 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
A Geography-Inspired and Self-Adaptive Clustering Algorithm: A Study in Channel Measurement
Apr 29, 2025
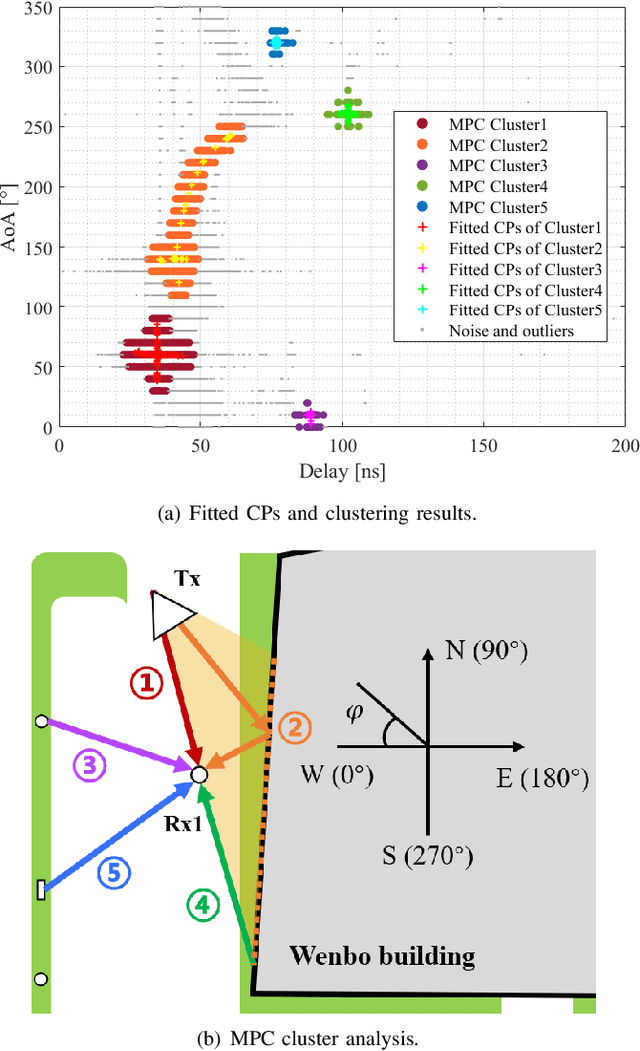


The phenomenon that multi-path components (MPCs) arrive in clusters has been verified by channel measurements, and is widely adopted by cluster-based channel models. As a crucial intermediate processing step, MPC clustering bridges raw data in channel measurement and cluster characteristics for channel modeling. In this paper, a physical-interpretable and self-adaptive MPC clustering algorithm is proposed, which can locate both single-point and wide-spread scatterers without prior knowledge. Inspired by the concept in geography, a novel metaphor that interprets features of MPC attributes in the power-delay-angle profile (PDAP) as topographic concepts is developed. In light of the interpretation, the proposed algorithm disassembles the PDAP by constructing contour lines and identifying characteristic points that indicate the skeleton of MPC clusters, which are fitted by analytical models that associate MPCs with physical scatterer locations. Besides, a new clustering performance index, the power gradient consistency index, is proposed. Calculated as the weighted Spearman correlation coefficient between the power and the distance to the center, the index captures the intrinsic property of MPC clusters that the dominant high-power path is surrounded by lower-power paths. The performance of the proposed algorithm is analyzed and compared with the counterparts of conventional clustering algorithms based on the channel measurement conducted in an outdoor scenario. The proposed algorithm performs better in average Silhouette index and weighted Spearman correlation coefficient, and the average root mean square error (RMSE) of the estimated scatterer location is 0.1 m.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
Ponder & Press: Advancing Visual GUI Agent towards General Computer Control
Dec 02, 2024Most existing GUI agents typically depend on non-vision inputs like HTML source code or accessibility trees, limiting their flexibility across diverse software environments and platforms. Current multimodal large language models (MLLMs), which excel at using vision to ground real-world objects, offer a potential alternative. However, they often struggle with accurately localizing GUI elements -- a critical requirement for effective GUI automation -- due to the semantic gap between real-world objects and GUI elements. In this work, we introduce Ponder & Press, a divide-and-conquer framework for general computer control using only visual input. Our approach combines an general-purpose MLLM as an 'interpreter', responsible for translating high-level user instructions into detailed action descriptions, with a GUI-specific MLLM as a 'locator' that precisely locates GUI elements for action placement. By leveraging a purely visual input, our agent offers a versatile, human-like interaction paradigm applicable to a wide range of applications. Ponder & Press locator outperforms existing models by +22.5% on the ScreenSpot GUI grounding benchmark. Both offline and interactive agent benchmarks across various GUI environments -- including web pages, desktop software, and mobile UIs -- demonstrate that Ponder & Press framework achieves state-of-the-art performance, highlighting the potential of visual GUI agents. Refer to the project homepage https://invinciblewyq.github.io/ponder-press-page/
Movable Antennas: Channel Measurement, Modeling, and Performance Evaluation
Sep 05, 2024Since decades ago, multi-antenna has become a key enabling technology in the evolution of wireless communication systems. In contrast to conventional multi-antenna systems that contain antennas at fixed positions, position-flexible antenna systems have been proposed to fully utilize the spatial variation of wireless channels. In this paper, movable antenna (MA) systems are analyzed from channel measurement, modeling, position optimization to performance evaluation. First, a broadband channel measurement system with physical MAs is developed, for which the extremely high movable resolution reaches 0.02 mm. A practical two-ray model is constructed based on the channel measurement for a two-dimensional movable antenna system across 32$\times$32 planar port positions at 300 GHz. In light of the measurement results, spatial-correlated channel models for the two-dimensional MA system are proposed, which are statistically parameterized by the covariance matrix of measured channels. Finally, the signal-to-interference-and-noise ratio (SINR)-maximized position selection algorithm is proposed, which achieves 99% of the optimal performance. The performance of different MA systems in terms of spectral efficiency are evaluated and compared for both planar and linear MA systems. Extensive results demonstrate the advantage of MAs over fixed-position antennas in coping with the multi-path fading and improving the spectral efficiency by 10% in a 300 GHz measured channel.
Coarse Correspondence Elicit 3D Spacetime Understanding in Multimodal Language Model
Aug 01, 2024
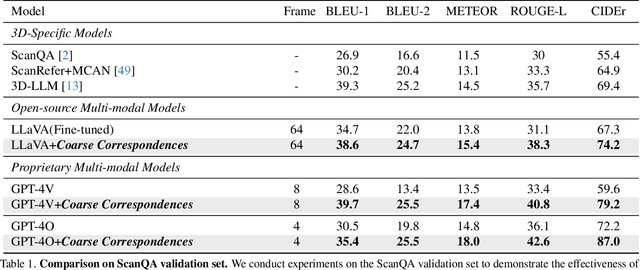
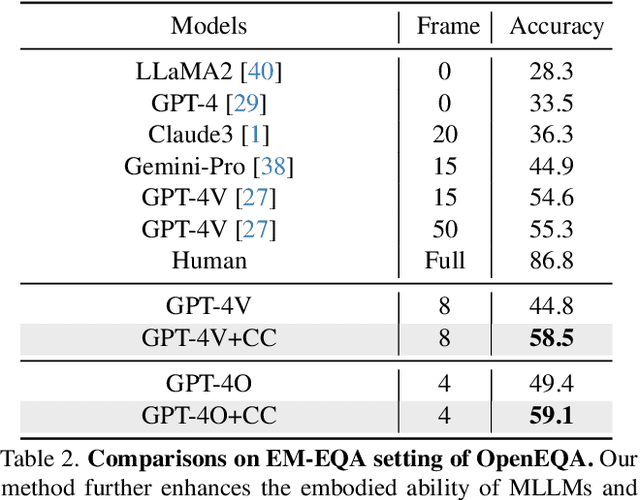

Multimodal language models (MLLMs) are increasingly being implemented in real-world environments, necessitating their ability to interpret 3D spaces and comprehend temporal dynamics. Despite their potential, current top models within our community still fall short in adequately understanding spatial and temporal dimensions. We introduce Coarse Correspondence, a simple, training-free, effective, and general-purpose visual prompting method to elicit 3D and temporal understanding in multimodal LLMs. Our method uses a lightweight tracking model to find object correspondences between frames in a video or between sets of image viewpoints. It selects the most frequent object instances and visualizes them with markers with unique IDs in the image. With this simple approach, we achieve state-of-the-art results on 3D understanding benchmarks including ScanQA (+20.5\%) and a subset of OpenEQA (+9.7\%), and on long-form video benchmarks such as EgoSchema (+6.0\%). We also curate a small diagnostic dataset to evaluate whether MLLMs can reason about space from a described viewpoint other than the camera viewpoint. Again, Coarse Correspondence improves spatial perspective-taking abilities but we highlight that MLLMs struggle with this task. Together, we demonstrate that our simple prompting method can significantly aid downstream tasks that require 3D or temporal reasoning.
Hierarchical Memory for Long Video QA
Jun 30, 2024


This paper describes our champion solution to the LOVEU Challenge @ CVPR'24, Track 1 (Long Video VQA). Processing long sequences of visual tokens is computationally expensive and memory-intensive, making long video question-answering a challenging task. The key is to compress visual tokens effectively, reducing memory footprint and decoding latency, while preserving the essential information for accurate question-answering. We adopt a hierarchical memory mechanism named STAR Memory, proposed in Flash-VStream, that is capable of processing long videos with limited GPU memory (VRAM). We further utilize the video and audio data of MovieChat-1K training set to fine-tune the pretrained weight released by Flash-VStream, achieving 1st place in the challenge. Code is available at project homepage https://invinciblewyq.github.io/vstream-page
Flash-VStream: Memory-Based Real-Time Understanding for Long Video Streams
Jun 12, 2024



Benefiting from the advancements in large language models and cross-modal alignment, existing multi-modal video understanding methods have achieved prominent performance in offline scenario. However, online video streams, as one of the most common media forms in the real world, have seldom received attention. Compared to offline videos, the 'dynamic' nature of online video streams poses challenges for the direct application of existing models and introduces new problems, such as the storage of extremely long-term information, interaction between continuous visual content and 'asynchronous' user questions. Therefore, in this paper we present Flash-VStream, a video-language model that simulates the memory mechanism of human. Our model is able to process extremely long video streams in real-time and respond to user queries simultaneously. Compared to existing models, Flash-VStream achieves significant reductions in inference latency and VRAM consumption, which is intimately related to performing understanding of online streaming video. In addition, given that existing video understanding benchmarks predominantly concentrate on offline scenario, we propose VStream-QA, a novel question answering benchmark specifically designed for online video streaming understanding. Comparisons with popular existing methods on the proposed benchmark demonstrate the superiority of our method for such challenging setting. To verify the generalizability of our approach, we further evaluate it on existing video understanding benchmarks and achieves state-of-the-art performance in offline scenarios as well. All code, models, and datasets are available at the https://invinciblewyq.github.io/vstream-page/
Cross Far- and Near-Field Channel Measurement and Modeling in Extremely Large-scale Antenna Array Systems
May 27, 2024Technologies like ultra-massive multiple-input-multiple-output (UM-MIMO) and reconfigurable intelligent surfaces (RISs) are of special interest to meet the key performance indicators of future wireless systems including ubiquitous connectivity and lightning-fast data rates. One of their common features, the extremely large-scale antenna array (ELAA) systems with hundreds or thousands of antennas, give rise to near-field (NF) propagation and bring new challenges to channel modeling and characterization. In this paper, a cross-field channel model for ELAA systems is proposed, which improves the statistical model in 3GPP TR 38.901 by refining the propagation path with its first and last bounces and differentiating the characterization of parameters like path loss, delay, and angles in near- and far-fields. A comprehensive analysis of cross-field boundaries and closed-form expressions of corresponding NF or FF parameters are provided. Furthermore, cross-field experiments carried out in a typical indoor scenario at 300 GHz verify the variation of MPC parameters across the antenna array, and demonstrate the distinction of channels between different antenna elements. Finally, detailed generation procedures of the cross-field channel model are provided, based on which simulations and analysis on NF probabilities and channel coefficients are conducted for $4\times4$, $8\times8$, $16\times16$, and $9\times21$ uniform planar arrays at different frequency bands.