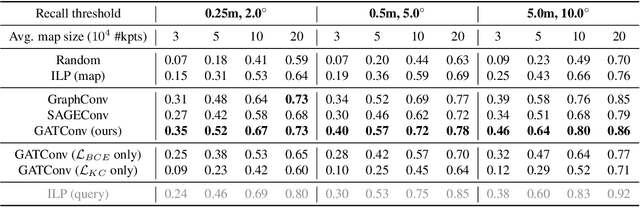
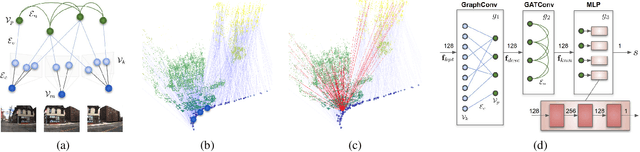
We address the problem of map sparsification for long-term visual localization. For map sparsification, a commonly employed assumption is that the pre-build map and the later captured localization query are consistent. However, this assumption can be easily violated in the dynamic world. Additionally, the map size grows as new data accumulate through time, causing large data overhead in the long term. In this paper, we aim to overcome the environmental changes and reduce the map size at the same time by selecting points that are valuable to future localization. Inspired by the recent progress in Graph Neural Network(GNN), we propose the first work that models SfM maps as heterogeneous graphs and predicts 3D point importance scores with a GNN, which enables us to directly exploit the rich information in the SfM map graph. Two novel supervisions are proposed: 1) a data-fitting term for selecting valuable points to future localization based on training queries; 2) a K-Cover term for selecting sparse points with full map coverage. The experiments show that our method selected map points on stable and widely visible structures and outperformed baselines in localization performance.
Analysis and Mitigations of Reverse Engineering Attacks on Local Feature Descriptors
May 09, 2021
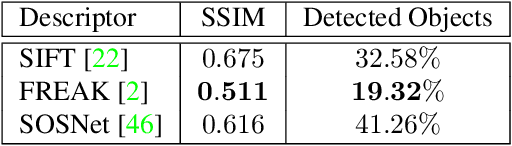
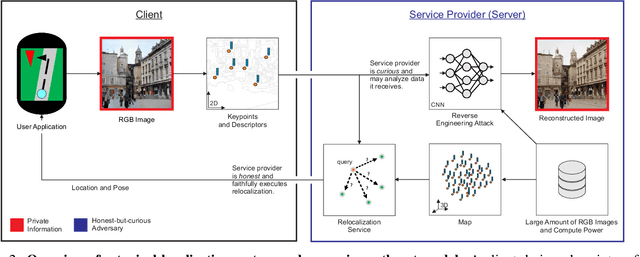
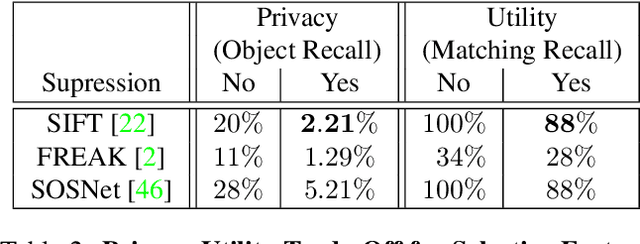
As autonomous driving and augmented reality evolve, a practical concern is data privacy. In particular, these applications rely on localization based on user images. The widely adopted technology uses local feature descriptors, which are derived from the images and it was long thought that they could not be reverted back. However, recent work has demonstrated that under certain conditions reverse engineering attacks are possible and allow an adversary to reconstruct RGB images. This poses a potential risk to user privacy. We take this a step further and model potential adversaries using a privacy threat model. Subsequently, we show under controlled conditions a reverse engineering attack on sparse feature maps and analyze the vulnerability of popular descriptors including FREAK, SIFT and SOSNet. Finally, we evaluate potential mitigation techniques that select a subset of descriptors to carefully balance privacy reconstruction risk while preserving image matching accuracy; our results show that similar accuracy can be obtained when revealing less information.
A Unified View-Graph Selection Framework for Structure from Motion
Dec 04, 2017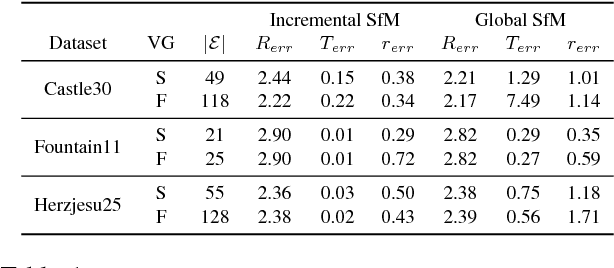

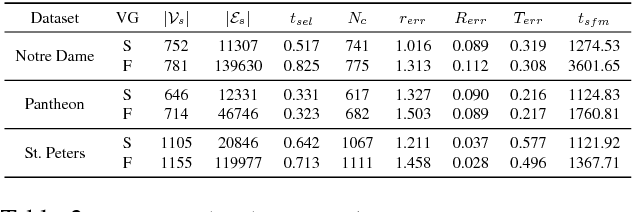
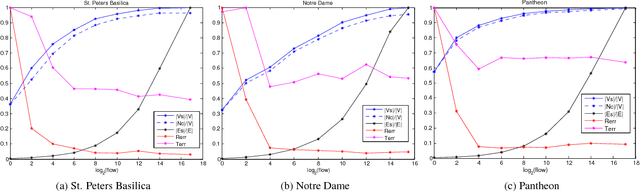
View-graph is an essential input to large-scale structure from motion (SfM) pipelines. Accuracy and efficiency of large-scale SfM is crucially dependent on the input view-graph. Inconsistent or inaccurate edges can lead to inferior or wrong reconstruction. Most SfM methods remove `undesirable' images and pairs using several, fixed heuristic criteria, and propose tailor-made solutions to achieve specific reconstruction objectives such as efficiency, accuracy, or disambiguation. In contrast to these disparate solutions, we propose a single optimization framework that can be used to achieve these different reconstruction objectives with task-specific cost modeling. We also construct a very efficient network-flow based formulation for its approximate solution. The abstraction brought on by this selection mechanism separates the challenges specific to datasets and reconstruction objectives from the standard SfM pipeline and improves its generalization. This paper demonstrates the application of the proposed view-graph framework with standard SfM pipeline for two particular use-cases, (i) accurate and ghost-free reconstructions of highly ambiguous datasets using costs based on disambiguation priors, and (ii) accurate and efficient reconstruction of large-scale Internet datasets using costs based on commonly used priors.
Learning to Hash-tag Videos with Tag2Vec
Dec 13, 2016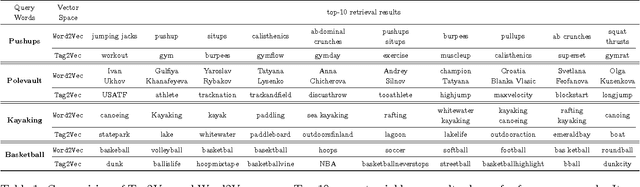
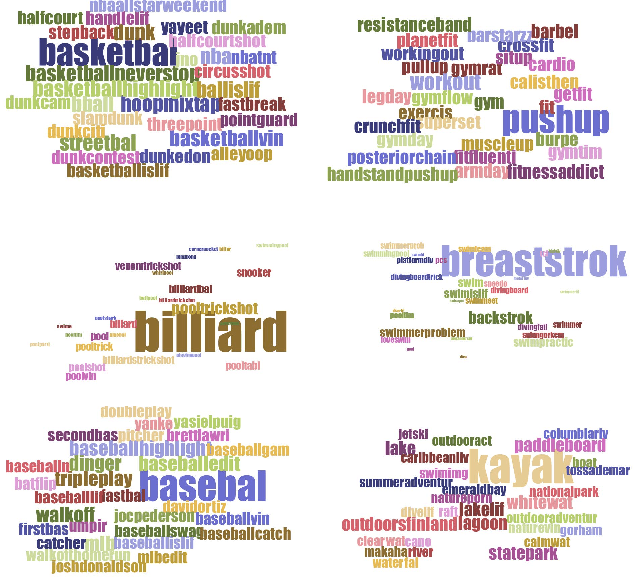

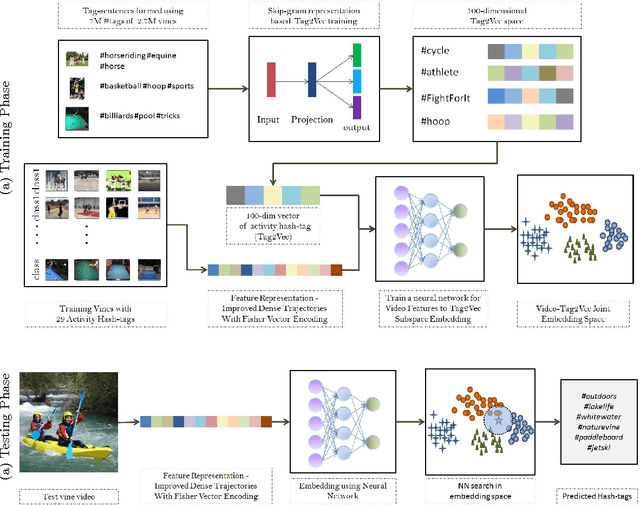
User-given tags or labels are valuable resources for semantic understanding of visual media such as images and videos. Recently, a new type of labeling mechanism known as hash-tags have become increasingly popular on social media sites. In this paper, we study the problem of generating relevant and useful hash-tags for short video clips. Traditional data-driven approaches for tag enrichment and recommendation use direct visual similarity for label transfer and propagation. We attempt to learn a direct low-cost mapping from video to hash-tags using a two step training process. We first employ a natural language processing (NLP) technique, skip-gram models with neural network training to learn a low-dimensional vector representation of hash-tags (Tag2Vec) using a corpus of 10 million hash-tags. We then train an embedding function to map video features to the low-dimensional Tag2vec space. We learn this embedding for 29 categories of short video clips with hash-tags. A query video without any tag-information can then be directly mapped to the vector space of tags using the learned embedding and relevant tags can be found by performing a simple nearest-neighbor retrieval in the Tag2Vec space. We validate the relevance of the tags suggested by our system qualitatively and quantitatively with a user study.
From Traditional to Modern : Domain Adaptation for Action Classification in Short Social Video Clips
Oct 18, 2016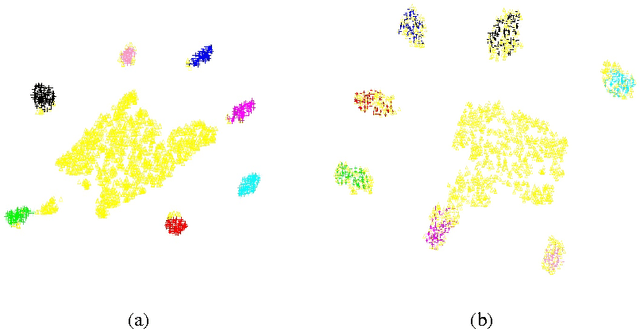


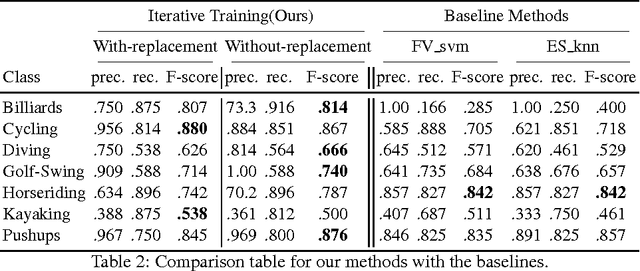
Short internet video clips like vines present a significantly wild distribution compared to traditional video datasets. In this paper, we focus on the problem of unsupervised action classification in wild vines using traditional labeled datasets. To this end, we use a data augmentation based simple domain adaptation strategy. We utilise semantic word2vec space as a common subspace to embed video features from both, labeled source domain and unlablled target domain. Our method incrementally augments the labeled source with target samples and iteratively modifies the embedding function to bring the source and target distributions together. Additionally, we utilise a multi-modal representation that incorporates noisy semantic information available in form of hash-tags. We show the effectiveness of this simple adaptation technique on a test set of vines and achieve notable improvements in performance.
* 9 pages, GCPR, 2016
Multistage SFM: A Coarse-to-Fine Approach for 3D Reconstruction
Oct 12, 2016

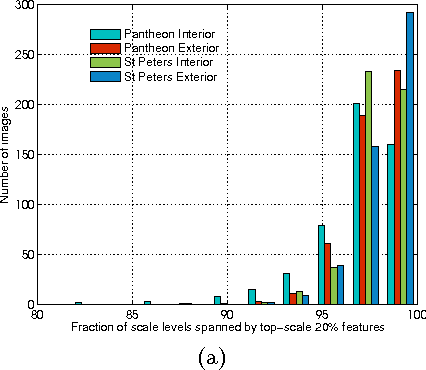
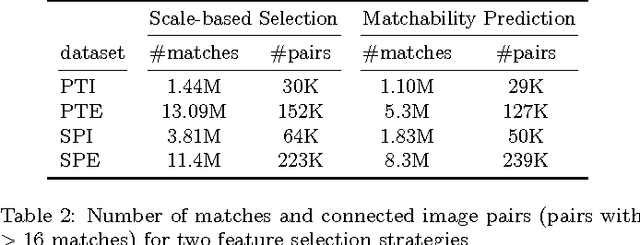
Several methods have been proposed for large-scale 3D reconstruction from large, unorganized image collections. A large reconstruction problem is typically divided into multiple components which are reconstructed independently using structure from motion (SFM) and later merged together. Incremental SFM methods are most popular for the basic structure recovery of a single component. They are robust and effective but are strictly sequential in nature. We present a multistage approach for SFM reconstruction of a single component that breaks the sequential nature of the incremental SFM methods. Our approach begins with quickly building a coarse 3D model using only a fraction of features from given images. The coarse model is then enriched by localizing remaining images and matching and triangulating remaining features in subsequent stages. These stages are made efficient and highly parallel by leveraging the geometry of the coarse model. Our method produces similar quality models as compared to incremental SFM methods while being notably fast and parallel.