 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-to-Decision Agent: Learning Generalist Policies from Natural Language Supervision
Apr 22, 2025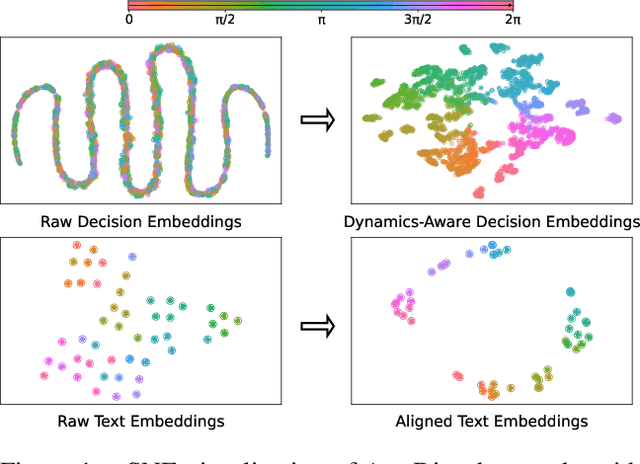

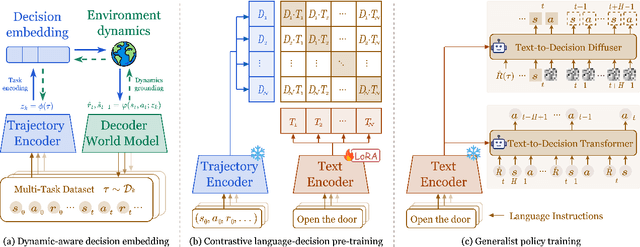
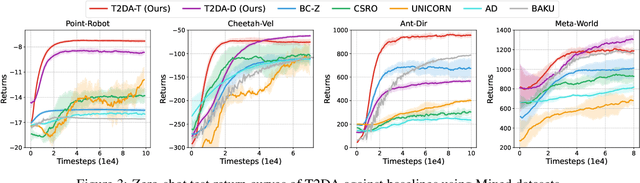
RL systems usually tackle generalization by inferring task beliefs from high-quality samples or warmup explorations. The restricted form limits their generality and usability since these supervision signals are expensive and even infeasible to acquire in advance for unseen tasks. Learning directly from the raw text about decision tasks is a promising alternative to leverage a much broader source of supervision. In the paper, we propose Text-to-Decision Agent (T2DA), a simple and scalable framework that supervises generalist policy learning with natural language. We first introduce a generalized world model to encode multi-task decision data into a dynamics-aware embedding space. Then, inspired by CLIP, we predict which textual description goes with which decision embedding, effectively bridging their semantic gap via contrastive language-decision pre-training and aligning the text embeddings to comprehend the environment dynamics. After training the text-conditioned generalist policy, the agent can directly realize zero-shot text-to-decision generation in response to language instructions. Comprehensive experiments on MuJoCo and Meta-World benchmarks show that T2DA facilitates high-capacity zero-shot generalization and outperforms various types of baselines.
Logic Distillation: Learning from Code Function by Function for Planning and Decision-making
Jul 28, 2024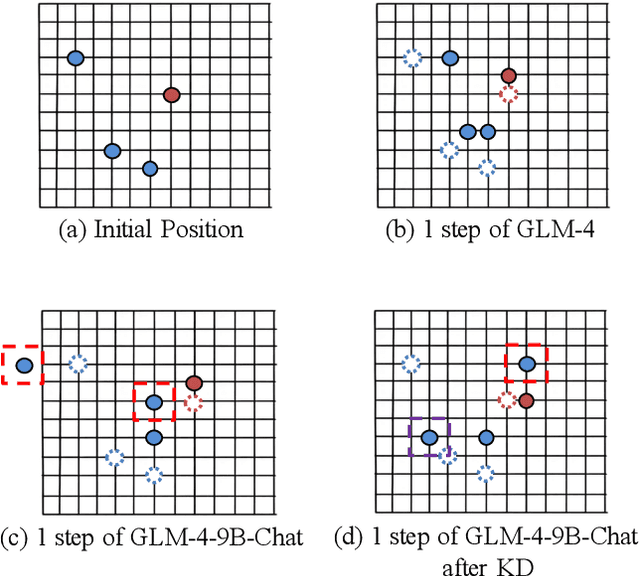
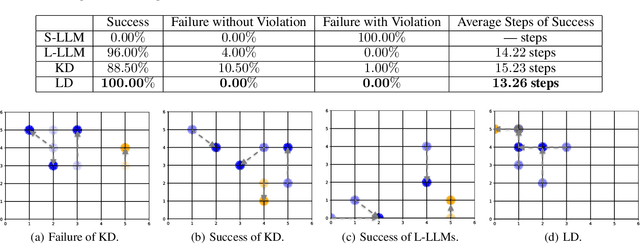
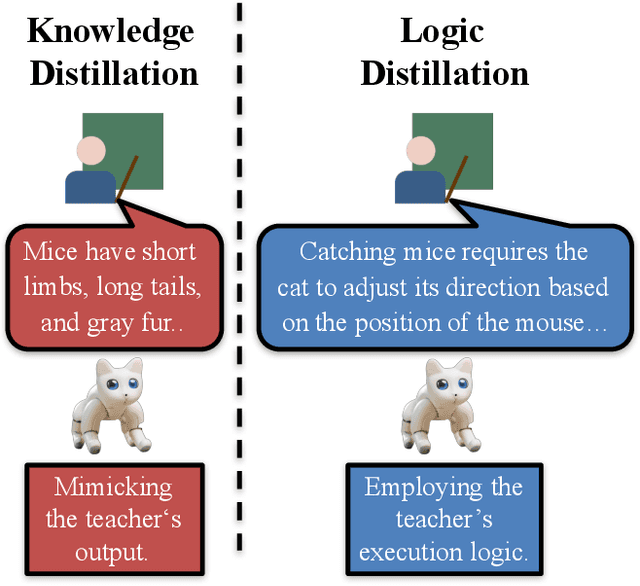

Large language models (LLMs) have garnered increasing attention owing to their powerful logical reasoning capabilities. Generally, larger LLMs (L-LLMs) that require paid interfaces exhibit significantly superior performance compared to smaller LLMs (S-LLMs) that can be deployed on a variety of devices. Knowledge distillation (KD) aims to empower S-LLMs with the capabilities of L-LLMs, while S-LLMs merely mimic the outputs of L-LLMs, failing to get the powerful logical reasoning capabilities. Consequently, S-LLMs are helpless when it comes to planning and decision-making tasks that require logical reasoning capabilities. To tackle the identified challenges, we propose a novel framework called Logic Distillation (LD). Initially, LD employs L-LLMs to instantiate complex instructions into discrete functions and illustrates their usage to establish a function base. Subsequently, based on the function base, LD fine-tunes S-LLMs to learn the logic employed by L-LLMs in planning and decision-making. During testing, LD utilizes a retriever to identify the top-$K$ relevant functions based on instructions and current states, which will be selected and invoked by S-LLMs. Ultimately, S-LLMs yield planning and decision-making outcomes, function by function. Relevant experiments demonstrate that with the assistance of LD, S-LLMs can achieve outstanding results in planning and decision-making tasks, comparable to, or even surpassing, those of L-LLMs.
PyramidInfer: Pyramid KV Cache Compression for High-throughput LLM Inference
May 21, 2024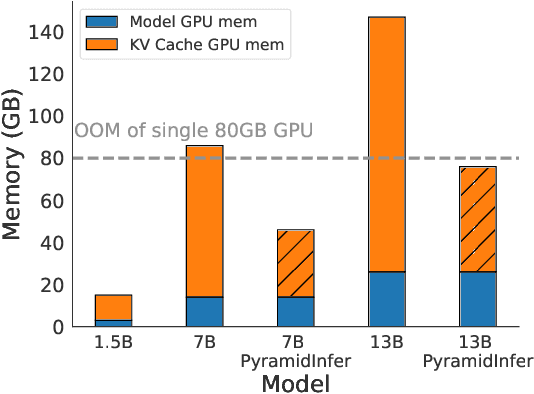
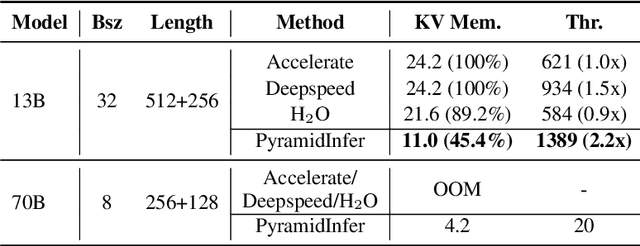


Large Language Models (LLMs) have shown remarkable comprehension abilities but face challenges in GPU memory usage during inference, hindering their scalability for real-time applications like chatbots. To accelerate inference, we store computed keys and values (KV cache) in the GPU memory. Existing methods study the KV cache compression to reduce memory by pruning the pre-computed KV cache. However, they neglect the inter-layer dependency between layers and huge memory consumption in pre-computation. To explore these deficiencies, we find that the number of crucial keys and values that influence future generations decreases layer by layer and we can extract them by the consistency in attention weights. Based on the findings, we propose PyramidInfer, a method that compresses the KV cache by layer-wise retaining crucial context. PyramidInfer saves significant memory by computing fewer keys and values without sacrificing performance. Experimental results show PyramidInfer improves 2.2x throughput compared to Accelerate with over 54% GPU memory reduction in KV cache.
Continual Offline Reinforcement Learning via Diffusion-based Dual Generative Replay
Apr 18, 2024



We study continual offline reinforcement learning, a practical paradigm that facilitates forward transfer and mitigates catastrophic forgetting to tackle sequential offline tasks. We propose a dual generative replay framework that retains previous knowledge by concurrent replay of generated pseudo-data. First, we decouple the continual learning policy into a diffusion-based generative behavior model and a multi-head action evaluation model, allowing the policy to inherit distributional expressivity for encompassing a progressive range of diverse behaviors. Second, we train a task-conditioned diffusion model to mimic state distributions of past tasks. Generated states are paired with corresponding responses from the behavior generator to represent old tasks with high-fidelity replayed samples. Finally, by interleaving pseudo samples with real ones of the new task, we continually update the state and behavior generators to model progressively diverse behaviors, and regularize the multi-head critic via behavior cloning to mitigate forgetting. Experiments demonstrate that our method achieves better forward transfer with less forgetting, and closely approximates the results of using previous ground-truth data due to its high-fidelity replay of the sample space. Our code is available at \href{https://github.com/NJU-RL/CuGRO}{https://github.com/NJU-RL/CuGRO}.
MLLM-as-a-Judge: Assessing Multimodal LLM-as-a-Judge with Vision-Language Benchmark
Feb 07, 2024Multimodal Large Language Models (MLLMs) have gained significant attention recently, showing remarkable potential in artificial general intelligence. However, assessing the utility of MLLMs presents considerable challenges, primarily due to the absence multimodal benchmarks that align with human preferences. Inspired by LLM-as-a-Judge in LLMs, this paper introduces a novel benchmark, termed MLLM-as-a-Judge, to assess the ability of MLLMs in assisting judges including three distinct tasks: Scoring Evaluation, Pair Comparison, and Batch Ranking. Our study reveals that, while MLLMs demonstrate remarkable human-like discernment in Pair Comparisons, there is a significant divergence from human preferences in Scoring Evaluation and Batch Ranking tasks. Furthermore, MLLMs still face challenges in judgment, including diverse biases, hallucinatory responses, and inconsistencies, even for advanced models such as GPT-4V. These findings emphasize the pressing need for enhancements and further research efforts regarding MLLMs as fully reliable evaluators. Code and dataset are available at https://github.com/Dongping-Chen/MLLM-as-a-Judge.
Density Distribution-based Learning Framework for Addressing Online Continual Learning Challenges
Nov 22, 2023In this paper, we address the challenges of online Continual Learning (CL) by introducing a density distribution-based learning framework. CL, especially the Class Incremental Learning, enables adaptation to new test distributions while continuously learning from a single-pass training data stream, which is more in line with the practical application requirements of real-world scenarios. However, existing CL methods often suffer from catastrophic forgetting and higher computing costs due to complex algorithm designs, limiting their practical use. Our proposed framework overcomes these limitations by achieving superior average accuracy and time-space efficiency, bridging the performance gap between CL and classical machine learning. Specifically, we adopt an independent Generative Kernel Density Estimation (GKDE) model for each CL task. During the testing stage, the GKDEs utilize a self-reported max probability density value to determine which one is responsible for predicting incoming test instances. A GKDE-based learning objective can ensure that samples with the same label are grouped together, while dissimilar instances are pushed farther apart. Extensive experiments conducted on multiple CL datasets validate the effectiveness of our proposed framework. Our method outperforms popular CL approaches by a significant margin, while maintaining competitive time-space efficiency, making our framework suitable for real-world applications. Code will be available at https://github.com/xxxx/xxxx.