 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Dirac Delta: Mitigating Diversity Collapse in Reinforcement Fine-Tuning for Versatile Image Generation
Jan 18, 2026Reinforcement learning (RL) has emerged as a powerful paradigm for fine-tuning large-scale generative models, such as diffusion and flow models, to align with complex human preferences and user-specified tasks. A fundamental limitation remains \textit{the curse of diversity collapse}, where the objective formulation and optimization landscape inherently collapse the policy to a Dirac delta distribution. To address this challenge, we propose \textbf{DRIFT} (\textbf{D}ive\textbf{R}sity-\textbf{I}ncentivized Reinforcement \textbf{F}ine-\textbf{T}uning for Versatile Image Generation), an innovative framework that systematically incentivizes output diversity throughout the on-policy fine-tuning process, reconciling strong task alignment with high generation diversity to enhance versatility essential for applications that demand diverse candidate generations. We approach the problem across three representative perspectives: i) \textbf{sampling} a reward-concentrated subset that filters out reward outliers to prevent premature collapse; ii) \textbf{prompting} with stochastic variations to expand the conditioning space, and iii) \textbf{optimization} of the intra-group diversity with a potential-based reward shaping mechanism. Experimental results show that DRIFT achieves superior Pareto dominance regarding task alignment and generation diversity, yielding a $ 9.08\%\!\sim\! 43.46\%$ increase in diversity at equivalent alignment levels and a $ 59.65\% \!\sim\! 65.86\%$ increase in alignment at equivalent levels of diversity.
Conditional Diffusion Model for Multi-Agent Dynamic Task Decomposition
Nov 17, 2025Task decomposition has shown promise in complex cooperative multi-agent reinforcement learning (MARL) tasks, which enables efficient hierarchical learning for long-horizon tasks in dynamic and uncertain environments. However, learning dynamic task decomposition from scratch generally requires a large number of training samples, especially exploring the large joint action space under partial observability. In this paper, we present the Conditional Diffusion Model for Dynamic Task Decomposition (C$\text{D}^\text{3}$T), a novel two-level hierarchical MARL framework designed to automatically infer subtask and coordination patterns. The high-level policy learns subtask representation to generate a subtask selection strategy based on subtask effects. To capture the effects of subtasks on the environment, C$\text{D}^\text{3}$T predicts the next observation and reward using a conditional diffusion model. At the low level, agents collaboratively learn and share specialized skills within their assigned subtasks. Moreover, the learned subtask representation is also used as additional semantic information in a multi-head attention mixing network to enhance value decomposition and provide an efficient reasoning bridge between individual and joint value functions. Experimental results on various benchmarks demonstrate that C$\text{D}^\text{3}$T achieves better performance than existing baselines.
Yanyun-3: Enabling Cross-Platform Strategy Game Operation with Vision-Language Models
Nov 17, 2025Automated operation in cross-platform strategy games demands agents with robust generalization across diverse user interfaces and dynamic battlefield conditions. While vision-language models (VLMs) have shown considerable promise in multimodal reasoning, their application to complex human-computer interaction scenarios--such as strategy gaming--remains largely unexplored. Here, we introduce Yanyun-3, a general-purpose agent framework that, for the first time, enables autonomous cross-platform operation across three heterogeneous strategy game environments. By integrating the vision-language reasoning of Qwen2.5-VL with the precise execution capabilities of UI-TARS, Yanyun-3 successfully performs core tasks including target localization, combat resource allocation, and area control. Through systematic ablation studies, we evaluate the effects of various multimodal data combinations--static images, multi-image sequences, and videos--and propose the concept of combination granularity to differentiate between intra-sample fusion and inter-sample mixing strategies. We find that a hybrid strategy, which fuses multi-image and video data while mixing in static images (MV+S), substantially outperforms full fusion: it reduces inference time by 63% and boosts the BLEU-4 score by a factor of 12 (from 4.81% to 62.41%, approximately 12.98x). Operating via a closed-loop pipeline of screen capture, model inference, and action execution, the agent demonstrates strong real-time performance and cross-platform generalization. Beyond providing an efficient solution for strategy game automation, our work establishes a general paradigm for enhancing VLM performance through structured multimodal data organization, offering new insights into the interplay between static perception and dynamic reasoning in embodied intelligence.
Concept Learning for Cooperative Multi-Agent Reinforcement Learning
Jul 27, 2025

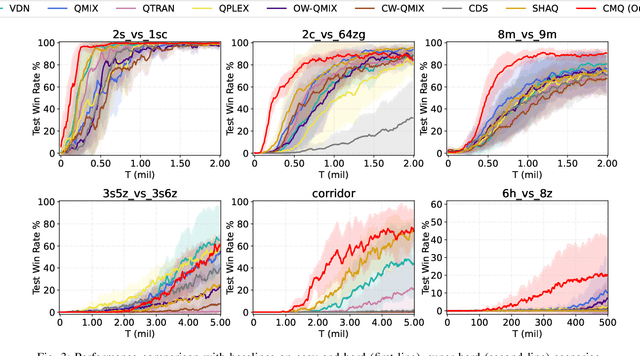

Despite substantial progress in applying neural networks (NN) to multi-agent reinforcement learning (MARL) areas, they still largely suffer from a lack of transparency and interoperability. However, its implicit cooperative mechanism is not yet fully understood due to black-box networks. In this work, we study an interpretable value decomposition framework via concept bottleneck models, which promote trustworthiness by conditioning credit assignment on an intermediate level of human-like cooperation concepts. To address this problem, we propose a novel value-based method, named Concepts learning for Multi-agent Q-learning (CMQ), that goes beyond the current performance-vs-interpretability trade-off by learning interpretable cooperation concepts. CMQ represents each cooperation concept as a supervised vector, as opposed to existing models where the information flowing through their end-to-end mechanism is concept-agnostic. Intuitively, using individual action value conditioning on global state embeddings to represent each concept allows for extra cooperation representation capacity. Empirical evaluations on the StarCraft II micromanagement challenge and level-based foraging (LBF) show that CMQ achieves superior performance compared with the state-of-the-art counterparts. The results also demonstrate that CMQ provides more cooperation concept representation capturing meaningful cooperation modes, and supports test-time concept interventions for detecting potential biases of cooperation mode and identifying spurious artifacts that impact cooperation.
Mixture-of-Experts Meets In-Context Reinforcement Learning
Jun 05, 2025In-context reinforcement learning (ICRL) has emerged as a promising paradigm for adapting RL agents to downstream tasks through prompt conditioning. However, two notable challenges remain in fully harnessing in-context learning within RL domains: the intrinsic multi-modality of the state-action-reward data and the diverse, heterogeneous nature of decision tasks. To tackle these challenges, we propose \textbf{T2MIR} (\textbf{T}oken- and \textbf{T}ask-wise \textbf{M}oE for \textbf{I}n-context \textbf{R}L), an innovative framework that introduces architectural advances of mixture-of-experts (MoE) into transformer-based decision models. T2MIR substitutes the feedforward layer with two parallel layers: a token-wise MoE that captures distinct semantics of input tokens across multiple modalities, and a task-wise MoE that routes diverse tasks to specialized experts for managing a broad task distribution with alleviated gradient conflicts. To enhance task-wise routing, we introduce a contrastive learning method that maximizes the mutual information between the task and its router representation, enabling more precise capture of task-relevant information. The outputs of two MoE components are concatenated and fed into the next layer. Comprehensive experiments show that T2MIR significantly facilitates in-context learning capacity and outperforms various types of baselines. We bring the potential and promise of MoE to ICRL, offering a simple and scalable architectural enhancement to advance ICRL one step closer toward achievements in language and vision communities. Our code is available at https://github.com/NJU-RL/T2MIR.
Divide and Conquer: Grounding LLMs as Efficient Decision-Making Agents via Offline Hierarchical Reinforcement Learning
May 26, 2025While showing sophisticated reasoning abilities, large language models (LLMs) still struggle with long-horizon decision-making tasks due to deficient exploration and long-term credit assignment, especially in sparse-reward scenarios. Inspired by the divide-and-conquer principle, we propose an innovative framework **GLIDER** (**G**rounding **L**anguage Models as Eff**I**cient **D**ecision-Making Agents via Offline Hi**E**rarchical **R**einforcement Learning) that introduces a parameter-efficient and generally applicable hierarchy to LLM policies. We develop a scheme where the low-level controller is supervised with abstract, step-by-step plans that are learned and instructed by the high-level policy. This design decomposes complicated problems into a series of coherent chain-of-thought reasoning sub-tasks, providing flexible temporal abstraction to significantly enhance exploration and learning for long-horizon tasks. Furthermore, GLIDER facilitates fast online adaptation to non-stationary environments owing to the strong transferability of its task-agnostic low-level skills. Experiments on ScienceWorld and ALFWorld benchmarks show that GLIDER achieves consistent performance gains, along with enhanced generalization capabilities.
Learning Diverse Natural Behaviors for Enhancing the Agility of Quadrupedal Robots
May 15, 2025Achieving animal-like agility is a longstanding goal in quadrupedal robotics. While recent studies have successfully demonstrated imitation of specific behaviors, enabling robots to replicate a broader range of natural behaviors in real-world environments remains an open challenge. Here we propose an integrated controller comprising a Basic Behavior Controller (BBC) and a Task-Specific Controller (TSC) which can effectively learn diverse natural quadrupedal behaviors in an enhanced simulator and efficiently transfer them to the real world. Specifically, the BBC is trained using a novel semi-supervised generative adversarial imitation learning algorithm to extract diverse behavioral styles from raw motion capture data of real dogs, enabling smooth behavior transitions by adjusting discrete and continuous latent variable inputs. The TSC, trained via privileged learning with depth images as input, coordinates the BBC to efficiently perform various tasks. Additionally, we employ evolutionary adversarial simulator identification to optimize the simulator, aligning it closely with reality. After training, the robot exhibits diverse natural behaviors, successfully completing the quadrupedal agility challenge at an average speed of 1.1 m/s and achieving a peak speed of 3.2 m/s during hurdling. This work represents a substantial step toward animal-like agility in quadrupedal robots, opening avenues for their deployment in increasingly complex real-world environments.
Text-to-Decision Agent: Learning Generalist Policies from Natural Language Supervision
Apr 22, 2025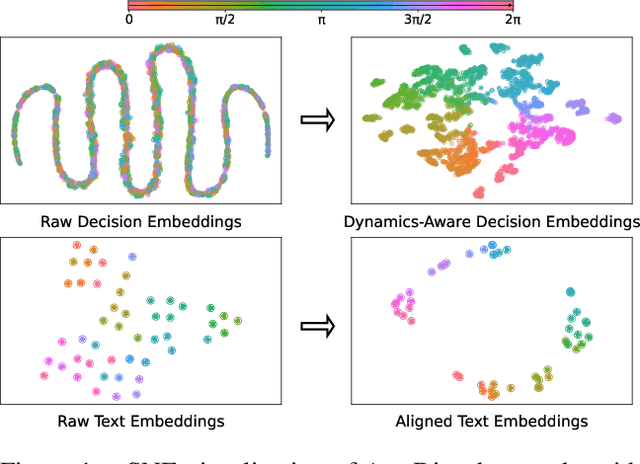

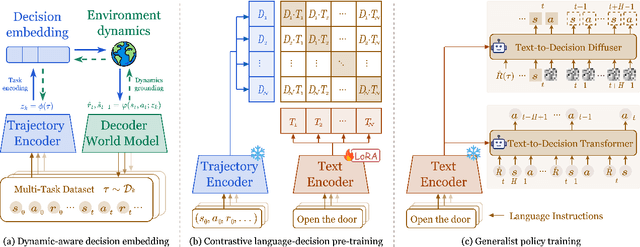
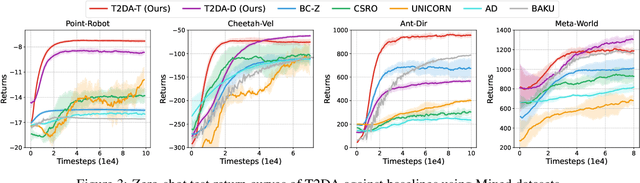
RL systems usually tackle generalization by inferring task beliefs from high-quality samples or warmup explorations. The restricted form limits their generality and usability since these supervision signals are expensive and even infeasible to acquire in advance for unseen tasks. Learning directly from the raw text about decision tasks is a promising alternative to leverage a much broader source of supervision. In the paper, we propose Text-to-Decision Agent (T2DA), a simple and scalable framework that supervises generalist policy learning with natural language. We first introduce a generalized world model to encode multi-task decision data into a dynamics-aware embedding space. Then, inspired by CLIP, we predict which textual description goes with which decision embedding, effectively bridging their semantic gap via contrastive language-decision pre-training and aligning the text embeddings to comprehend the environment dynamics. After training the text-conditioned generalist policy, the agent can directly realize zero-shot text-to-decision generation in response to language instructions. Comprehensive experiments on MuJoCo and Meta-World benchmarks show that T2DA facilitates high-capacity zero-shot generalization and outperforms various types of baselines.
Fast Disentangled Slim Tensor Learning for Multi-view Clustering
Nov 12, 2024



Tensor-based multi-view clustering has recently received significant attention due to its exceptional ability to explore cross-view high-order correlations. However, most existing methods still encounter some limitations. (1) Most of them explore the correlations among different affinity matrices, making them unscalable to large-scale data. (2) Although some methods address it by introducing bipartite graphs, they may result in sub-optimal solutions caused by an unstable anchor selection process. (3) They generally ignore the negative impact of latent semantic-unrelated information in each view. To tackle these issues, we propose a new approach termed fast Disentangled Slim Tensor Learning (DSTL) for multi-view clustering . Instead of focusing on the multi-view graph structures, DSTL directly explores the high-order correlations among multi-view latent semantic representations based on matrix factorization. To alleviate the negative influence of feature redundancy, inspired by robust PCA, DSTL disentangles the latent low-dimensional representation into a semantic-unrelated part and a semantic-related part for each view. Subsequently, two slim tensors are constructed with tensor-based regularization. To further enhance the quality of feature disentanglement, the semantic-related representations are aligned across views through a consensus alignment indicator. Our proposed model is computationally efficient and can be solved effectively. Extensive experiments demonstrate the superiority and efficiency of DSTL over state-of-the-art approaches. The code of DSTL is available at https://github.com/dengxu-nju/DSTL.
Meta-DT: Offline Meta-RL as Conditional Sequence Modeling with World Model Disentanglement
Oct 15, 2024A longstanding goal of artificial general intelligence is highly capable generalists that can learn from diverse experiences and generalize to unseen tasks. The language and vision communities have seen remarkable progress toward this trend by scaling up transformer-based models trained on massive datasets, while reinforcement learning (RL) agents still suffer from poor generalization capacity under such paradigms. To tackle this challenge, we propose Meta Decision Transformer (Meta-DT), which leverages the sequential modeling ability of the transformer architecture and robust task representation learning via world model disentanglement to achieve efficient generalization in offline meta-RL. We pretrain a context-aware world model to learn a compact task representation, and inject it as a contextual condition to the causal transformer to guide task-oriented sequence generation. Then, we subtly utilize history trajectories generated by the meta-policy as a self-guided prompt to exploit the architectural inductive bias. We select the trajectory segment that yields the largest prediction error on the pretrained world model to construct the prompt, aiming to encode task-specific information complementary to the world model maximally. Notably, the proposed framework eliminates the requirement of any expert demonstration or domain knowledge at test time. Experimental results on MuJoCo and Meta-World benchmarks across various dataset types show that Meta-DT exhibits superior few and zero-shot generalization capacity compared to strong baselines while being more practical with fewer prerequisites. Our code is available at https://github.com/NJU-RL/Meta-DT.