 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Output Rankings in Generative Engines for LLM-based Search
Feb 03, 2026The way customers search for and choose products is changing with the rise of large language models (LLMs). LLM-based search, or generative engines, provides direct product recommendations to users, rather than traditional online search results that require users to explore options themselves. However, these recommendations are strongly influenced by the initial retrieval order of LLMs, which disadvantages small businesses and independent creators by limiting their visibility. In this work, we propose CORE, an optimization method that \textbf{C}ontrols \textbf{O}utput \textbf{R}ankings in g\textbf{E}nerative Engines for LLM-based search. Since the LLM's interactions with the search engine are black-box, CORE targets the content returned by search engines as the primary means of influencing output rankings. Specifically, CORE optimizes retrieved content by appending strategically designed optimization content to steer the ranking of outputs. We introduce three types of optimization content: string-based, reasoning-based, and review-based, demonstrating their effectiveness in shaping output rankings. To evaluate CORE in realistic settings, we introduce ProductBench, a large-scale benchmark with 15 product categories and 200 products per category, where each product is associated with its top-10 recommendations collected from Amazon's search interface. Extensive experiments on four LLMs with search capabilities (GPT-4o, Gemini-2.5, Claude-4, and Grok-3) demonstrate that CORE achieves an average Promotion Success Rate of \textbf{91.4\% @Top-5}, \textbf{86.6\% @Top-3}, and \textbf{80.3\% @Top-1}, across 15 product categories, outperforming existing ranking manipulation methods while preserving the fluency of optimized content.
MultiRef: Controllable Image Generation with Multiple Visual References
Aug 09, 2025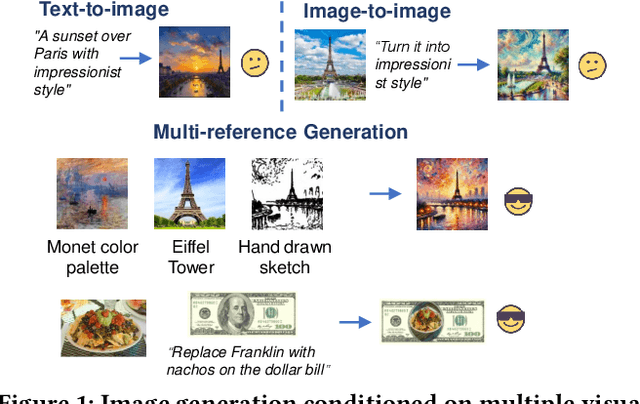
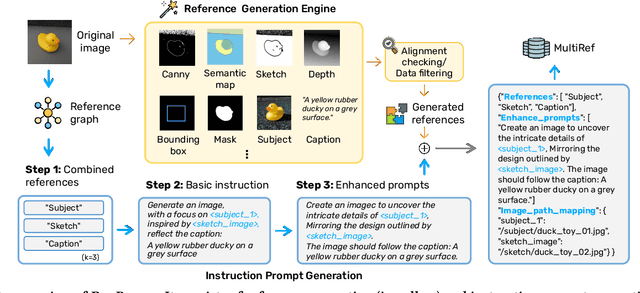
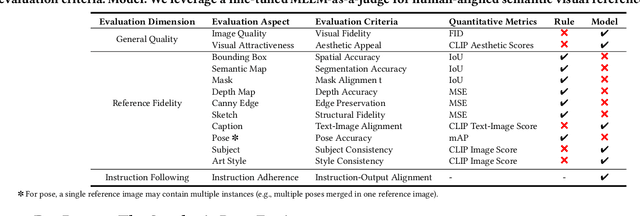
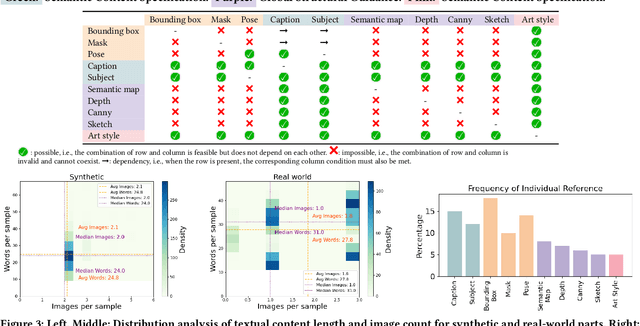
Visual designers naturally draw inspiration from multiple visual references, combining diverse elements and aesthetic principles to create artwork. However, current image generative frameworks predominantly rely on single-source inputs -- either text prompts or individual reference images. In this paper, we focus on the task of controllable image generation using multiple visual references. We introduce MultiRef-bench, a rigorous evaluation framework comprising 990 synthetic and 1,000 real-world samples that require incorporating visual content from multiple reference images. The synthetic samples are synthetically generated through our data engine RefBlend, with 10 reference types and 33 reference combinations. Based on RefBlend, we further construct a dataset MultiRef containing 38k high-quality images to facilitate further research. Our experiments across three interleaved image-text models (i.e., OmniGen, ACE, and Show-o) and six agentic frameworks (e.g., ChatDiT and LLM + SD) reveal that even state-of-the-art systems struggle with multi-reference conditioning, with the best model OmniGen achieving only 66.6% in synthetic samples and 79.0% in real-world cases on average compared to the golden answer. These findings provide valuable directions for developing more flexible and human-like creative tools that can effectively integrate multiple sources of visual inspiration. The dataset is publicly available at: https://multiref.github.io/.
NodeRAG: Structuring Graph-based RAG with Heterogeneous Nodes
Apr 15, 2025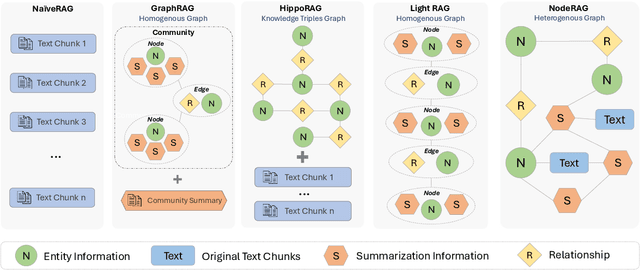
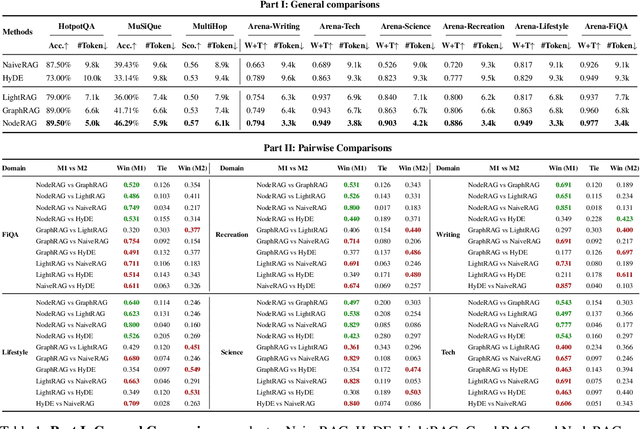
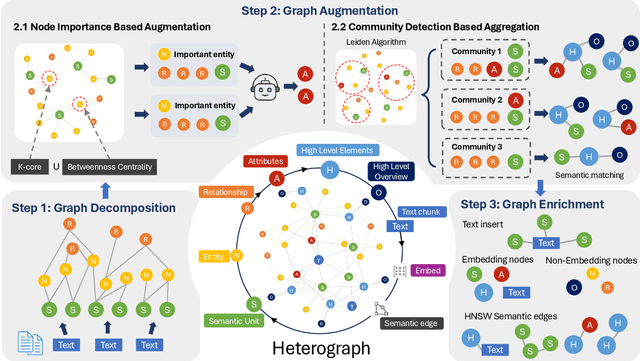
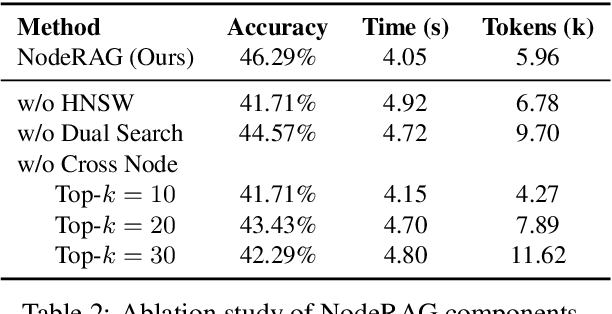
Retrieval-augmented generation (RAG) empowers large language models to access external and private corpus, enabling factually consistent responses in specific domains. By exploiting the inherent structure of the corpus, graph-based RAG methods further enrich this process by building a knowledge graph index and leveraging the structural nature of graphs. However, current graph-based RAG approaches seldom prioritize the design of graph structures. Inadequately designed graph not only impede the seamless integration of diverse graph algorithms but also result in workflow inconsistencies and degraded performance. To further unleash the potential of graph for RAG, we propose NodeRAG, a graph-centric framework introducing heterogeneous graph structures that enable the seamless and holistic integration of graph-based methodologies into the RAG workflow. By aligning closely with the capabilities of LLMs, this framework ensures a fully cohesive and efficient end-to-end process. Through extensive experiments, we demonstrate that NodeRAG exhibits performance advantages over previous methods, including GraphRAG and LightRAG, not only in indexing time, query time, and storage efficiency but also in delivering superior question-answering performance on multi-hop benchmarks and open-ended head-to-head evaluations with minimal retrieval tokens. Our GitHub repository could be seen at https://github.com/Terry-Xu-666/NodeRAG.
Interleaved Scene Graph for Interleaved Text-and-Image Generation Assessment
Nov 26, 2024Many real-world user queries (e.g. "How do to make egg fried rice?") could benefit from systems capable of generating responses with both textual steps with accompanying images, similar to a cookbook. Models designed to generate interleaved text and images face challenges in ensuring consistency within and across these modalities. To address these challenges, we present ISG, a comprehensive evaluation framework for interleaved text-and-image generation. ISG leverages a scene graph structure to capture relationships between text and image blocks, evaluating responses on four levels of granularity: holistic, structural, block-level, and image-specific. This multi-tiered evaluation allows for a nuanced assessment of consistency, coherence, and accuracy, and provides interpretable question-answer feedback. In conjunction with ISG, we introduce a benchmark, ISG-Bench, encompassing 1,150 samples across 8 categories and 21 subcategories. This benchmark dataset includes complex language-vision dependencies and golden answers to evaluate models effectively on vision-centric tasks such as style transfer, a challenging area for current models. Using ISG-Bench, we demonstrate that recent unified vision-language models perform poorly on generating interleaved content. While compositional approaches that combine separate language and image models show a 111% improvement over unified models at the holistic level, their performance remains suboptimal at both block and image levels. To facilitate future work, we develop ISG-Agent, a baseline agent employing a "plan-execute-refine" pipeline to invoke tools, achieving a 122% performance improvement.
Thinking Before Looking: Improving Multimodal LLM Reasoning via Mitigating Visual Hallucination
Nov 15, 2024



Multimodal large language models (MLLMs) have advanced the integration of visual and linguistic modalities, establishing themselves as the dominant paradigm for visual-language tasks. Current approaches like chain of thought (CoT) reasoning have augmented the cognitive capabilities of large language models (LLMs), yet their adaptation to MLLMs is hindered by heightened risks of hallucination in cross-modality comprehension. In this paper, we find that the thinking while looking paradigm in current multimodal CoT approaches--where reasoning chains are generated alongside visual input--fails to mitigate hallucinations caused by misleading images. To address these limitations, we propose the Visual Inference Chain (VIC) framework, a novel approach that constructs reasoning chains using textual context alone before introducing visual input, effectively reducing cross-modal biases and enhancing multimodal reasoning accuracy. Comprehensive evaluations demonstrate that VIC significantly improves zero-shot performance across various vision-related tasks, mitigating hallucinations while refining the reasoning capabilities of MLLMs. Our code repository can be found at https://github.com/Terry-Xu-666/visual_inference_chain.
Investigating and Defending Shortcut Learning in Personalized Diffusion Models
Jun 27, 2024Personalized diffusion models have gained popularity for adapting pre-trained text-to-image models to generate images of specific topics with only a few images. However, recent studies find that these models are vulnerable to minor adversarial perturbation, and the fine-tuning performance is largely degraded on corrupted datasets. Such characteristics are further exploited to craft protective perturbation on sensitive images like portraits that prevent unauthorized generation. In response, diffusion-based purification methods have been proposed to remove these perturbations and retain generation performance. However, existing works lack detailed analysis of the fundamental shortcut learning vulnerability of personalized diffusion models and also turn to over-purifying the images cause information loss. In this paper, we take a closer look at the fine-tuning process of personalized diffusion models through the lens of shortcut learning and propose a hypothesis that could explain the underlying manipulation mechanisms of existing perturbation methods. Specifically, we find that the perturbed images are greatly shifted from their original paired prompt in the CLIP-based latent space. As a result, training with this mismatched image-prompt pair creates a construction that causes the models to dump their out-of-distribution noisy patterns to the identifier, thus causing serious performance degradation. Based on this observation, we propose a systematic approach to retain the training performance with purification that realigns the latent image and its semantic meaning and also introduces contrastive learning with a negative token to decouple the learning of wanted clean identity and the unwanted noisy pattern, that shows strong potential capacity against further adaptive perturbation.
Mora: Enabling Generalist Video Generation via A Multi-Agent Framework
Mar 22, 2024



Sora is the first large-scale generalist video generation model that garnered significant attention across society. Since its launch by OpenAI in February 2024, no other video generation models have paralleled {Sora}'s performance or its capacity to support a broad spectrum of video generation tasks. Additionally, there are only a few fully published video generation models, with the majority being closed-source. To address this gap, this paper proposes a new multi-agent framework Mora, which incorporates several advanced visual AI agents to replicate generalist video generation demonstrated by Sora. In particular, Mora can utilize multiple visual agents and successfully mimic Sora's video generation capabilities in various tasks, such as (1) text-to-video generation, (2) text-conditional image-to-video generation, (3) extend generated videos, (4) video-to-video editing, (5) connect videos and (6) simulate digital worlds. Our extensive experimental results show that Mora achieves performance that is proximate to that of Sora in various tasks. However, there exists an obvious performance gap between our work and Sora when assessed holistically. In summary, we hope this project can guide the future trajectory of video generation through collaborative AI agents.
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Feb 28, 2024



Sora is a text-to-video generative AI model, released by OpenAI in February 2024. The model is trained to generate videos of realistic or imaginative scenes from text instructions and show potential in simulating the physical world. Based on public technical reports and reverse engineering, this paper presents a comprehensive review of the model's background, related technologies, applications, remaining challenges, and future directions of text-to-video AI models. We first trace Sora's development and investigate the underlying technologies used to build this "world simulator". Then, we describe in detail the applications and potential impact of Sora in multiple industries ranging from film-making and education to marketing. We discuss the main challenges and limitations that need to be addressed to widely deploy Sora, such as ensuring safe and unbiased video generation. Lastly, we discuss the future development of Sora and video generation models in general, and how advancements in the field could enable new ways of human-AI interaction, boosting productivity and creativity of video generation.
MLLM-as-a-Judge: Assessing Multimodal LLM-as-a-Judge with Vision-Language Benchmark
Feb 07, 2024Multimodal Large Language Models (MLLMs) have gained significant attention recently, showing remarkable potential in artificial general intelligence. However, assessing the utility of MLLMs presents considerable challenges, primarily due to the absence multimodal benchmarks that align with human preferences. Inspired by LLM-as-a-Judge in LLMs, this paper introduces a novel benchmark, termed MLLM-as-a-Judge, to assess the ability of MLLMs in assisting judges including three distinct tasks: Scoring Evaluation, Pair Comparison, and Batch Ranking. Our study reveals that, while MLLMs demonstrate remarkable human-like discernment in Pair Comparisons, there is a significant divergence from human preferences in Scoring Evaluation and Batch Ranking tasks. Furthermore, MLLMs still face challenges in judgment, including diverse biases, hallucinatory responses, and inconsistencies, even for advanced models such as GPT-4V. These findings emphasize the pressing need for enhancements and further research efforts regarding MLLMs as fully reliable evaluators. Code and dataset are available at https://github.com/Dongping-Chen/MLLM-as-a-Judge.
GUARD: Role-playing to Generate Natural-language Jailbreakings to Test Guideline Adherence of Large Language Models
Feb 05, 2024
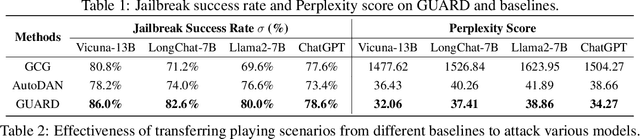


The discovery of "jailbreaks" to bypass safety filters of Large Language Models (LLMs) and harmful responses have encouraged the community to implement safety measures. One major safety measure is to proactively test the LLMs with jailbreaks prior to the release. Therefore, such testing will require a method that can generate jailbreaks massively and efficiently. In this paper, we follow a novel yet intuitive strategy to generate jailbreaks in the style of the human generation. We propose a role-playing system that assigns four different roles to the user LLMs to collaborate on new jailbreaks. Furthermore, we collect existing jailbreaks and split them into different independent characteristics using clustering frequency and semantic patterns sentence by sentence. We organize these characteristics into a knowledge graph, making them more accessible and easier to retrieve. Our system of different roles will leverage this knowledge graph to generate new jailbreaks, which have proved effective in inducing LLMs to generate unethical or guideline-violating responses. In addition, we also pioneer a setting in our system that will automatically follow the government-issued guidelines to generate jailbreaks to test whether LLMs follow the guidelines accordingly. We refer to our system as GUARD (Guideline Upholding through Adaptive Role-play Diagnostics). We have empirically validated the effectiveness of GUARD on three cutting-edge open-sourced LLMs (Vicuna-13B, LongChat-7B, and Llama-2-7B), as well as a widely-utilized commercial LLM (ChatGPT). Moreover, our work extends to the realm of vision language models (MiniGPT-v2 and Gemini Vision Pro), showcasing GUARD's versatility and contributing valuable insights for the development of safer, more reliable LLM-based applications across diverse modalities.