 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Dirac Delta: Mitigating Diversity Collapse in Reinforcement Fine-Tuning for Versatile Image Generation
Jan 18, 2026Reinforcement learning (RL) has emerged as a powerful paradigm for fine-tuning large-scale generative models, such as diffusion and flow models, to align with complex human preferences and user-specified tasks. A fundamental limitation remains \textit{the curse of diversity collapse}, where the objective formulation and optimization landscape inherently collapse the policy to a Dirac delta distribution. To address this challenge, we propose \textbf{DRIFT} (\textbf{D}ive\textbf{R}sity-\textbf{I}ncentivized Reinforcement \textbf{F}ine-\textbf{T}uning for Versatile Image Generation), an innovative framework that systematically incentivizes output diversity throughout the on-policy fine-tuning process, reconciling strong task alignment with high generation diversity to enhance versatility essential for applications that demand diverse candidate generations. We approach the problem across three representative perspectives: i) \textbf{sampling} a reward-concentrated subset that filters out reward outliers to prevent premature collapse; ii) \textbf{prompting} with stochastic variations to expand the conditioning space, and iii) \textbf{optimization} of the intra-group diversity with a potential-based reward shaping mechanism. Experimental results show that DRIFT achieves superior Pareto dominance regarding task alignment and generation diversity, yielding a $ 9.08\%\!\sim\! 43.46\%$ increase in diversity at equivalent alignment levels and a $ 59.65\% \!\sim\! 65.86\%$ increase in alignment at equivalent levels of diversity.
Continual Offline Reinforcement Learning via Diffusion-based Dual Generative Replay
Apr 18, 2024



We study continual offline reinforcement learning, a practical paradigm that facilitates forward transfer and mitigates catastrophic forgetting to tackle sequential offline tasks. We propose a dual generative replay framework that retains previous knowledge by concurrent replay of generated pseudo-data. First, we decouple the continual learning policy into a diffusion-based generative behavior model and a multi-head action evaluation model, allowing the policy to inherit distributional expressivity for encompassing a progressive range of diverse behaviors. Second, we train a task-conditioned diffusion model to mimic state distributions of past tasks. Generated states are paired with corresponding responses from the behavior generator to represent old tasks with high-fidelity replayed samples. Finally, by interleaving pseudo samples with real ones of the new task, we continually update the state and behavior generators to model progressively diverse behaviors, and regularize the multi-head critic via behavior cloning to mitigate forgetting. Experiments demonstrate that our method achieves better forward transfer with less forgetting, and closely approximates the results of using previous ground-truth data due to its high-fidelity replay of the sample space. Our code is available at \href{https://github.com/NJU-RL/CuGRO}{https://github.com/NJU-RL/CuGRO}.
Efficient Bayesian Policy Reuse with a Scalable Observation Model in Deep Reinforcement Learning
Apr 19, 2022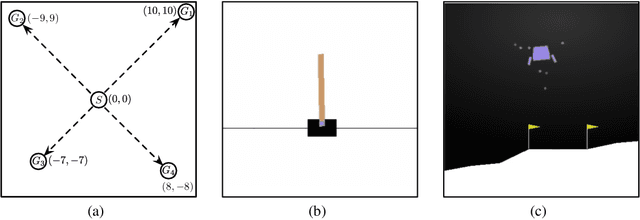

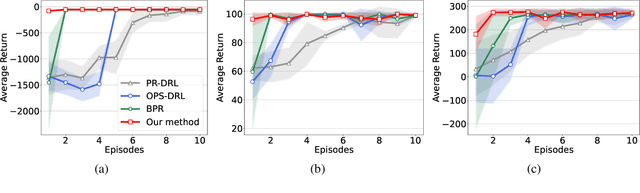

Bayesian policy reuse (BPR) is a general policy transfer framework for selecting a source policy from an offline library by inferring the task belief based on some observation signals and a trained observation model. In this paper, we propose an improved BPR method to achieve more efficient policy transfer in deep reinforcement learning (DRL). First, most BPR algorithms use the episodic return as the observation signal that contains limited information and cannot be obtained until the end of an episode. Instead, we employ the state transition sample, which is informative and instantaneous, as the observation signal for faster and more accurate task inference. Second, BPR algorithms usually require numerous samples to estimate the probability distribution of the tabular-based observation model, which may be expensive and even infeasible to learn and maintain, especially when using the state transition sample as the signal. Hence, we propose a scalable observation model based on fitting state transition functions of source tasks from only a small number of samples, which can generalize to any signals observed in the target task. Moreover, we extend the offline-mode BPR to the continual learning setting by expanding the scalable observation model in a plug-and-play fashion, which can avoid negative transfer when faced with new unknown tasks. Experimental results show that our method can consistently facilitate faster and more efficient policy transfer.