 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopological Experience Replay
Paper and Code
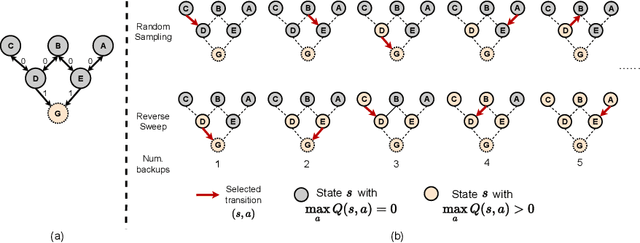
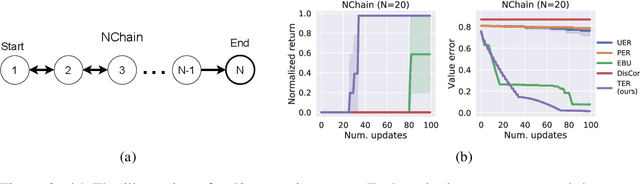
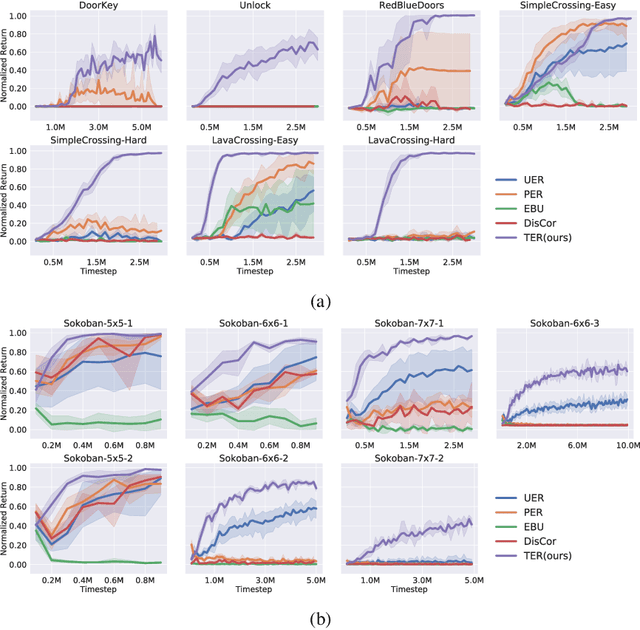
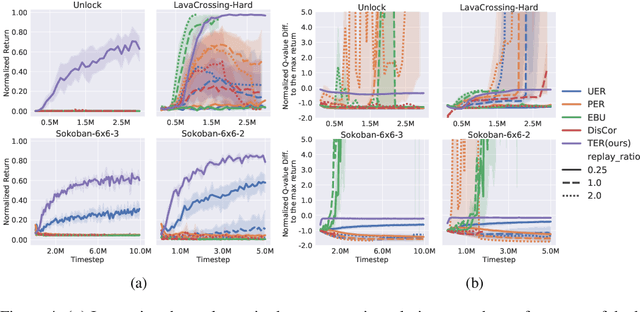
State-of-the-art deep Q-learning methods update Q-values using state transition tuples sampled from the experience replay buffer. This strategy often uniformly and randomly samples or prioritizes data sampling based on measures such as the temporal difference (TD) error. Such sampling strategies can be inefficient at learning Q-function because a state's Q-value depends on the Q-value of successor states. If the data sampling strategy ignores the precision of the Q-value estimate of the next state, it can lead to useless and often incorrect updates to the Q-values. To mitigate this issue, we organize the agent's experience into a graph that explicitly tracks the dependency between Q-values of states. Each edge in the graph represents a transition between two states by executing a single action. We perform value backups via a breadth-first search starting from that expands vertices in the graph starting from the set of terminal states and successively moving backward. We empirically show that our method is substantially more data-efficient than several baselines on a diverse range of goal-reaching tasks. Notably, the proposed method also outperforms baselines that consume more batches of training experience and operates from high-dimensional observational data such as images.