 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
Jan 22, 2026Recent video generation models demonstrate remarkable ability to capture complex physical interactions and scene evolution over time. To leverage their spatiotemporal priors, robotics works have adapted video models for policy learning but introduce complexity by requiring multiple stages of post-training and new architectural components for action generation. In this work, we introduce Cosmos Policy, a simple approach for adapting a large pretrained video model (Cosmos-Predict2) into an effective robot policy through a single stage of post-training on the robot demonstration data collected on the target platform, with no architectural modifications. Cosmos Policy learns to directly generate robot actions encoded as latent frames within the video model's latent diffusion process, harnessing the model's pretrained priors and core learning algorithm to capture complex action distributions. Additionally, Cosmos Policy generates future state images and values (expected cumulative rewards), which are similarly encoded as latent frames, enabling test-time planning of action trajectories with higher likelihood of success. In our evaluations, Cosmos Policy achieves state-of-the-art performance on the LIBERO and RoboCasa simulation benchmarks (98.5% and 67.1% average success rates, respectively) and the highest average score in challenging real-world bimanual manipulation tasks, outperforming strong diffusion policies trained from scratch, video model-based policies, and state-of-the-art vision-language-action models fine-tuned on the same robot demonstrations. Furthermore, given policy rollout data, Cosmos Policy can learn from experience to refine its world model and value function and leverage model-based planning to achieve even higher success rates in challenging tasks. We release code, models, and training data at https://research.nvidia.com/labs/dir/cosmos-policy/
DreamGen: Unlocking Generalization in Robot Learning through Neural Trajectories
May 19, 2025We introduce DreamGen, a simple yet highly effective 4-stage pipeline for training robot policies that generalize across behaviors and environments through neural trajectories - synthetic robot data generated from video world models. DreamGen leverages state-of-the-art image-to-video generative models, adapting them to the target robot embodiment to produce photorealistic synthetic videos of familiar or novel tasks in diverse environments. Since these models generate only videos, we recover pseudo-action sequences using either a latent action model or an inverse-dynamics model (IDM). Despite its simplicity, DreamGen unlocks strong behavior and environment generalization: a humanoid robot can perform 22 new behaviors in both seen and unseen environments, while requiring teleoperation data from only a single pick-and-place task in one environment. To evaluate the pipeline systematically, we introduce DreamGen Bench, a video generation benchmark that shows a strong correlation between benchmark performance and downstream policy success. Our work establishes a promising new axis for scaling robot learning well beyond manual data collection.
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
Mar 18, 2025Physical AI systems need to perceive, understand, and perform complex actions in the physical world. In this paper, we present the Cosmos-Reason1 models that can understand the physical world and generate appropriate embodied decisions (e.g., next step action) in natural language through long chain-of-thought reasoning processes. We begin by defining key capabilities for Physical AI reasoning, with a focus on physical common sense and embodied reasoning. To represent physical common sense, we use a hierarchical ontology that captures fundamental knowledge about space, time, and physics. For embodied reasoning, we rely on a two-dimensional ontology that generalizes across different physical embodiments. Building on these capabilities, we develop two multimodal large language models, Cosmos-Reason1-8B and Cosmos-Reason1-56B. We curate data and train our models in four stages: vision pre-training, general supervised fine-tuning (SFT), Physical AI SFT, and Physical AI reinforcement learning (RL) as the post-training. To evaluate our models, we build comprehensive benchmarks for physical common sense and embodied reasoning according to our ontologies. Evaluation results show that Physical AI SFT and reinforcement learning bring significant improvements. To facilitate the development of Physical AI, we will make our code and pre-trained models available under the NVIDIA Open Model License at https://github.com/nvidia-cosmos/cosmos-reason1.
Embodied Red Teaming for Auditing Robotic Foundation Models
Nov 27, 2024

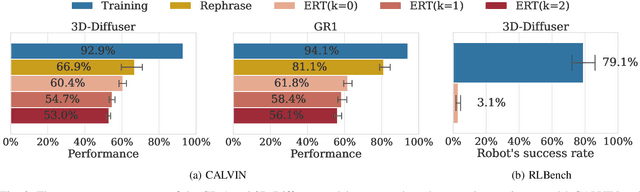
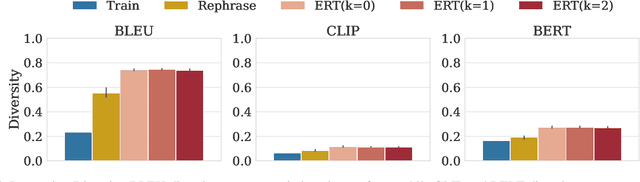
Language-conditioned robot models (i.e., robotic foundation models) enable robots to perform a wide range of tasks based on natural language instructions. Despite strong performance on existing benchmarks, evaluating the safety and effectiveness of these models is challenging due to the complexity of testing all possible language variations. Current benchmarks have two key limitations: they rely on a limited set of human-generated instructions, missing many challenging cases, and they focus only on task performance without assessing safety, such as avoiding damage. To address these gaps, we introduce Embodied Red Teaming (ERT), a new evaluation method that generates diverse and challenging instructions to test these models. ERT uses automated red teaming techniques with Vision Language Models (VLMs) to create contextually grounded, difficult instructions. Experimental results show that state-of-the-art models frequently fail or behave unsafely on ERT tests, underscoring the shortcomings of current benchmarks in evaluating real-world performance and safety. Code and videos are available at: https://sites.google.com/view/embodiedredteam.
Edify Image: High-Quality Image Generation with Pixel Space Laplacian Diffusion Models
Nov 11, 2024We introduce Edify Image, a family of diffusion models capable of generating photorealistic image content with pixel-perfect accuracy. Edify Image utilizes cascaded pixel-space diffusion models trained using a novel Laplacian diffusion process, in which image signals at different frequency bands are attenuated at varying rates. Edify Image supports a wide range of applications, including text-to-image synthesis, 4K upsampling, ControlNets, 360 HDR panorama generation, and finetuning for image customization.
Edify 3D: Scalable High-Quality 3D Asset Generation
Nov 11, 2024
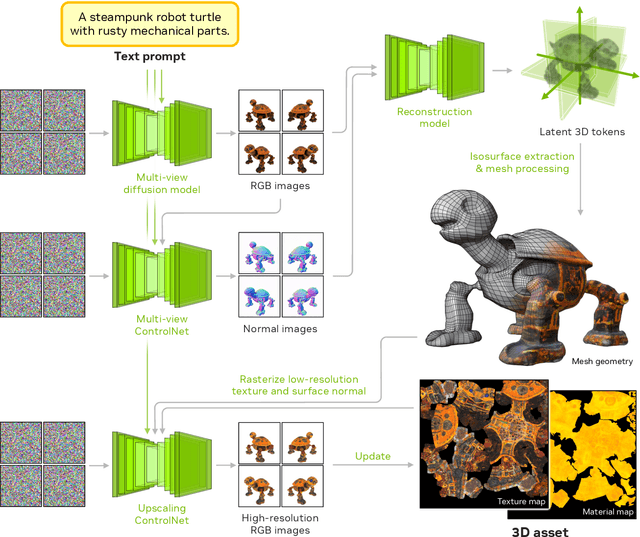
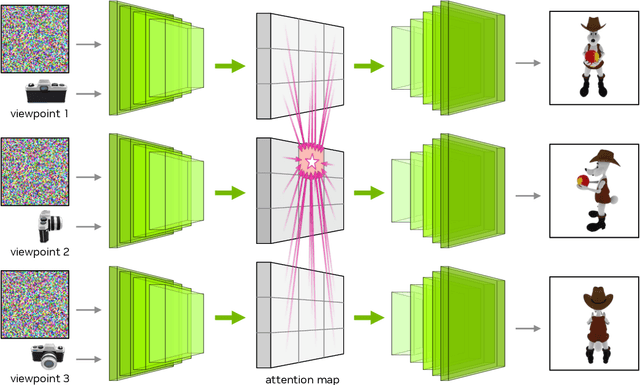

We introduce Edify 3D, an advanced solution designed for high-quality 3D asset generation. Our method first synthesizes RGB and surface normal images of the described object at multiple viewpoints using a diffusion model. The multi-view observations are then used to reconstruct the shape, texture, and PBR materials of the object. Our method can generate high-quality 3D assets with detailed geometry, clean shape topologies, high-resolution textures, and materials within 2 minutes of runtime.
Neural Fields in Robotics: A Survey
Oct 26, 2024



Neural Fields have emerged as a transformative approach for 3D scene representation in computer vision and robotics, enabling accurate inference of geometry, 3D semantics, and dynamics from posed 2D data. Leveraging differentiable rendering, Neural Fields encompass both continuous implicit and explicit neural representations enabling high-fidelity 3D reconstruction, integration of multi-modal sensor data, and generation of novel viewpoints. This survey explores their applications in robotics, emphasizing their potential to enhance perception, planning, and control. Their compactness, memory efficiency, and differentiability, along with seamless integration with foundation and generative models, make them ideal for real-time applications, improving robot adaptability and decision-making. This paper provides a thorough review of Neural Fields in robotics, categorizing applications across various domains and evaluating their strengths and limitations, based on over 200 papers. First, we present four key Neural Fields frameworks: Occupancy Networks, Signed Distance Fields, Neural Radiance Fields, and Gaussian Splatting. Second, we detail Neural Fields' applications in five major robotics domains: pose estimation, manipulation, navigation, physics, and autonomous driving, highlighting key works and discussing takeaways and open challenges. Finally, we outline the current limitations of Neural Fields in robotics and propose promising directions for future research. Project page: https://robonerf.github.io
Developing a Series of AI Challenges for the United States Department of the Air Force
Jul 14, 2022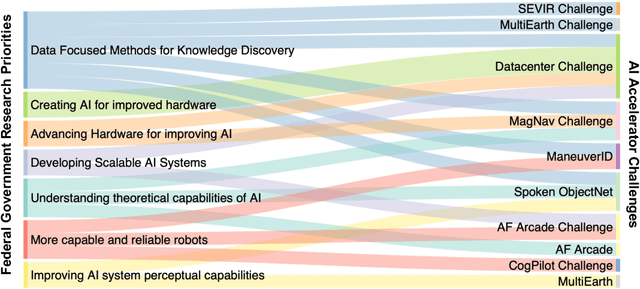

Through a series of federal initiatives and orders, the U.S. Government has been making a concerted effort to ensure American leadership in AI. These broad strategy documents have influenced organizations such as the United States Department of the Air Force (DAF). The DAF-MIT AI Accelerator is an initiative between the DAF and MIT to bridge the gap between AI researchers and DAF mission requirements. Several projects supported by the DAF-MIT AI Accelerator are developing public challenge problems that address numerous Federal AI research priorities. These challenges target priorities by making large, AI-ready datasets publicly available, incentivizing open-source solutions, and creating a demand signal for dual use technologies that can stimulate further research. In this article, we describe these public challenges being developed and how their application contributes to scientific advances.
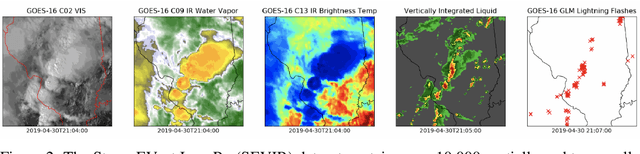
MultiEarth 2022 -- Multimodal Learning for Earth and Environment Workshop and Challenge
Apr 27, 2022


The Multimodal Learning for Earth and Environment Challenge (MultiEarth 2022) will be the first competition aimed at the monitoring and analysis of deforestation in the Amazon rainforest at any time and in any weather conditions. The goal of the Challenge is to provide a common benchmark for multimodal information processing and to bring together the earth and environmental science communities as well as multimodal representation learning communities to compare the relative merits of the various multimodal learning methods to deforestation estimation under well-defined and strictly comparable conditions. MultiEarth 2022 will have three sub-challenges: 1) matrix completion, 2) deforestation estimation, and 3) image-to-image translation. This paper presents the challenge guidelines, datasets, and evaluation metrics for the three sub-challenges. Our challenge website is available at https://sites.google.com/view/rainforest-challenge.
Topological Experience Replay
Mar 29, 2022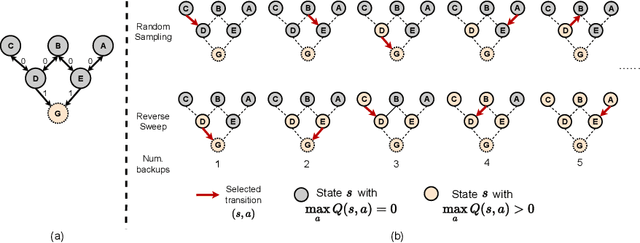
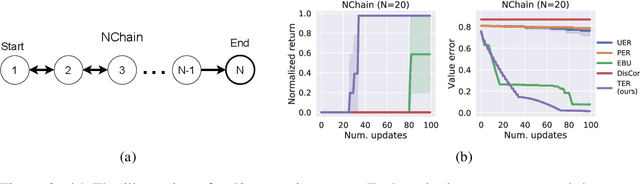
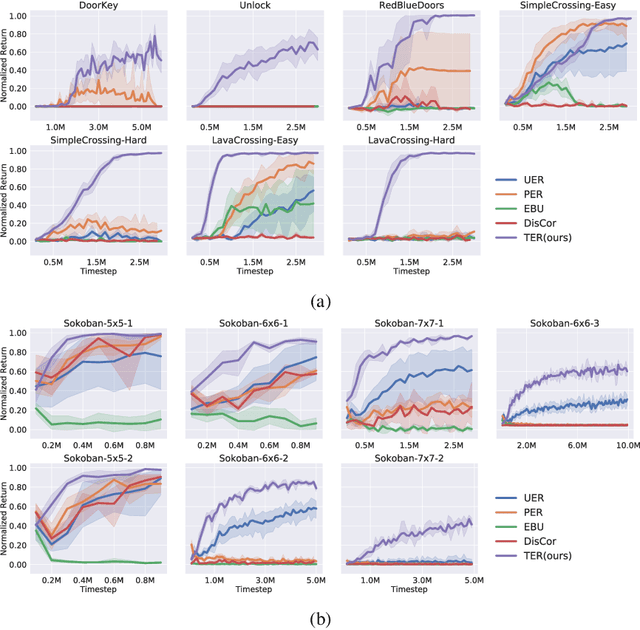
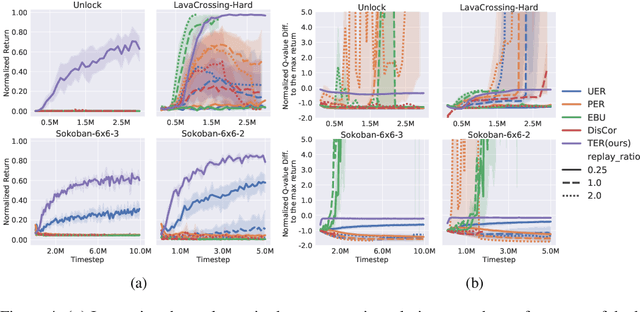
State-of-the-art deep Q-learning methods update Q-values using state transition tuples sampled from the experience replay buffer. This strategy often uniformly and randomly samples or prioritizes data sampling based on measures such as the temporal difference (TD) error. Such sampling strategies can be inefficient at learning Q-function because a state's Q-value depends on the Q-value of successor states. If the data sampling strategy ignores the precision of the Q-value estimate of the next state, it can lead to useless and often incorrect updates to the Q-values. To mitigate this issue, we organize the agent's experience into a graph that explicitly tracks the dependency between Q-values of states. Each edge in the graph represents a transition between two states by executing a single action. We perform value backups via a breadth-first search starting from that expands vertices in the graph starting from the set of terminal states and successively moving backward. We empirically show that our method is substantially more data-efficient than several baselines on a diverse range of goal-reaching tasks. Notably, the proposed method also outperforms baselines that consume more batches of training experience and operates from high-dimensional observational data such as images.