 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolaRiS: Scalable Real-to-Sim Evaluations for Generalist Robot Policies
Dec 18, 2025A significant challenge for robot learning research is our ability to accurately measure and compare the performance of robot policies. Benchmarking in robotics is historically challenging due to the stochasticity, reproducibility, and time-consuming nature of real-world rollouts. This challenge is exacerbated for recent generalist policies, which has to be evaluated across a wide variety of scenes and tasks. Evaluation in simulation offers a scalable complement to real world evaluations, but the visual and physical domain gap between existing simulation benchmarks and the real world has made them an unreliable signal for policy improvement. Furthermore, building realistic and diverse simulated environments has traditionally required significant human effort and expertise. To bridge the gap, we introduce Policy Evaluation and Environment Reconstruction in Simulation (PolaRiS), a scalable real-to-sim framework for high-fidelity simulated robot evaluation. PolaRiS utilizes neural reconstruction methods to turn short video scans of real-world scenes into interactive simulation environments. Additionally, we develop a simple simulation data co-training recipe that bridges remaining real-to-sim gaps and enables zero-shot evaluation in unseen simulation environments. Through extensive paired evaluations between simulation and the real world, we demonstrate that PolaRiS evaluations provide a much stronger correlation to real world generalist policy performance than existing simulated benchmarks. Its simplicity also enables rapid creation of diverse simulated environments. As such, this work takes a step towards distributed and democratized evaluation for the next generation of robotic foundation models.
X-Diffusion: Training Diffusion Policies on Cross-Embodiment Human Demonstrations
Nov 06, 2025Human videos can be recorded quickly and at scale, making them an appealing source of training data for robot learning. However, humans and robots differ fundamentally in embodiment, resulting in mismatched action execution. Direct kinematic retargeting of human hand motion can therefore produce actions that are physically infeasible for robots. Despite these low-level differences, human demonstrations provide valuable motion cues about how to manipulate and interact with objects. Our key idea is to exploit the forward diffusion process: as noise is added to actions, low-level execution differences fade while high-level task guidance is preserved. We present X-Diffusion, a principled framework for training diffusion policies that maximally leverages human data without learning dynamically infeasible motions. X-Diffusion first trains a classifier to predict whether a noisy action is executed by a human or robot. Then, a human action is incorporated into policy training only after adding sufficient noise such that the classifier cannot discern its embodiment. Actions consistent with robot execution supervise fine-grained denoising at low noise levels, while mismatched human actions provide only coarse guidance at higher noise levels. Our experiments show that naive co-training under execution mismatches degrades policy performance, while X-Diffusion consistently improves it. Across five manipulation tasks, X-Diffusion achieves a 16% higher average success rate than the best baseline. The project website is available at https://portal-cornell.github.io/X-Diffusion/.
Prompting with the Future: Open-World Model Predictive Control with Interactive Digital Twins
Jun 16, 2025Recent advancements in open-world robot manipulation have been largely driven by vision-language models (VLMs). While these models exhibit strong generalization ability in high-level planning, they struggle to predict low-level robot controls due to limited physical-world understanding. To address this issue, we propose a model predictive control framework for open-world manipulation that combines the semantic reasoning capabilities of VLMs with physically-grounded, interactive digital twins of the real-world environments. By constructing and simulating the digital twins, our approach generates feasible motion trajectories, simulates corresponding outcomes, and prompts the VLM with future observations to evaluate and select the most suitable outcome based on language instructions of the task. To further enhance the capability of pre-trained VLMs in understanding complex scenes for robotic control, we leverage the flexible rendering capabilities of the digital twin to synthesize the scene at various novel, unoccluded viewpoints. We validate our approach on a diverse set of complex manipulation tasks, demonstrating superior performance compared to baseline methods for language-conditioned robotic control using VLMs.
X-Sim: Cross-Embodiment Learning via Real-to-Sim-to-Real
May 15, 2025Human videos offer a scalable way to train robot manipulation policies, but lack the action labels needed by standard imitation learning algorithms. Existing cross-embodiment approaches try to map human motion to robot actions, but often fail when the embodiments differ significantly. We propose X-Sim, a real-to-sim-to-real framework that uses object motion as a dense and transferable signal for learning robot policies. X-Sim starts by reconstructing a photorealistic simulation from an RGBD human video and tracking object trajectories to define object-centric rewards. These rewards are used to train a reinforcement learning (RL) policy in simulation. The learned policy is then distilled into an image-conditioned diffusion policy using synthetic rollouts rendered with varied viewpoints and lighting. To transfer to the real world, X-Sim introduces an online domain adaptation technique that aligns real and simulated observations during deployment. Importantly, X-Sim does not require any robot teleoperation data. We evaluate it across 5 manipulation tasks in 2 environments and show that it: (1) improves task progress by 30% on average over hand-tracking and sim-to-real baselines, (2) matches behavior cloning with 10x less data collection time, and (3) generalizes to new camera viewpoints and test-time changes. Code and videos are available at https://portal-cornell.github.io/X-Sim/.
Eval3D: Interpretable and Fine-grained Evaluation for 3D Generation
Apr 25, 2025Despite the unprecedented progress in the field of 3D generation, current systems still often fail to produce high-quality 3D assets that are visually appealing and geometrically and semantically consistent across multiple viewpoints. To effectively assess the quality of the generated 3D data, there is a need for a reliable 3D evaluation tool. Unfortunately, existing 3D evaluation metrics often overlook the geometric quality of generated assets or merely rely on black-box multimodal large language models for coarse assessment. In this paper, we introduce Eval3D, a fine-grained, interpretable evaluation tool that can faithfully evaluate the quality of generated 3D assets based on various distinct yet complementary criteria. Our key observation is that many desired properties of 3D generation, such as semantic and geometric consistency, can be effectively captured by measuring the consistency among various foundation models and tools. We thus leverage a diverse set of models and tools as probes to evaluate the inconsistency of generated 3D assets across different aspects. Compared to prior work, Eval3D provides pixel-wise measurement, enables accurate 3D spatial feedback, and aligns more closely with human judgments. We comprehensively evaluate existing 3D generation models using Eval3D and highlight the limitations and challenges of current models.
DRAWER: Digital Reconstruction and Articulation With Environment Realism
Apr 22, 2025Creating virtual digital replicas from real-world data unlocks significant potential across domains like gaming and robotics. In this paper, we present DRAWER, a novel framework that converts a video of a static indoor scene into a photorealistic and interactive digital environment. Our approach centers on two main contributions: (i) a reconstruction module based on a dual scene representation that reconstructs the scene with fine-grained geometric details, and (ii) an articulation module that identifies articulation types and hinge positions, reconstructs simulatable shapes and appearances and integrates them into the scene. The resulting virtual environment is photorealistic, interactive, and runs in real time, with compatibility for game engines and robotic simulation platforms. We demonstrate the potential of DRAWER by using it to automatically create an interactive game in Unreal Engine and to enable real-to-sim-to-real transfer for robotics applications.
Beyond the Frame: Generating 360° Panoramic Videos from Perspective Videos
Apr 10, 2025360{\deg} videos have emerged as a promising medium to represent our dynamic visual world. Compared to the "tunnel vision" of standard cameras, their borderless field of view offers a more complete perspective of our surroundings. While existing video models excel at producing standard videos, their ability to generate full panoramic videos remains elusive. In this paper, we investigate the task of video-to-360{\deg} generation: given a perspective video as input, our goal is to generate a full panoramic video that is consistent with the original video. Unlike conventional video generation tasks, the output's field of view is significantly larger, and the model is required to have a deep understanding of both the spatial layout of the scene and the dynamics of objects to maintain spatio-temporal consistency. To address these challenges, we first leverage the abundant 360{\deg} videos available online and develop a high-quality data filtering pipeline to curate pairwise training data. We then carefully design a series of geometry- and motion-aware operations to facilitate the learning process and improve the quality of 360{\deg} video generation. Experimental results demonstrate that our model can generate realistic and coherent 360{\deg} videos from in-the-wild perspective video. In addition, we showcase its potential applications, including video stabilization, camera viewpoint control, and interactive visual question answering.
From an Image to a Scene: Learning to Imagine the World from a Million 360 Videos
Dec 10, 2024Three-dimensional (3D) understanding of objects and scenes play a key role in humans' ability to interact with the world and has been an active area of research in computer vision, graphics, and robotics. Large scale synthetic and object-centric 3D datasets have shown to be effective in training models that have 3D understanding of objects. However, applying a similar approach to real-world objects and scenes is difficult due to a lack of large-scale data. Videos are a potential source for real-world 3D data, but finding diverse yet corresponding views of the same content has shown to be difficult at scale. Furthermore, standard videos come with fixed viewpoints, determined at the time of capture. This restricts the ability to access scenes from a variety of more diverse and potentially useful perspectives. We argue that large scale 360 videos can address these limitations to provide: scalable corresponding frames from diverse views. In this paper, we introduce 360-1M, a 360 video dataset, and a process for efficiently finding corresponding frames from diverse viewpoints at scale. We train our diffusion-based model, Odin, on 360-1M. Empowered by the largest real-world, multi-view dataset to date, Odin is able to freely generate novel views of real-world scenes. Unlike previous methods, Odin can move the camera through the environment, enabling the model to infer the geometry and layout of the scene. Additionally, we show improved performance on standard novel view synthesis and 3D reconstruction benchmarks.
Sparse Voxels Rasterization: Real-time High-fidelity Radiance Field Rendering
Dec 05, 2024We propose an efficient radiance field rendering algorithm that incorporates a rasterization process on sparse voxels without neural networks or 3D Gaussians. There are two key contributions coupled with the proposed system. The first is to render sparse voxels in the correct depth order along pixel rays by using dynamic Morton ordering. This avoids the well-known popping artifact found in Gaussian splatting. Second, we adaptively fit sparse voxels to different levels of detail within scenes, faithfully reproducing scene details while achieving high rendering frame rates. Our method improves the previous neural-free voxel grid representation by over 4db PSNR and more than 10x rendering FPS speedup, achieving state-of-the-art comparable novel-view synthesis results. Additionally, our neural-free sparse voxels are seamlessly compatible with grid-based 3D processing algorithms. We achieve promising mesh reconstruction accuracy by integrating TSDF-Fusion and Marching Cubes into our sparse grid system.
Coarse Correspondence Elicit 3D Spacetime Understanding in Multimodal Language Model
Aug 01, 2024
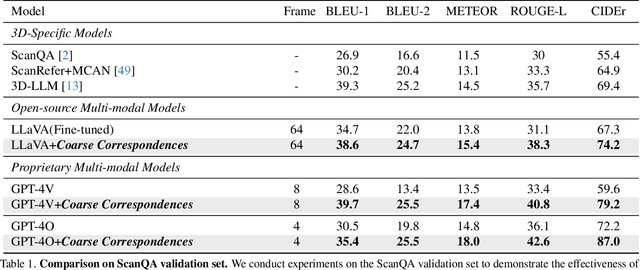
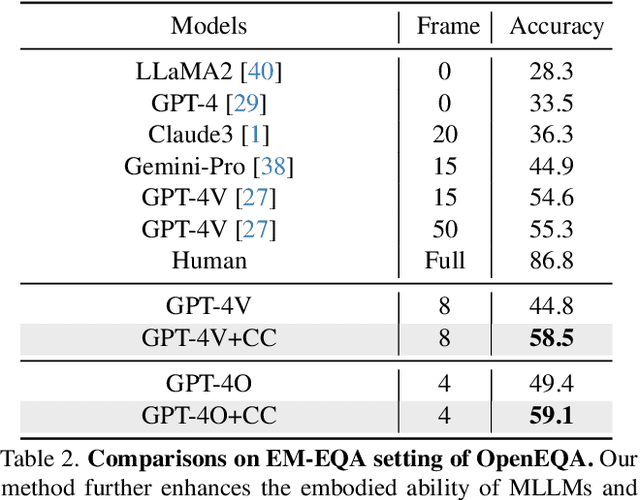

Multimodal language models (MLLMs) are increasingly being implemented in real-world environments, necessitating their ability to interpret 3D spaces and comprehend temporal dynamics. Despite their potential, current top models within our community still fall short in adequately understanding spatial and temporal dimensions. We introduce Coarse Correspondence, a simple, training-free, effective, and general-purpose visual prompting method to elicit 3D and temporal understanding in multimodal LLMs. Our method uses a lightweight tracking model to find object correspondences between frames in a video or between sets of image viewpoints. It selects the most frequent object instances and visualizes them with markers with unique IDs in the image. With this simple approach, we achieve state-of-the-art results on 3D understanding benchmarks including ScanQA (+20.5\%) and a subset of OpenEQA (+9.7\%), and on long-form video benchmarks such as EgoSchema (+6.0\%). We also curate a small diagnostic dataset to evaluate whether MLLMs can reason about space from a described viewpoint other than the camera viewpoint. Again, Coarse Correspondence improves spatial perspective-taking abilities but we highlight that MLLMs struggle with this task. Together, we demonstrate that our simple prompting method can significantly aid downstream tasks that require 3D or temporal reasoning.