 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanizing the Machine: Proxy Attacks to Mislead LLM Detectors
Oct 25, 2024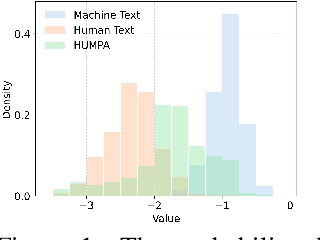
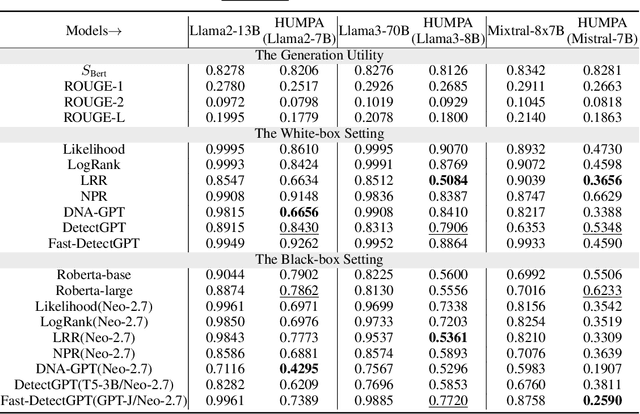
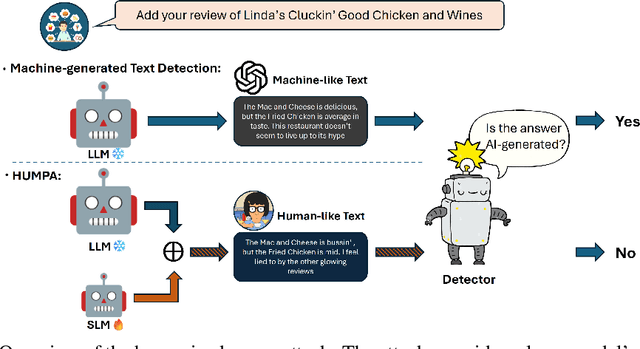
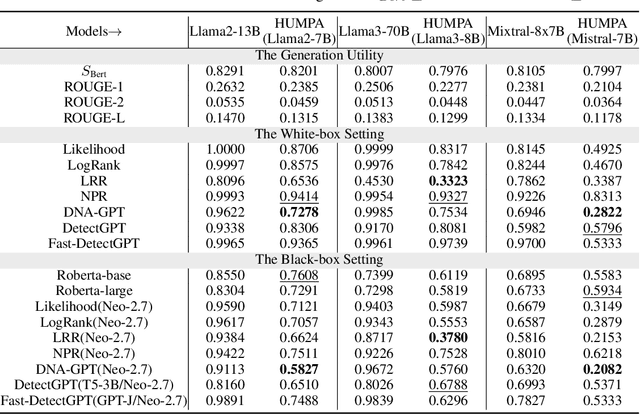
The advent of large language models (LLMs) has revolutionized the field of text generation, producing outputs that closely mimic human-like writing. Although academic and industrial institutions have developed detectors to prevent the malicious usage of LLM-generated texts, other research has doubt about the robustness of these systems. To stress test these detectors, we introduce a proxy-attack strategy that effortlessly compromises LLMs, causing them to produce outputs that align with human-written text and mislead detection systems. Our method attacks the source model by leveraging a reinforcement learning (RL) fine-tuned humanized small language model (SLM) in the decoding phase. Through an in-depth analysis, we demonstrate that our attack strategy is capable of generating responses that are indistinguishable to detectors, preventing them from differentiating between machine-generated and human-written text. We conduct systematic evaluations on extensive datasets using proxy-attacked open-source models, including Llama2-13B, Llama3-70B, and Mixtral-8*7B in both white- and black-box settings. Our findings show that the proxy-attack strategy effectively deceives the leading detectors, resulting in an average AUROC drop of 70.4% across multiple datasets, with a maximum drop of 90.3% on a single dataset. Furthermore, in cross-discipline scenarios, our strategy also bypasses these detectors, leading to a significant relative decrease of up to 90.9%, while in cross-language scenario, the drop reaches 91.3%. Despite our proxy-attack strategy successfully bypassing the detectors with such significant relative drops, we find that the generation quality of the attacked models remains preserved, even within a modest utility budget, when compared to the text produced by the original, unattacked source model.
Through the Theory of Mind's Eye: Reading Minds with Multimodal Video Large Language Models
Jun 19, 2024



Can large multimodal models have a human-like ability for emotional and social reasoning, and if so, how does it work? Recent research has discovered emergent theory-of-mind (ToM) reasoning capabilities in large language models (LLMs). LLMs can reason about people's mental states by solving various text-based ToM tasks that ask questions about the actors' ToM (e.g., human belief, desire, intention). However, human reasoning in the wild is often grounded in dynamic scenes across time. Thus, we consider videos a new medium for examining spatio-temporal ToM reasoning ability. Specifically, we ask explicit probing questions about videos with abundant social and emotional reasoning content. We develop a pipeline for multimodal LLM for ToM reasoning using video and text. We also enable explicit ToM reasoning by retrieving key frames for answering a ToM question, which reveals how multimodal LLMs reason about ToM.
TimeX++: Learning Time-Series Explanations with Information Bottleneck
May 15, 2024Explaining deep learning models operating on time series data is crucial in various applications of interest which require interpretable and transparent insights from time series signals. In this work, we investigate this problem from an information theoretic perspective and show that most existing measures of explainability may suffer from trivial solutions and distributional shift issues. To address these issues, we introduce a simple yet practical objective function for time series explainable learning. The design of the objective function builds upon the principle of information bottleneck (IB), and modifies the IB objective function to avoid trivial solutions and distributional shift issues. We further present TimeX++, a novel explanation framework that leverages a parametric network to produce explanation-embedded instances that are both in-distributed and label-preserving. We evaluate TimeX++ on both synthetic and real-world datasets comparing its performance against leading baselines, and validate its practical efficacy through case studies in a real-world environmental application. Quantitative and qualitative evaluations show that TimeX++ outperforms baselines across all datasets, demonstrating a substantial improvement in explanation quality for time series data. The source code is available at \url{https://github.com/zichuan-liu/TimeXplusplus}.
Protecting Your LLMs with Information Bottleneck
Apr 22, 2024



The advent of large language models (LLMs) has revolutionized the field of natural language processing, yet they might be attacked to produce harmful content. Despite efforts to ethically align LLMs, these are often fragile and can be circumvented by jailbreaking attacks through optimized or manual adversarial prompts. To address this, we introduce the Information Bottleneck Protector (IBProtector), a defense mechanism grounded in the information bottleneck principle, and we modify the objective to avoid trivial solutions. The IBProtector selectively compresses and perturbs prompts, facilitated by a lightweight and trainable extractor, preserving only essential information for the target LLMs to respond with the expected answer. Moreover, we further consider a situation where the gradient is not visible to be compatible with any LLM. Our empirical evaluations show that IBProtector outperforms current defense methods in mitigating jailbreak attempts, without overly affecting response quality or inference speed. Its effectiveness and adaptability across various attack methods and target LLMs underscore the potential of IBProtector as a novel, transferable defense that bolsters the security of LLMs without requiring modifications to the underlying models.
Parametric Augmentation for Time Series Contrastive Learning
Feb 16, 2024



Modern techniques like contrastive learning have been effectively used in many areas, including computer vision, natural language processing, and graph-structured data. Creating positive examples that assist the model in learning robust and discriminative representations is a crucial stage in contrastive learning approaches. Usually, preset human intuition directs the selection of relevant data augmentations. Due to patterns that are easily recognized by humans, this rule of thumb works well in the vision and language domains. However, it is impractical to visually inspect the temporal structures in time series. The diversity of time series augmentations at both the dataset and instance levels makes it difficult to choose meaningful augmentations on the fly. In this study, we address this gap by analyzing time series data augmentation using information theory and summarizing the most commonly adopted augmentations in a unified format. We then propose a contrastive learning framework with parametric augmentation, AutoTCL, which can be adaptively employed to support time series representation learning. The proposed approach is encoder-agnostic, allowing it to be seamlessly integrated with different backbone encoders. Experiments on univariate forecasting tasks demonstrate the highly competitive results of our method, with an average 6.5\% reduction in MSE and 4.7\% in MAE over the leading baselines. In classification tasks, AutoTCL achieves a $1.2\%$ increase in average accuracy.
PAC Learnability under Explanation-Preserving Graph Perturbations
Feb 07, 2024
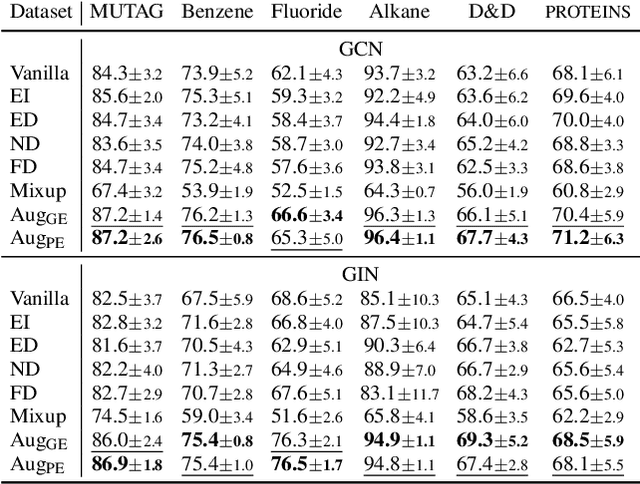

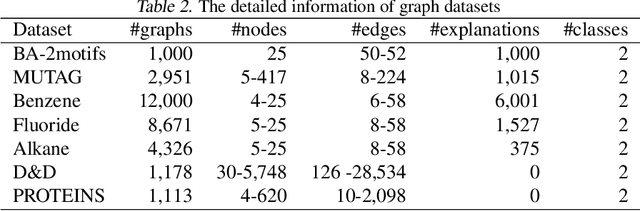
Graphical models capture relations between entities in a wide range of applications including social networks, biology, and natural language processing, among others. Graph neural networks (GNN) are neural models that operate over graphs, enabling the model to leverage the complex relationships and dependencies in graph-structured data. A graph explanation is a subgraph which is an `almost sufficient' statistic of the input graph with respect to its classification label. Consequently, the classification label is invariant, with high probability, to perturbations of graph edges not belonging to its explanation subgraph. This work considers two methods for leveraging such perturbation invariances in the design and training of GNNs. First, explanation-assisted learning rules are considered. It is shown that the sample complexity of explanation-assisted learning can be arbitrarily smaller than explanation-agnostic learning. Next, explanation-assisted data augmentation is considered, where the training set is enlarged by artificially producing new training samples via perturbation of the non-explanation edges in the original training set. It is shown that such data augmentation methods may improve performance if the augmented data is in-distribution, however, it may also lead to worse sample complexity compared to explanation-agnostic learning rules if the augmented data is out-of-distribution. Extensive empirical evaluations are provided to verify the theoretical analysis.
Explaining Time Series via Contrastive and Locally Sparse Perturbations
Jan 29, 2024



Explaining multivariate time series is a compound challenge, as it requires identifying important locations in the time series and matching complex temporal patterns. Although previous saliency-based methods addressed the challenges, their perturbation may not alleviate the distribution shift issue, which is inevitable especially in heterogeneous samples. We present ContraLSP, a locally sparse model that introduces counterfactual samples to build uninformative perturbations but keeps distribution using contrastive learning. Furthermore, we incorporate sample-specific sparse gates to generate more binary-skewed and smooth masks, which easily integrate temporal trends and select the salient features parsimoniously. Empirical studies on both synthetic and real-world datasets show that ContraLSP outperforms state-of-the-art models, demonstrating a substantial improvement in explanation quality for time series data. The source code is available at \url{https://github.com/zichuan-liu/ContraLSP}.
DyExplainer: Explainable Dynamic Graph Neural Networks
Oct 25, 2023



Graph Neural Networks (GNNs) resurge as a trending research subject owing to their impressive ability to capture representations from graph-structured data. However, the black-box nature of GNNs presents a significant challenge in terms of comprehending and trusting these models, thereby limiting their practical applications in mission-critical scenarios. Although there has been substantial progress in the field of explaining GNNs in recent years, the majority of these studies are centered on static graphs, leaving the explanation of dynamic GNNs largely unexplored. Dynamic GNNs, with their ever-evolving graph structures, pose a unique challenge and require additional efforts to effectively capture temporal dependencies and structural relationships. To address this challenge, we present DyExplainer, a novel approach to explaining dynamic GNNs on the fly. DyExplainer trains a dynamic GNN backbone to extract representations of the graph at each snapshot, while simultaneously exploring structural relationships and temporal dependencies through a sparse attention technique. To preserve the desired properties of the explanation, such as structural consistency and temporal continuity, we augment our approach with contrastive learning techniques to provide priori-guided regularization. To model longer-term temporal dependencies, we develop a buffer-based live-updating scheme for training. The results of our extensive experiments on various datasets demonstrate the superiority of DyExplainer, not only providing faithful explainability of the model predictions but also significantly improving the model prediction accuracy, as evidenced in the link prediction task.
Towards Robust Fidelity for Evaluating Explainability of Graph Neural Networks
Oct 03, 2023Graph Neural Networks (GNNs) are neural models that leverage the dependency structure in graphical data via message passing among the graph nodes. GNNs have emerged as pivotal architectures in analyzing graph-structured data, and their expansive application in sensitive domains requires a comprehensive understanding of their decision-making processes -- necessitating a framework for GNN explainability. An explanation function for GNNs takes a pre-trained GNN along with a graph as input, to produce a `sufficient statistic' subgraph with respect to the graph label. A main challenge in studying GNN explainability is to provide fidelity measures that evaluate the performance of these explanation functions. This paper studies this foundational challenge, spotlighting the inherent limitations of prevailing fidelity metrics, including $Fid_+$, $Fid_-$, and $Fid_\Delta$. Specifically, a formal, information-theoretic definition of explainability is introduced and it is shown that existing metrics often fail to align with this definition across various statistical scenarios. The reason is due to potential distribution shifts when subgraphs are removed in computing these fidelity measures. Subsequently, a robust class of fidelity measures are introduced, and it is shown analytically that they are resilient to distribution shift issues and are applicable in a wide range of scenarios. Extensive empirical analysis on both synthetic and real datasets are provided to illustrate that the proposed metrics are more coherent with gold standard metrics.
GC-Flow: A Graph-Based Flow Network for Effective Clustering
May 26, 2023



Graph convolutional networks (GCNs) are \emph{discriminative models} that directly model the class posterior $p(y|\mathbf{x})$ for semi-supervised classification of graph data. While being effective, as a representation learning approach, the node representations extracted from a GCN often miss useful information for effective clustering, because the objectives are different. In this work, we design normalizing flows that replace GCN layers, leading to a \emph{generative model} that models both the class conditional likelihood $p(\mathbf{x}|y)$ and the class prior $p(y)$. The resulting neural network, GC-Flow, retains the graph convolution operations while being equipped with a Gaussian mixture representation space. It enjoys two benefits: it not only maintains the predictive power of GCN, but also produces well-separated clusters, due to the structuring of the representation space. We demonstrate these benefits on a variety of benchmark data sets. Moreover, we show that additional parameterization, such as that on the adjacency matrix used for graph convolutions, yields additional improvement in clustering.