 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensor2Sensor: Cross-Embodiment Sensor Conversion for Autonomous Driving
May 21, 2026Robust training and validation of Autonomous Driving Systems (ADS) require massive, diverse datasets. Proprietary data collected by Autonomous Vehicle (AV) fleets, while high-fidelity, are limited in scale, diversity of sensor configurations, as well as geographic and long-tail-behavioral coverage. In contrast, in-the-wild data from sources like dashcams offers immense scale and diversity, capturing critical long-tail scenarios and novel environments. However, this unstructured, in-the-wild video data is incompatible with ADS expecting structured, multi-modal sensor inputs for validation and training. To bridge this data gap, we propose Sensor2Sensor, a novel generative modeling paradigm that translates in-the-wild monocular dashcam videos into a high-fidelity, multi-modal sensor suite (AV logs) comprising multi-view camera images and LiDAR point clouds. A core challenge is the lack of paired training data. We address this by converting real AV logs into dashcam-style videos via 4D Gaussian Splatting (4DGS) reconstruction and novel-view rendering. Sensor2Sensor then utilizes a diffusion architecture to perform the generative conversion. We perform comprehensive quantitative evaluations on the fidelity and realism of the generated sensor data. We demonstrate Sensor2Sensor's practical utility by converting challenging in-the-wild internet and dashcam footage into realistic, multi-modal data formats, further unlocking vast external data sources for AV development.
Prior-Enhanced Gaussian Splatting for Dynamic Scene Reconstruction from Casual Video
Dec 12, 2025We introduce a fully automatic pipeline for dynamic scene reconstruction from casually captured monocular RGB videos. Rather than designing a new scene representation, we enhance the priors that drive Dynamic Gaussian Splatting. Video segmentation combined with epipolar-error maps yields object-level masks that closely follow thin structures; these masks (i) guide an object-depth loss that sharpens the consistent video depth, and (ii) support skeleton-based sampling plus mask-guided re-identification to produce reliable, comprehensive 2-D tracks. Two additional objectives embed the refined priors in the reconstruction stage: a virtual-view depth loss removes floaters, and a scaffold-projection loss ties motion nodes to the tracks, preserving fine geometry and coherent motion. The resulting system surpasses previous monocular dynamic scene reconstruction methods and delivers visibly superior renderings
Modeling Ambient Scene Dynamics for Free-view Synthesis
Jun 13, 2024



We introduce a novel method for dynamic free-view synthesis of an ambient scenes from a monocular capture bringing a immersive quality to the viewing experience. Our method builds upon the recent advancements in 3D Gaussian Splatting (3DGS) that can faithfully reconstruct complex static scenes. Previous attempts to extend 3DGS to represent dynamics have been confined to bounded scenes or require multi-camera captures, and often fail to generalize to unseen motions, limiting their practical application. Our approach overcomes these constraints by leveraging the periodicity of ambient motions to learn the motion trajectory model, coupled with careful regularization. We also propose important practical strategies to improve the visual quality of the baseline 3DGS static reconstructions and to improve memory efficiency critical for GPU-memory intensive learning. We demonstrate high-quality photorealistic novel view synthesis of several ambient natural scenes with intricate textures and fine structural elements.
ExtraNeRF: Visibility-Aware View Extrapolation of Neural Radiance Fields with Diffusion Models
Jun 10, 2024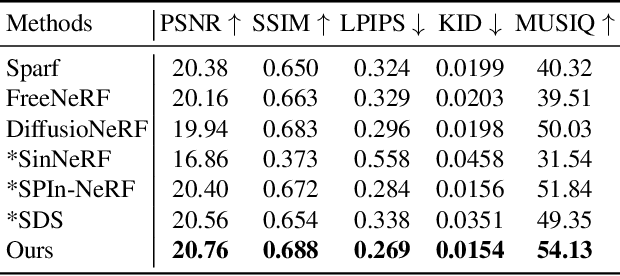
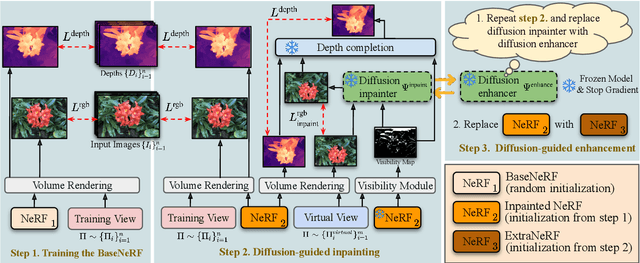
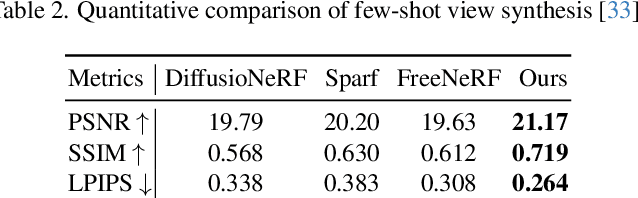
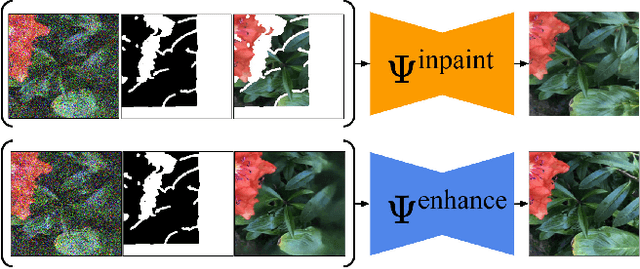
We propose ExtraNeRF, a novel method for extrapolating the range of views handled by a Neural Radiance Field (NeRF). Our main idea is to leverage NeRFs to model scene-specific, fine-grained details, while capitalizing on diffusion models to extrapolate beyond our observed data. A key ingredient is to track visibility to determine what portions of the scene have not been observed, and focus on reconstructing those regions consistently with diffusion models. Our primary contributions include a visibility-aware diffusion-based inpainting module that is fine-tuned on the input imagery, yielding an initial NeRF with moderate quality (often blurry) inpainted regions, followed by a second diffusion model trained on the input imagery to consistently enhance, notably sharpen, the inpainted imagery from the first pass. We demonstrate high-quality results, extrapolating beyond a small number of (typically six or fewer) input views, effectively outpainting the NeRF as well as inpainting newly disoccluded regions inside the original viewing volume. We compare with related work both quantitatively and qualitatively and show significant gains over prior art.
3D Photography using Context-aware Layered Depth Inpainting
Apr 14, 2020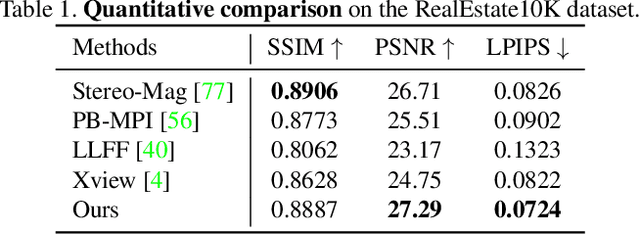
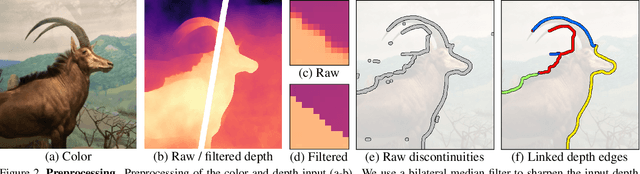
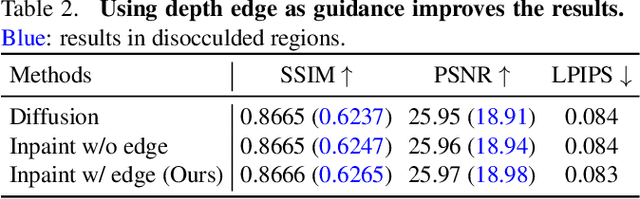

We propose a method for converting a single RGB-D input image into a 3D photo - a multi-layer representation for novel view synthesis that contains hallucinated color and depth structures in regions occluded in the original view. We use a Layered Depth Image with explicit pixel connectivity as underlying representation, and present a learning-based inpainting model that synthesizes new local color-and-depth content into the occluded region in a spatial context-aware manner. The resulting 3D photos can be efficiently rendered with motion parallax using standard graphics engines. We validate the effectiveness of our method on a wide range of challenging everyday scenes and show fewer artifacts compared with the state of the arts.
Self-Supervised Learning of Depth and Camera Motion from 360° Videos
Nov 13, 2018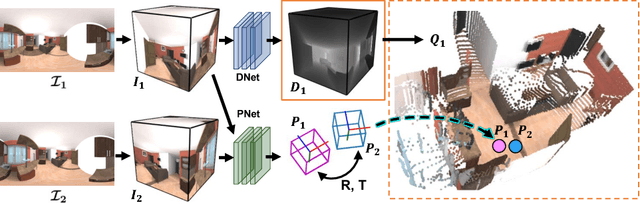
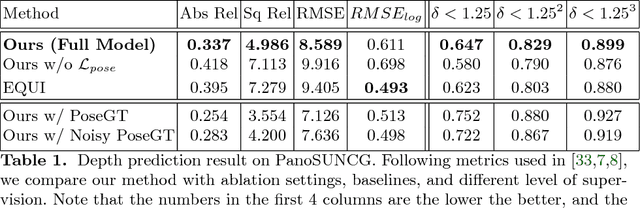
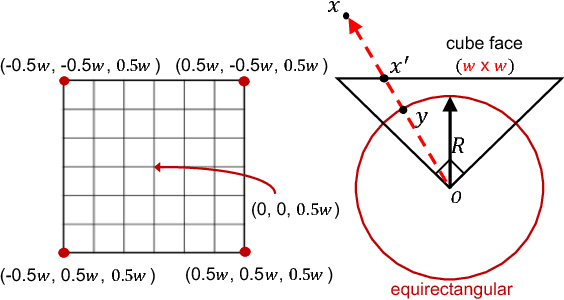
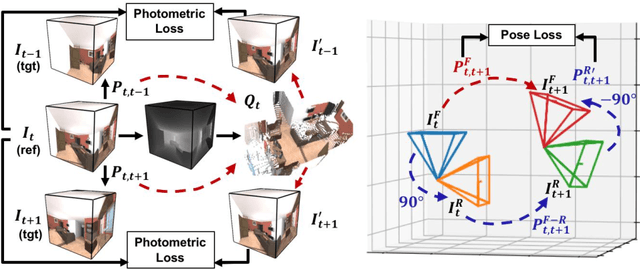
As 360{\deg} cameras become prevalent in many autonomous systems (e.g., self-driving cars and drones), efficient 360{\deg} perception becomes more and more important. We propose a novel self-supervised learning approach for predicting the omnidirectional depth and camera motion from a 360{\deg} video. In particular, starting from the SfMLearner, which is designed for cameras with normal field-of-view, we introduce three key features to process 360{\deg} images efficiently. Firstly, we convert each image from equirectangular projection to cubic projection in order to avoid image distortion. In each network layer, we use Cube Padding (CP), which pads intermediate features from adjacent faces, to avoid image boundaries. Secondly, we propose a novel "spherical" photometric consistency constraint on the whole viewing sphere. In this way, no pixel will be projected outside the image boundary which typically happens in images with normal field-of-view. Finally, rather than naively estimating six independent camera motions (i.e., naively applying SfM-Learner to each face on a cube), we propose a novel camera pose consistency loss to ensure the estimated camera motions reaching consensus. To train and evaluate our approach, we collect a new PanoSUNCG dataset containing a large amount of 360{\deg} videos with groundtruth depth and camera motion. Our approach achieves state-of-the-art depth prediction and camera motion estimation on PanoSUNCG with faster inference speed comparing to equirectangular. In real-world indoor videos, our approach can also achieve qualitatively reasonable depth prediction by acquiring model pre-trained on PanoSUNCG.
Tactics of Adversarial Attack on Deep Reinforcement Learning Agents
May 23, 2017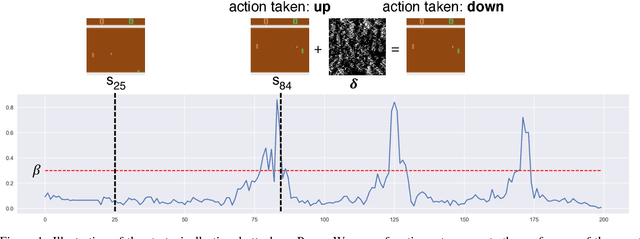
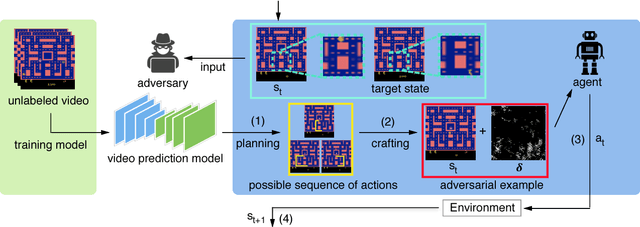

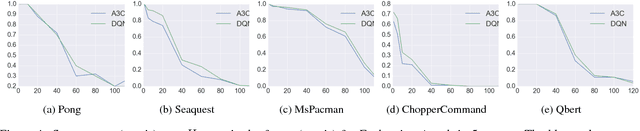
We introduce two tactics to attack agents trained by deep reinforcement learning algorithms using adversarial examples, namely the strategically-timed attack and the enchanting attack. In the strategically-timed attack, the adversary aims at minimizing the agent's reward by only attacking the agent at a small subset of time steps in an episode. Limiting the attack activity to this subset helps prevent detection of the attack by the agent. We propose a novel method to determine when an adversarial example should be crafted and applied. In the enchanting attack, the adversary aims at luring the agent to a designated target state. This is achieved by combining a generative model and a planning algorithm: while the generative model predicts the future states, the planning algorithm generates a preferred sequence of actions for luring the agent. A sequence of adversarial examples is then crafted to lure the agent to take the preferred sequence of actions. We apply the two tactics to the agents trained by the state-of-the-art deep reinforcement learning algorithm including DQN and A3C. In 5 Atari games, our strategically timed attack reduces as much reward as the uniform attack (i.e., attacking at every time step) does by attacking the agent 4 times less often. Our enchanting attack lures the agent toward designated target states with a more than 70% success rate. Videos are available at http://yclin.me/adversarial_attack_RL/