 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Matters When Cotraining Robot Manipulation Policies on Everyday Human Videos?
Jun 04, 2026Human video datasets used for cotraining robot manipulation policies largely consist of curated demonstrations where motions are orchestrated to resemble robot behavior and 3D hand poses are captured with specialized hardware. A more plentiful source of data is everyday Internet video, but it is an open question what factors enable transfer from such videos to robots. We investigate this using a new dataset of 532 human videos with 28 hours of high-quality triangulated hand labels and natural motions. We find that hand pose quality affects transfer, but even with accurate hands, the inherent motion gap hinders transfer unless the vision and policy networks specialize to each embodiment. Our cotraining recipe yields consistent improvements, with an absolute success rate gain of $29.7\%$ in the low-robot-data regime across six manipulation tasks.
Fine-Tuning and Serving Gemma 4 31B on Google Cloud TPU: A Technical Comparison with GPU Baselines
May 25, 2026We present the first end-to-end demonstration of fine-tuning and serving Google's Gemma 4 31B model on TPU hardware, providing an empirical comparison of TPU and GPU platforms for large language model adaptation. Using LoRA on a Google TPU v5p-8 for training and TPU v6e-8 (Trillium) for inference, we document the full set of code-level adaptations required to port a GPU-native training recipe, built on PyTorch, HuggingFace TRL, and FSDP, to the JAX + Tunix/Qwix stack. These adaptations span mesh configuration, LoRA module naming conventions, sharding annotation corrections, gradient checkpointing, data pipeline restructuring, and a custom Orbax-to-safetensors checkpoint merging procedure. For inference, we detail the vLLM-TPU Docker setup necessary to serve Gemma 4 on v6e-8 and characterize the resulting latency and throughput profile. Compared with a 2xH100 GPU baseline under identical hyperparameters, TPU training completes 1.61x faster at 2.12x lower cost. Inference throughput is within 3% across platforms, while TPU achieves 2x lower time-to-first-token (235 ms vs. 475 ms). Together, the TPU configuration is 1.82x cheaper for a representative train-plus-service workload. Our work removes a critical gap in the open tooling ecosystem and provides practitioners with a reproducible, production-ready recipe for Gemma 4 deployment on TPU infrastructure.
Vector Policy Optimization: Training for Diversity Improves Test-Time Search
May 21, 2026Language models must now generalize out of the box to novel environments and work inside inference-scaling search procedures, such as AlphaEvolve, that select rollouts with a variety of task-specific reward functions. Unfortunately, the standard paradigm of LLM post-training optimizes a pre-specified scalar reward, often leading current LLMs to produce low-entropy response distributions and thus to struggle at displaying the diversity that inference-time search will require. We propose Vector Policy Optimization (VPO), an RL algorithm that explicitly trains policies to anticipate diverse downstream reward functions and to produce diverse solutions. VPO exploits that rewards are often vector-valued in practice, like per-test-case correctness in code generation or, say, multiple different user personas or reward models. VPO is essentially a drop-in replacement for the GRPO advantage estimator, but it trains the LLM to output a set of solutions where individual solutions specialize to different trade-offs in the vector reward space. Across four tasks, VPO matches or beats the strongest scalar RL baselines on test-time search (e.g. pass@k and best@k), with the gap widening as the search budget grows. For evolutionary search, VPO models unlock problems that GRPO models cannot solve at all. As test-time search becomes more standardized, optimizing for diversity may need to become the default post-training objective.
Tune to Learn: How Controller Gains Shape Robot Policy Learning
Apr 02, 2026Position controllers have become the dominant interface for executing learned manipulation policies. Yet a critical design decision remains understudied: how should we choose controller gains for policy learning? The conventional wisdom is to select gains based on desired task compliance or stiffness. However, this logic breaks down when controllers are paired with state-conditioned policies: effective stiffness emerges from the interplay between learned reactions and control dynamics, not from gains alone. We argue that gain selection should instead be guided by learnability: how amenable different gain settings are to the learning algorithm in use. In this work, we systematically investigate how position controller gains affect three core components of modern robot learning pipelines: behavior cloning, reinforcement learning from scratch, and sim-to-real transfer. Through extensive experiments across multiple tasks and robot embodiments, we find that: (1) behavior cloning benefits from compliant and overdamped gain regimes, (2) reinforcement learning can succeed across all gain regimes given compatible hyperparameter tuning, and (3) sim-to-real transfer is harmed by stiff and overdamped gain regimes. These findings reveal that optimal gain selection depends not on the desired task behavior, but on the learning paradigm employed. Project website: https://younghyopark.me/tune-to-learn
H2LooP Spark Preview: Continual Pretraining of Large Language Models for Low-Level Embedded Systems Code
Mar 11, 2026Large language models (LLMs) demonstrate strong code generation abilities in general-purpose programming languages but remain limited in specialized domains such as low-level embedded systems programming. This domain involves hardware register manipulation, vendor-specific SDKs, real-time operating system APIs, and hardware abstraction layers that are underrepresented in standard pretraining corpora. We introduce H2LooP Spark Preview, a continual pretraining (CPT) pipeline that adapts the OLMo-3-7B-a fully open language model to the embedded systems domain using BF16 LoRA with rank-stabilized scaling on 8 NVIDIA H100 GPUs. Our training corpus is constructed from repository-datasheet pairs covering 100B tokens of raw embedded systems data across 117 manufacturers, processed using the hierarchical datasheet-to-code mapping approach proposed in SpecMap (Nipane et al., 2026). The resulting curated dataset split contains 23.5B tokens across 13 embedded domains. Continual pretraining with high-rank LoRA (r=512) yields substantial gains, reducing in-domain perplexity by 70.4% and held-out repository perplexity by 66.1%. On generative code completion benchmarks spanning 13 embedded domains, our 7B model outperforms Claude Opus 4.6 and Qwen3-Coder-30B on 8 categories in token accuracy, showing that targeted continual pretraining enables smaller open-weight models to rival frontier systems on specialized technical tasks. We release the production training checkpoint on Huggingface as an open-source artifact.
Training Language Models via Neural Cellular Automata
Mar 09, 2026Pre-training is crucial for large language models (LLMs), as it is when most representations and capabilities are acquired. However, natural language pre-training has problems: high-quality text is finite, it contains human biases, and it entangles knowledge with reasoning. This raises a fundamental question: is natural language the only path to intelligence? We propose using neural cellular automata (NCA) to generate synthetic, non-linguistic data for pre-pre-training LLMs--training on synthetic-then-natural language. NCA data exhibits rich spatiotemporal structure and statistics resembling natural language while being controllable and cheap to generate at scale. We find that pre-pre-training on only 164M NCA tokens improves downstream language modeling by up to 6% and accelerates convergence by up to 1.6x. Surprisingly, this even outperforms pre-pre-training on 1.6B tokens of natural language from Common Crawl with more compute. These gains also transfer to reasoning benchmarks, including GSM8K, HumanEval, and BigBench-Lite. Investigating what drives transfer, we find that attention layers are the most transferable, and that optimal NCA complexity varies by domain: code benefits from simpler dynamics, while math and web text favor more complex ones. These results enable systematic tuning of the synthetic distribution to target domains. More broadly, our work opens a path toward more efficient models with fully synthetic pre-training.
Agile asymmetric multi-legged locomotion: contact planning via geometric mechanics and spin model duality
Feb 09, 2026Legged robot research is presently focused on bipedal or quadrupedal robots, despite capabilities to build robots with many more legs to potentially improve locomotion performance. This imbalance is not necessarily due to hardware limitations, but rather to the absence of principled control frameworks that explain when and how additional legs improve locomotion performance. In multi-legged systems, coordinating many simultaneous contacts introduces a severe curse of dimensionality that challenges existing modeling and control approaches. As an alternative, multi-legged robots are typically controlled using low-dimensional gaits originally developed for bipeds or quadrupeds. These strategies fail to exploit the new symmetries and control opportunities that emerge in higher-dimensional systems. In this work, we develop a principled framework for discovering new control structures in multi-legged locomotion. We use geometric mechanics to reduce contact-rich locomotion planning to a graph optimization problem, and propose a spin model duality framework from statistical mechanics to exploit symmetry breaking and guide optimal gait reorganization. Using this approach, we identify an asymmetric locomotion strategy for a hexapod robot that achieves a forward speed of 0.61 body lengths per cycle (a 50% improvement over conventional gaits). The resulting asymmetry appears at both the control and hardware levels. At the control level, the body orientation oscillates asymmetrically between fast clockwise and slow counterclockwise turning phases for forward locomotion. At the hardware level, two legs on the same side remain unactuated and can be replaced with rigid parts without degrading performance. Numerical simulations and robophysical experiments validate the framework and reveal novel locomotion behaviors that emerge from symmetry reforming in high-dimensional embodied systems.
Self-Distillation Enables Continual Learning
Jan 27, 2026Continual learning, enabling models to acquire new skills and knowledge without degrading existing capabilities, remains a fundamental challenge for foundation models. While on-policy reinforcement learning can reduce forgetting, it requires explicit reward functions that are often unavailable. Learning from expert demonstrations, the primary alternative, is dominated by supervised fine-tuning (SFT), which is inherently off-policy. We introduce Self-Distillation Fine-Tuning (SDFT), a simple method that enables on-policy learning directly from demonstrations. SDFT leverages in-context learning by using a demonstration-conditioned model as its own teacher, generating on-policy training signals that preserve prior capabilities while acquiring new skills. Across skill learning and knowledge acquisition tasks, SDFT consistently outperforms SFT, achieving higher new-task accuracy while substantially reducing catastrophic forgetting. In sequential learning experiments, SDFT enables a single model to accumulate multiple skills over time without performance regression, establishing on-policy distillation as a practical path to continual learning from demonstrations.
SpecMap: Hierarchical LLM Agent for Datasheet-to-Code Traceability Link Recovery in Systems Engineering
Jan 16, 2026Establishing precise traceability between embedded systems datasheets and their corresponding code implementations remains a fundamental challenge in systems engineering, particularly for low-level software where manual mapping between specification documents and large code repositories is infeasible. Existing Traceability Link Recovery approaches primarily rely on lexical similarity and information retrieval techniques, which struggle to capture the semantic, structural, and symbol level relationships prevalent in embedded systems software. We present a hierarchical datasheet-to-code mapping methodology that employs large language models for semantic analysis while explicitly structuring the traceability process across multiple abstraction levels. Rather than performing direct specification-to-code matching, the proposed approach progressively narrows the search space through repository-level structure inference, file-level relevance estimation, and fine-grained symbollevel alignment. The method extends beyond function-centric mapping by explicitly covering macros, structs, constants, configuration parameters, and register definitions commonly found in systems-level C/C++ codebases. We evaluate the approach on multiple open-source embedded systems repositories using manually curated datasheet-to-code ground truth. Experimental results show substantial improvements over traditional information-retrieval-based baselines, achieving up to 73.3% file mapping accuracy. We significantly reduce computational overhead, lowering total LLM token consumption by 84% and end-to-end runtime by approximately 80%. This methodology supports automated analysis of large embedded software systems and enables downstream applications such as training data generation for systems-aware machine learning models, standards compliance verification, and large-scale specification coverage analysis.
DEXOP: A Device for Robotic Transfer of Dexterous Human Manipulation
Sep 04, 2025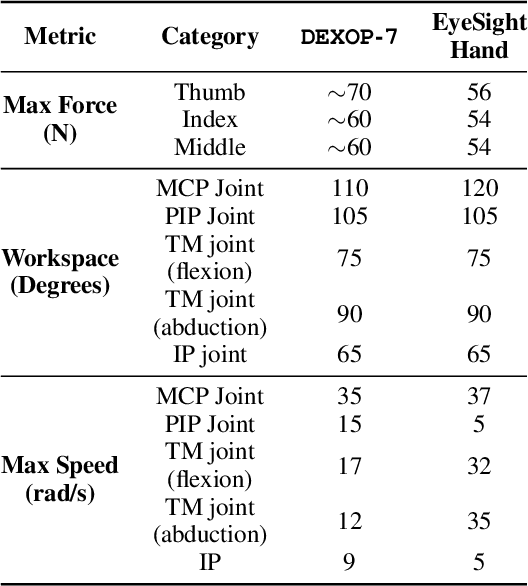
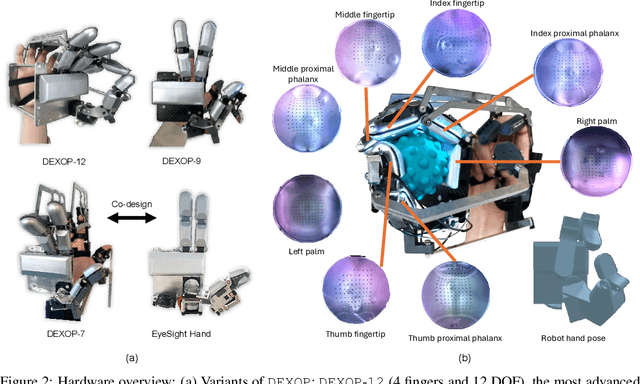

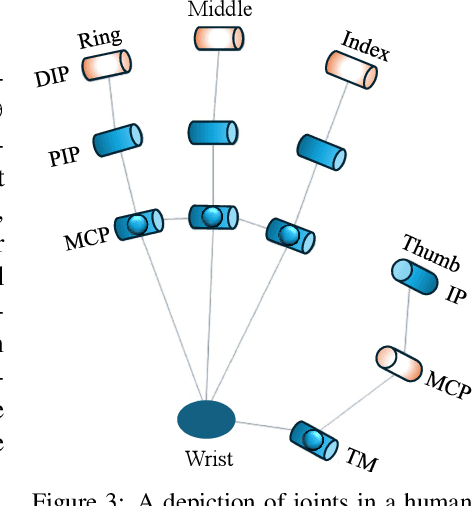
We introduce perioperation, a paradigm for robotic data collection that sensorizes and records human manipulation while maximizing the transferability of the data to real robots. We implement this paradigm in DEXOP, a passive hand exoskeleton designed to maximize human ability to collect rich sensory (vision + tactile) data for diverse dexterous manipulation tasks in natural environments. DEXOP mechanically connects human fingers to robot fingers, providing users with direct contact feedback (via proprioception) and mirrors the human hand pose to the passive robot hand to maximize the transfer of demonstrated skills to the robot. The force feedback and pose mirroring make task demonstrations more natural for humans compared to teleoperation, increasing both speed and accuracy. We evaluate DEXOP across a range of dexterous, contact-rich tasks, demonstrating its ability to collect high-quality demonstration data at scale. Policies learned with DEXOP data significantly improve task performance per unit time of data collection compared to teleoperation, making DEXOP a powerful tool for advancing robot dexterity. Our project page is at https://dex-op.github.io.