 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptionComp: A Video Benchmark for Complex Perception-Centric Reasoning
Mar 27, 2026We introduce PerceptionComp, a manually annotated benchmark for complex, long-horizon, perception-centric video reasoning. PerceptionComp is designed so that no single moment is sufficient: answering each question requires multiple temporally separated pieces of visual evidence and compositional constraints under conjunctive and sequential logic, spanning perceptual subtasks such as objects, attributes, relations, locations, actions, and events, and requiring skills including semantic recognition, visual correspondence, temporal reasoning, and spatial reasoning. The benchmark contains 1,114 highly complex questions on 279 videos from diverse domains including city walk tours, indoor villa tours, video games, and extreme outdoor sports, with 100% manual annotation. Human studies show that PerceptionComp requires substantial test-time thinking and repeated perception steps: participants take much longer than on prior benchmarks, and accuracy drops to near chance (18.97%) when rewatching is disallowed. State-of-the-art MLLMs also perform substantially worse on PerceptionComp than on existing benchmarks: the best model in our evaluation, Gemini-3-Flash, reaches only 45.96% accuracy in the five-choice setting, while open-source models remain below 40%. These results suggest that perception-centric long-horizon video reasoning remains a major bottleneck, and we hope PerceptionComp will help drive progress in perceptual reasoning.
Counting Circuits: Mechanistic Interpretability of Visual Reasoning in Large Vision-Language Models
Mar 19, 2026Counting serves as a simple but powerful test of a Large Vision-Language Model's (LVLM's) reasoning; it forces the model to identify each individual object and then add them all up. In this study, we investigate how LVLMs implement counting using controlled synthetic and real-world benchmarks, combined with mechanistic analyses. Our results show that LVLMs display a human-like counting behavior, with precise performance on small numerosities and noisy estimation for larger quantities. We introduce two novel interpretability methods, Visual Activation Patching and HeadLens, and use them to uncover a structured "counting circuit" that is largely shared across a variety of visual reasoning tasks. Building on these insights, we propose a lightweight intervention strategy that exploits simple and abundantly available synthetic images to fine-tune arbitrary pretrained LVLMs exclusively on counting. Despite the narrow scope of this fine-tuning, the intervention not only enhances counting accuracy on in-distribution synthetic data, but also yields an average improvement of +8.36% on out-of-distribution counting benchmarks and an average gain of +1.54% on complex, general visual reasoning tasks for Qwen2.5-VL. These findings highlight the central, influential role of counting in visual reasoning and suggest a potential pathway for improving overall visual reasoning capabilities through targeted enhancement of counting mechanisms.
Structure From Tracking: Distilling Structure-Preserving Motion for Video Generation
Dec 12, 2025
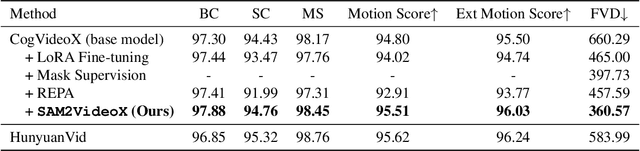
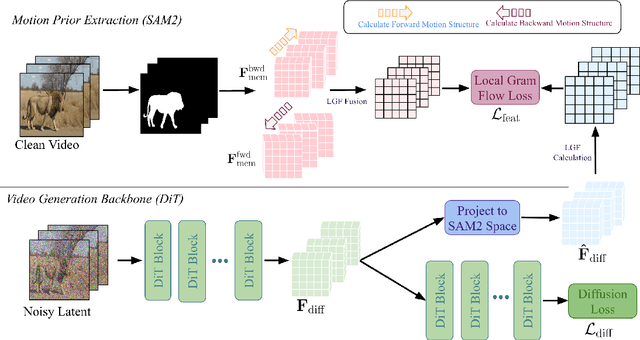
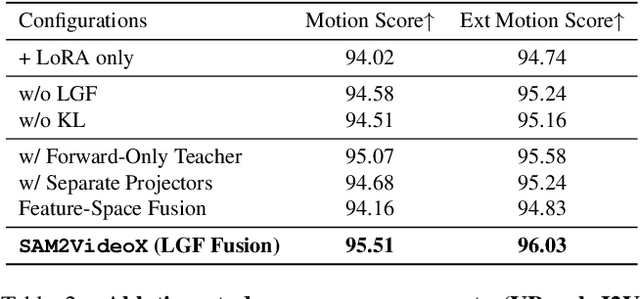
Reality is a dance between rigid constraints and deformable structures. For video models, that means generating motion that preserves fidelity as well as structure. Despite progress in diffusion models, producing realistic structure-preserving motion remains challenging, especially for articulated and deformable objects such as humans and animals. Scaling training data alone, so far, has failed to resolve physically implausible transitions. Existing approaches rely on conditioning with noisy motion representations, such as optical flow or skeletons extracted using an external imperfect model. To address these challenges, we introduce an algorithm to distill structure-preserving motion priors from an autoregressive video tracking model (SAM2) into a bidirectional video diffusion model (CogVideoX). With our method, we train SAM2VideoX, which contains two innovations: (1) a bidirectional feature fusion module that extracts global structure-preserving motion priors from a recurrent model like SAM2; (2) a Local Gram Flow loss that aligns how local features move together. Experiments on VBench and in human studies show that SAM2VideoX delivers consistent gains (+2.60\% on VBench, 21-22\% lower FVD, and 71.4\% human preference) over prior baselines. Specifically, on VBench, we achieve 95.51\%, surpassing REPA (92.91\%) by 2.60\%, and reduce FVD to 360.57, a 21.20\% and 22.46\% improvement over REPA- and LoRA-finetuning, respectively. The project website can be found at https://sam2videox.github.io/ .
Visual Representations inside the Language Model
Oct 06, 2025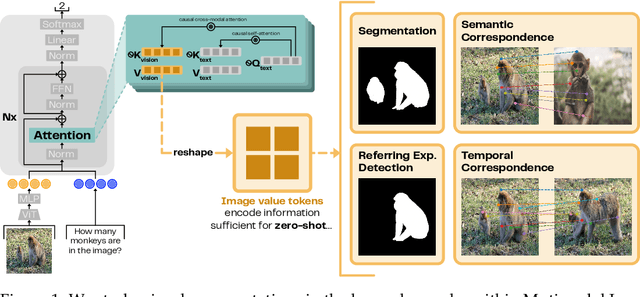

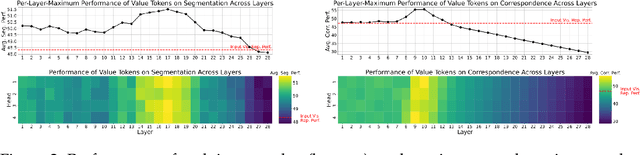
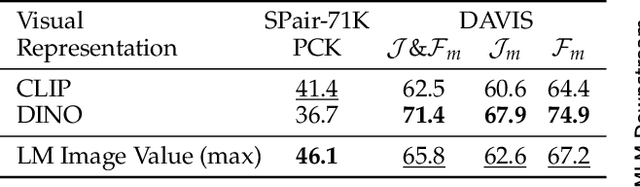
Despite interpretability work analyzing VIT encoders and transformer activations, we don't yet understand why Multimodal Language Models (MLMs) struggle on perception-heavy tasks. We offer an under-studied perspective by examining how popular MLMs (LLaVA-OneVision, Qwen2.5-VL, and Llama-3-LLaVA-NeXT) process their visual key-value tokens. We first study the flow of visual information through the language model, finding that image value tokens encode sufficient information to perform several perception-heavy tasks zero-shot: segmentation, semantic correspondence, temporal correspondence, and referring expression detection. We find that while the language model does augment the visual information received from the projection of input visual encodings-which we reveal correlates with overall MLM perception capability-it contains less visual information on several tasks than the equivalent visual encoder (SigLIP) that has not undergone MLM finetuning. Further, we find that the visual information corresponding to input-agnostic image key tokens in later layers of language models contains artifacts which reduce perception capability of the overall MLM. Next, we discuss controlling visual information in the language model, showing that adding a text prefix to the image input improves perception capabilities of visual representations. Finally, we reveal that if language models were able to better control their visual information, their perception would significantly improve; e.g., in 33.3% of Art Style questions in the BLINK benchmark, perception information present in the language model is not surfaced to the output! Our findings reveal insights into the role of key-value tokens in multimodal systems, paving the way for deeper mechanistic interpretability of MLMs and suggesting new directions for training their visual encoder and language model components.
LiveVQA: Live Visual Knowledge Seeking
Apr 07, 2025



We introduce LiveVQA, an automatically collected dataset of latest visual knowledge from the Internet with synthesized VQA problems. LiveVQA consists of 3,602 single- and multi-hop visual questions from 6 news websites across 14 news categories, featuring high-quality image-text coherence and authentic information. Our evaluation across 15 MLLMs (e.g., GPT-4o, Gemma-3, and Qwen-2.5-VL family) demonstrates that stronger models perform better overall, with advanced visual reasoning capabilities proving crucial for complex multi-hop questions. Despite excellent performance on textual problems, models with tools like search engines still show significant gaps when addressing visual questions requiring latest visual knowledge, highlighting important areas for future research.
Interleaved Scene Graph for Interleaved Text-and-Image Generation Assessment
Nov 26, 2024Many real-world user queries (e.g. "How do to make egg fried rice?") could benefit from systems capable of generating responses with both textual steps with accompanying images, similar to a cookbook. Models designed to generate interleaved text and images face challenges in ensuring consistency within and across these modalities. To address these challenges, we present ISG, a comprehensive evaluation framework for interleaved text-and-image generation. ISG leverages a scene graph structure to capture relationships between text and image blocks, evaluating responses on four levels of granularity: holistic, structural, block-level, and image-specific. This multi-tiered evaluation allows for a nuanced assessment of consistency, coherence, and accuracy, and provides interpretable question-answer feedback. In conjunction with ISG, we introduce a benchmark, ISG-Bench, encompassing 1,150 samples across 8 categories and 21 subcategories. This benchmark dataset includes complex language-vision dependencies and golden answers to evaluate models effectively on vision-centric tasks such as style transfer, a challenging area for current models. Using ISG-Bench, we demonstrate that recent unified vision-language models perform poorly on generating interleaved content. While compositional approaches that combine separate language and image models show a 111% improvement over unified models at the holistic level, their performance remains suboptimal at both block and image levels. To facilitate future work, we develop ISG-Agent, a baseline agent employing a "plan-execute-refine" pipeline to invoke tools, achieving a 122% performance improvement.
Coarse Correspondence Elicit 3D Spacetime Understanding in Multimodal Language Model
Aug 01, 2024
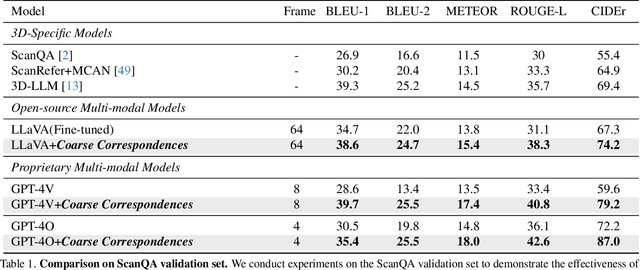
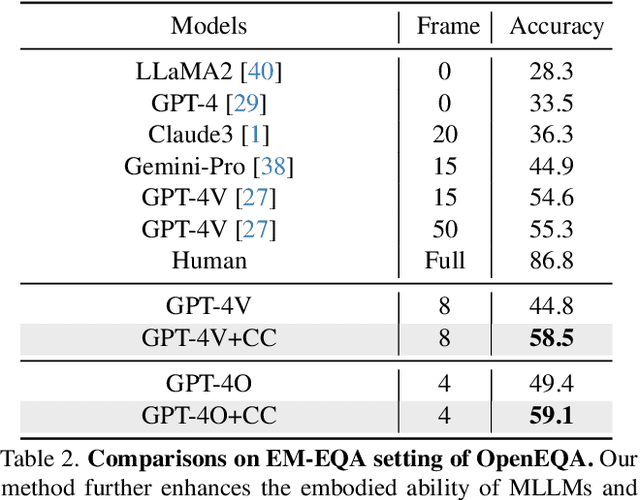

Multimodal language models (MLLMs) are increasingly being implemented in real-world environments, necessitating their ability to interpret 3D spaces and comprehend temporal dynamics. Despite their potential, current top models within our community still fall short in adequately understanding spatial and temporal dimensions. We introduce Coarse Correspondence, a simple, training-free, effective, and general-purpose visual prompting method to elicit 3D and temporal understanding in multimodal LLMs. Our method uses a lightweight tracking model to find object correspondences between frames in a video or between sets of image viewpoints. It selects the most frequent object instances and visualizes them with markers with unique IDs in the image. With this simple approach, we achieve state-of-the-art results on 3D understanding benchmarks including ScanQA (+20.5\%) and a subset of OpenEQA (+9.7\%), and on long-form video benchmarks such as EgoSchema (+6.0\%). We also curate a small diagnostic dataset to evaluate whether MLLMs can reason about space from a described viewpoint other than the camera viewpoint. Again, Coarse Correspondence improves spatial perspective-taking abilities but we highlight that MLLMs struggle with this task. Together, we demonstrate that our simple prompting method can significantly aid downstream tasks that require 3D or temporal reasoning.
Efficient Inference of Vision Instruction-Following Models with Elastic Cache
Jul 25, 2024In the field of instruction-following large vision-language models (LVLMs), the efficient deployment of these models faces challenges, notably due to the high memory demands of their key-value (KV) caches. Conventional cache management strategies for LLMs focus on cache eviction, which often fails to address the specific needs of multimodal instruction-following models. Recognizing this gap, in this paper, we introduce Elastic Cache, a novel approach that benefits from applying distinct acceleration methods for instruction encoding and output generation stages. We investigate the metrics of importance in different stages and propose an importance-driven cache merging strategy to prune redundancy caches. Instead of discarding less important caches, our strategy identifies important key/value vectors as anchor points. Surrounding less important caches are then merged with these anchors, enhancing the preservation of contextual information in the KV caches while yielding an arbitrary acceleration ratio. For instruction encoding, we utilize the frequency to evaluate the importance of caches. Regarding output generation, we prioritize tokens based on their distance with an offset, by which both the initial and most recent tokens are retained. Results on a range of LVLMs demonstrate that Elastic Cache not only boosts efficiency but also notably outperforms existing pruning methods in language generation across various tasks. Code is available at https://github.com/liuzuyan/ElasticCache
Matching-based Data Valuation for Generative Model
Apr 21, 2023Data valuation is critical in machine learning, as it helps enhance model transparency and protect data properties. Existing data valuation methods have primarily focused on discriminative models, neglecting deep generative models that have recently gained considerable attention. Similar to discriminative models, there is an urgent need to assess data contributions in deep generative models as well. However, previous data valuation approaches mainly relied on discriminative model performance metrics and required model retraining. Consequently, they cannot be applied directly and efficiently to recent deep generative models, such as generative adversarial networks and diffusion models, in practice. To bridge this gap, we formulate the data valuation problem in generative models from a similarity-matching perspective. Specifically, we introduce Generative Model Valuator (GMValuator), the first model-agnostic approach for any generative models, designed to provide data valuation for generation tasks. We have conducted extensive experiments to demonstrate the effectiveness of the proposed method. To the best of their knowledge, GMValuator is the first work that offers a training-free, post-hoc data valuation strategy for deep generative models.
TIFA: Accurate and Interpretable Text-to-Image Faithfulness Evaluation with Question Answering
Mar 28, 2023Despite thousands of researchers, engineers, and artists actively working on improving text-to-image generation models, systems often fail to produce images that accurately align with the text inputs. We introduce TIFA (Text-to-Image Faithfulness evaluation with question Answering), an automatic evaluation metric that measures the faithfulness of a generated image to its text input via visual question answering (VQA). Specifically, given a text input, we automatically generate several question-answer pairs using a language model. We calculate image faithfulness by checking whether existing VQA models can answer these questions using the generated image. TIFA is a reference-free metric that allows for fine-grained and interpretable evaluations of generated images. TIFA also has better correlations with human judgments than existing metrics. Based on this approach, we introduce TIFA v1.0, a benchmark consisting of 4K diverse text inputs and 25K questions across 12 categories (object, counting, etc.). We present a comprehensive evaluation of existing text-to-image models using TIFA v1.0 and highlight the limitations and challenges of current models. For instance, we find that current text-to-image models, despite doing well on color and material, still struggle in counting, spatial relations, and composing multiple objects. We hope our benchmark will help carefully measure the research progress in text-to-image synthesis and provide valuable insights for further research.