 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot Learning with Super-Linear Scaling
Dec 02, 2024Scaling robot learning requires data collection pipelines that scale favorably with human effort. In this work, we propose Crowdsourcing and Amortizing Human Effort for Real-to-Sim-to-Real(CASHER), a pipeline for scaling up data collection and learning in simulation where the performance scales superlinearly with human effort. The key idea is to crowdsource digital twins of real-world scenes using 3D reconstruction and collect large-scale data in simulation, rather than the real-world. Data collection in simulation is initially driven by RL, bootstrapped with human demonstrations. As the training of a generalist policy progresses across environments, its generalization capabilities can be used to replace human effort with model generated demonstrations. This results in a pipeline where behavioral data is collected in simulation with continually reducing human effort. We show that CASHER demonstrates zero-shot and few-shot scaling laws on three real-world tasks across diverse scenarios. We show that CASHER enables fine-tuning of pre-trained policies to a target scenario using a video scan without any additional human effort. See our project website: https://casher-robot-learning.github.io/CASHER/
Diffusion Policy Policy Optimization
Sep 01, 2024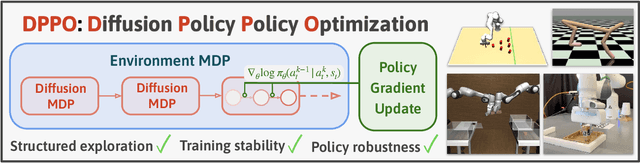

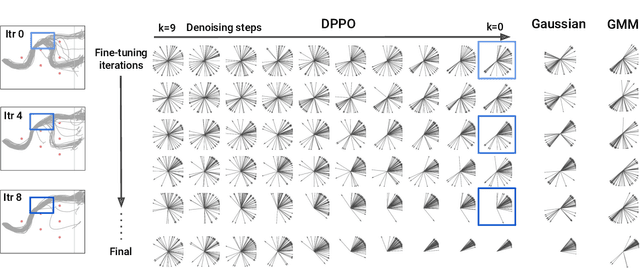
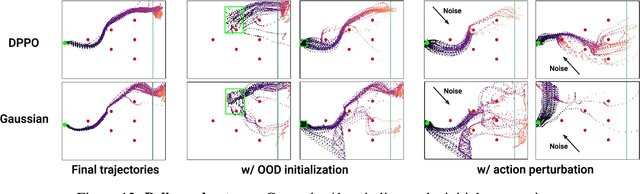
We introduce Diffusion Policy Policy Optimization, DPPO, an algorithmic framework including best practices for fine-tuning diffusion-based policies (e.g. Diffusion Policy) in continuous control and robot learning tasks using the policy gradient (PG) method from reinforcement learning (RL). PG methods are ubiquitous in training RL policies with other policy parameterizations; nevertheless, they had been conjectured to be less efficient for diffusion-based policies. Surprisingly, we show that DPPO achieves the strongest overall performance and efficiency for fine-tuning in common benchmarks compared to other RL methods for diffusion-based policies and also compared to PG fine-tuning of other policy parameterizations. Through experimental investigation, we find that DPPO takes advantage of unique synergies between RL fine-tuning and the diffusion parameterization, leading to structured and on-manifold exploration, stable training, and strong policy robustness. We further demonstrate the strengths of DPPO in a range of realistic settings, including simulated robotic tasks with pixel observations, and via zero-shot deployment of simulation-trained policies on robot hardware in a long-horizon, multi-stage manipulation task. Website with code: diffusion-ppo.github.io
From Imitation to Refinement -- Residual RL for Precise Visual Assembly
Jul 23, 2024Behavior cloning (BC) currently stands as a dominant paradigm for learning real-world visual manipulation. However, in tasks that require locally corrective behaviors like multi-part assembly, learning robust policies purely from human demonstrations remains challenging. Reinforcement learning (RL) can mitigate these limitations by allowing policies to acquire locally corrective behaviors through task reward supervision and exploration. This paper explores the use of RL fine-tuning to improve upon BC-trained policies in precise manipulation tasks. We analyze and overcome technical challenges associated with using RL to directly train policy networks that incorporate modern architectural components like diffusion models and action chunking. We propose training residual policies on top of frozen BC-trained diffusion models using standard policy gradient methods and sparse rewards, an approach we call ResiP (Residual for Precise manipulation). Our experimental results demonstrate that this residual learning framework can significantly improve success rates beyond the base BC-trained models in high-precision assembly tasks by learning corrective actions. We also show that by combining ResiP with teacher-student distillation and visual domain randomization, our method can enable learning real-world policies for robotic assembly directly from RGB images. Find videos and code at \url{https://residual-assembly.github.io}.
JUICER: Data-Efficient Imitation Learning for Robotic Assembly
Apr 09, 2024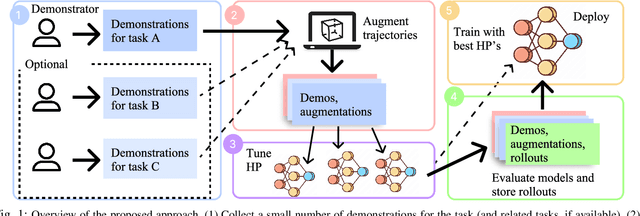
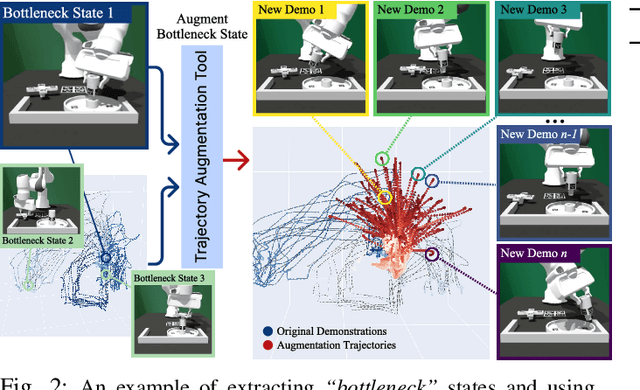

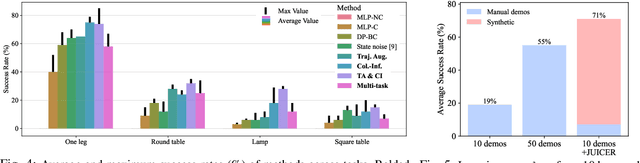
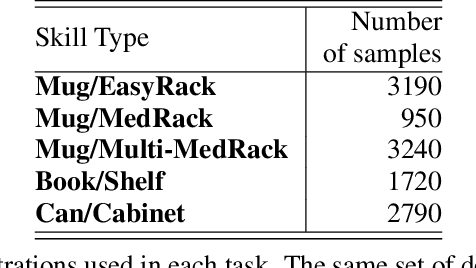
While learning from demonstrations is powerful for acquiring visuomotor policies, high-performance imitation without large demonstration datasets remains challenging for tasks requiring precise, long-horizon manipulation. This paper proposes a pipeline for improving imitation learning performance with a small human demonstration budget. We apply our approach to assembly tasks that require precisely grasping, reorienting, and inserting multiple parts over long horizons and multiple task phases. Our pipeline combines expressive policy architectures and various techniques for dataset expansion and simulation-based data augmentation. These help expand dataset support and supervise the model with locally corrective actions near bottleneck regions requiring high precision. We demonstrate our pipeline on four furniture assembly tasks in simulation, enabling a manipulator to assemble up to five parts over nearly 2500 time steps directly from RGB images, outperforming imitation and data augmentation baselines. Project website: https://imitation-juicer.github.io/.
Reconciling Reality through Simulation: A Real-to-Sim-to-Real Approach for Robust Manipulation
Mar 06, 2024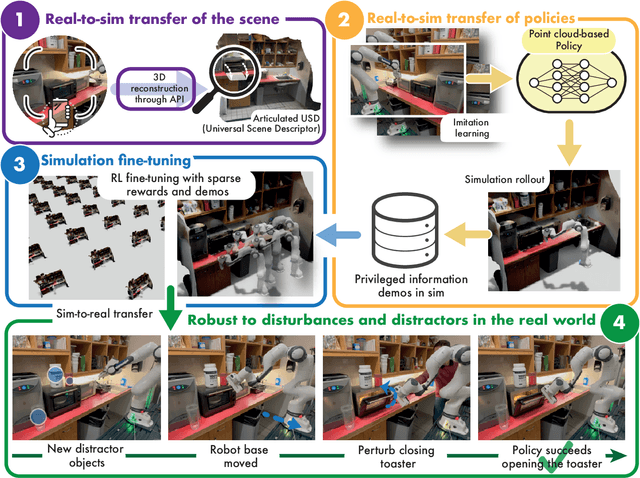



Imitation learning methods need significant human supervision to learn policies robust to changes in object poses, physical disturbances, and visual distractors. Reinforcement learning, on the other hand, can explore the environment autonomously to learn robust behaviors but may require impractical amounts of unsafe real-world data collection. To learn performant, robust policies without the burden of unsafe real-world data collection or extensive human supervision, we propose RialTo, a system for robustifying real-world imitation learning policies via reinforcement learning in "digital twin" simulation environments constructed on the fly from small amounts of real-world data. To enable this real-to-sim-to-real pipeline, RialTo proposes an easy-to-use interface for quickly scanning and constructing digital twins of real-world environments. We also introduce a novel "inverse distillation" procedure for bringing real-world demonstrations into simulated environments for efficient fine-tuning, with minimal human intervention and engineering required. We evaluate RialTo across a variety of robotic manipulation problems in the real world, such as robustly stacking dishes on a rack, placing books on a shelf, and six other tasks. RialTo increases (over 67%) in policy robustness without requiring extensive human data collection. Project website and videos at https://real-to-sim-to-real.github.io/RialTo/
Human-Assisted Continual Robot Learning with Foundation Models
Sep 25, 2023



Large Language Models (LLMs) have been shown to act like planners that can decompose high-level instructions into a sequence of executable instructions. However, current LLM-based planners are only able to operate with a fixed set of skills. We overcome this critical limitation and present a method for using LLM-based planners to query new skills and teach robots these skills in a data and time-efficient manner for rigid object manipulation. Our system can re-use newly acquired skills for future tasks, demonstrating the potential of open world and lifelong learning. We evaluate the proposed framework on multiple tasks in simulation and the real world. Videos are available at: https://sites.google.com/mit.edu/halp-robot-learning.
Shelving, Stacking, Hanging: Relational Pose Diffusion for Multi-modal Rearrangement
Jul 10, 2023


We propose a system for rearranging objects in a scene to achieve a desired object-scene placing relationship, such as a book inserted in an open slot of a bookshelf. The pipeline generalizes to novel geometries, poses, and layouts of both scenes and objects, and is trained from demonstrations to operate directly on 3D point clouds. Our system overcomes challenges associated with the existence of many geometrically-similar rearrangement solutions for a given scene. By leveraging an iterative pose de-noising training procedure, we can fit multi-modal demonstration data and produce multi-modal outputs while remaining precise and accurate. We also show the advantages of conditioning on relevant local geometric features while ignoring irrelevant global structure that harms both generalization and precision. We demonstrate our approach on three distinct rearrangement tasks that require handling multi-modality and generalization over object shape and pose in both simulation and the real world. Project website, code, and videos: https://anthonysimeonov.github.io/rpdiff-multi-modal/
Local Neural Descriptor Fields: Locally Conditioned Object Representations for Manipulation
Feb 07, 2023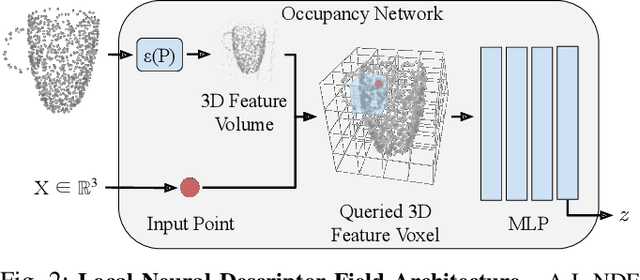

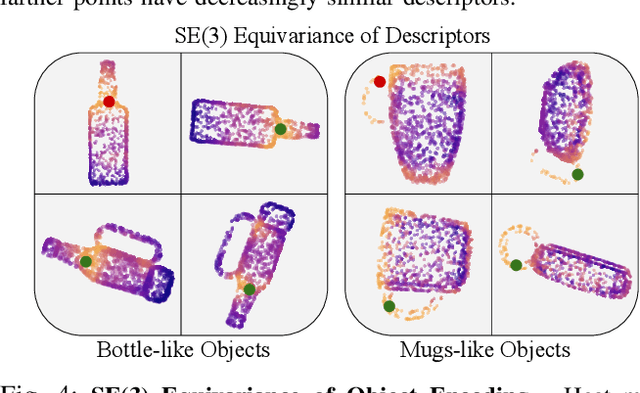
A robot operating in a household environment will see a wide range of unique and unfamiliar objects. While a system could train on many of these, it is infeasible to predict all the objects a robot will see. In this paper, we present a method to generalize object manipulation skills acquired from a limited number of demonstrations, to novel objects from unseen shape categories. Our approach, Local Neural Descriptor Fields (L-NDF), utilizes neural descriptors defined on the local geometry of the object to effectively transfer manipulation demonstrations to novel objects at test time. In doing so, we leverage the local geometry shared between objects to produce a more general manipulation framework. We illustrate the efficacy of our approach in manipulating novel objects in novel poses -- both in simulation and in the real world.
MIRA: Mental Imagery for Robotic Affordances
Dec 12, 2022Humans form mental images of 3D scenes to support counterfactual imagination, planning, and motor control. Our abilities to predict the appearance and affordance of the scene from previously unobserved viewpoints aid us in performing manipulation tasks (e.g., 6-DoF kitting) with a level of ease that is currently out of reach for existing robot learning frameworks. In this work, we aim to build artificial systems that can analogously plan actions on top of imagined images. To this end, we introduce Mental Imagery for Robotic Affordances (MIRA), an action reasoning framework that optimizes actions with novel-view synthesis and affordance prediction in the loop. Given a set of 2D RGB images, MIRA builds a consistent 3D scene representation, through which we synthesize novel orthographic views amenable to pixel-wise affordances prediction for action optimization. We illustrate how this optimization process enables us to generalize to unseen out-of-plane rotations for 6-DoF robotic manipulation tasks given a limited number of demonstrations, paving the way toward machines that autonomously learn to understand the world around them for planning actions.
SE(3)-Equivariant Relational Rearrangement with Neural Descriptor Fields
Nov 17, 2022We present a method for performing tasks involving spatial relations between novel object instances initialized in arbitrary poses directly from point cloud observations. Our framework provides a scalable way for specifying new tasks using only 5-10 demonstrations. Object rearrangement is formalized as the question of finding actions that configure task-relevant parts of the object in a desired alignment. This formalism is implemented in three steps: assigning a consistent local coordinate frame to the task-relevant object parts, determining the location and orientation of this coordinate frame on unseen object instances, and executing an action that brings these frames into the desired alignment. We overcome the key technical challenge of determining task-relevant local coordinate frames from a few demonstrations by developing an optimization method based on Neural Descriptor Fields (NDFs) and a single annotated 3D keypoint. An energy-based learning scheme to model the joint configuration of the objects that satisfies a desired relational task further improves performance. The method is tested on three multi-object rearrangement tasks in simulation and on a real robot. Project website, videos, and code: https://anthonysimeonov.github.io/r-ndf/