 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaPulse: Detecting Anomalies by Tuning in to the Causal Rhythms of Time Series
Aug 06, 2025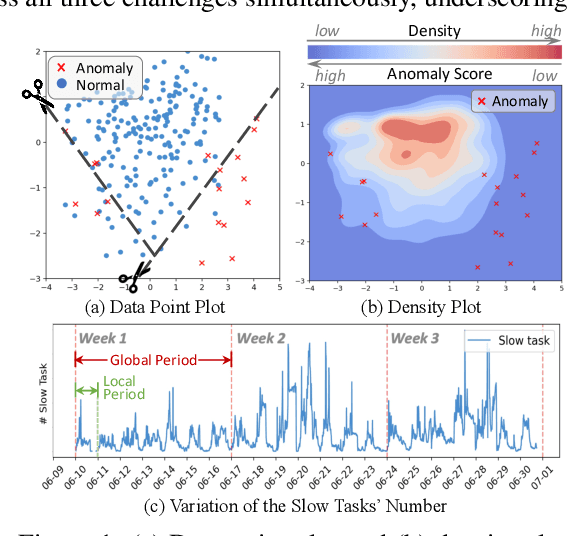
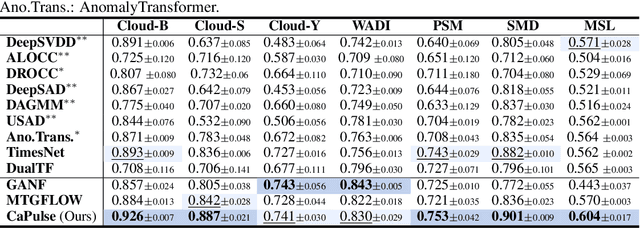

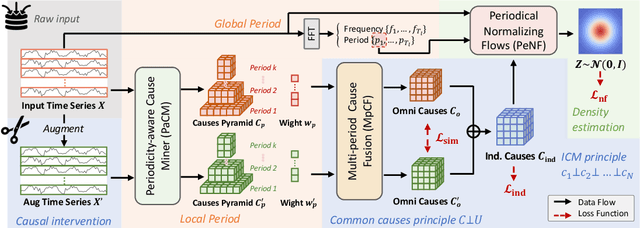
Time series anomaly detection has garnered considerable attention across diverse domains. While existing methods often fail to capture the underlying mechanisms behind anomaly generation in time series data. In addition, time series anomaly detection often faces several data-related inherent challenges, i.e., label scarcity, data imbalance, and complex multi-periodicity. In this paper, we leverage causal tools and introduce a new causality-based framework, CaPulse, which tunes in to the underlying causal pulse of time series data to effectively detect anomalies. Concretely, we begin by building a structural causal model to decipher the generation processes behind anomalies. To tackle the challenges posed by the data, we propose Periodical Normalizing Flows with a novel mask mechanism and carefully designed periodical learners, creating a periodicity-aware, density-based anomaly detection approach. Extensive experiments on seven real-world datasets demonstrate that CaPulse consistently outperforms existing methods, achieving AUROC improvements of 3% to 17%, with enhanced interpretability.
RCRank: Multimodal Ranking of Root Causes of Slow Queries in Cloud Database Systems
Mar 06, 2025



With the continued migration of storage to cloud database systems,the impact of slow queries in such systems on services and user experience is increasing. Root-cause diagnosis plays an indispensable role in facilitating slow-query detection and revision. This paper proposes a method capable of both identifying possible root cause types for slow queries and ranking these according to their potential for accelerating slow queries. This enables prioritizing root causes with the highest impact, in turn improving slow-query revision effectiveness. To enable more accurate and detailed diagnoses, we propose the multimodal Ranking for the Root Causes of slow queries (RCRank) framework, which formulates root cause analysis as a multimodal machine learning problem and leverages multimodal information from query statements, execution plans, execution logs, and key performance indicators. To obtain expressive embeddings from its heterogeneous multimodal input, RCRank integrates self-supervised pre-training that enhances cross-modal alignment and task relevance. Next, the framework integrates root-cause-adaptive cross Transformers that enable adaptive fusion of multimodal features with varying characteristics. Finally, the framework offers a unified model that features an impact-aware training objective for identifying and ranking root causes. We report on experiments on real and synthetic datasets, finding that RCRank is capable of consistently outperforming the state-of-the-art methods at root cause identification and ranking according to a range of metrics.
Cluster-Wide Task Slowdown Detection in Cloud System
Aug 08, 2024



Slow task detection is a critical problem in cloud operation and maintenance since it is highly related to user experience and can bring substantial liquidated damages. Most anomaly detection methods detect it from a single-task aspect. However, considering millions of concurrent tasks in large-scale cloud computing clusters, it becomes impractical and inefficient. Moreover, single-task slowdowns are very common and do not necessarily indicate a malfunction of a cluster due to its violent fluctuation nature in a virtual environment. Thus, we shift our attention to cluster-wide task slowdowns by utilizing the duration time distribution of tasks across a cluster, so that the computation complexity is not relevant to the number of tasks. The task duration time distribution often exhibits compound periodicity and local exceptional fluctuations over time. Though transformer-based methods are one of the most powerful methods to capture these time series normal variation patterns, we empirically find and theoretically explain the flaw of the standard attention mechanism in reconstructing subperiods with low amplitude when dealing with compound periodicity. To tackle these challenges, we propose SORN (i.e., Skimming Off subperiods in descending amplitude order and Reconstructing Non-slowing fluctuation), which consists of a Skimming Attention mechanism to reconstruct the compound periodicity and a Neural Optimal Transport module to distinguish cluster-wide slowdowns from other exceptional fluctuations. Furthermore, since anomalies in the training set are inevitable in a practical scenario, we propose a picky loss function, which adaptively assigns higher weights to reliable time slots in the training set. Extensive experiments demonstrate that SORN outperforms state-of-the-art methods on multiple real-world industrial datasets.
Explaining Time Series via Contrastive and Locally Sparse Perturbations
Jan 29, 2024



Explaining multivariate time series is a compound challenge, as it requires identifying important locations in the time series and matching complex temporal patterns. Although previous saliency-based methods addressed the challenges, their perturbation may not alleviate the distribution shift issue, which is inevitable especially in heterogeneous samples. We present ContraLSP, a locally sparse model that introduces counterfactual samples to build uninformative perturbations but keeps distribution using contrastive learning. Furthermore, we incorporate sample-specific sparse gates to generate more binary-skewed and smooth masks, which easily integrate temporal trends and select the salient features parsimoniously. Empirical studies on both synthetic and real-world datasets show that ContraLSP outperforms state-of-the-art models, demonstrating a substantial improvement in explanation quality for time series data. The source code is available at \url{https://github.com/zichuan-liu/ContraLSP}.
MACE: A Multi-pattern Accommodated and Efficient Anomaly Detection Method in the Frequency Domain
Nov 26, 2023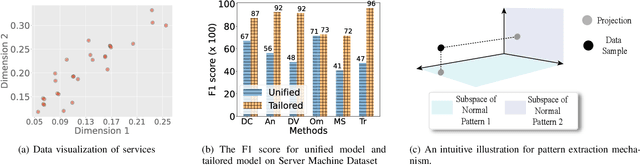
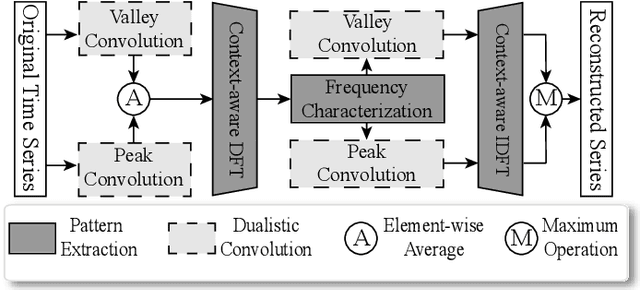
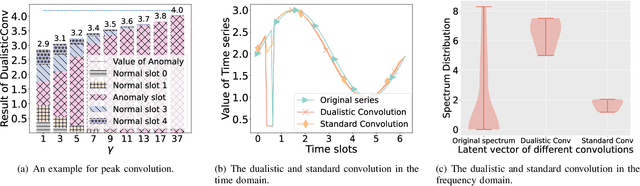
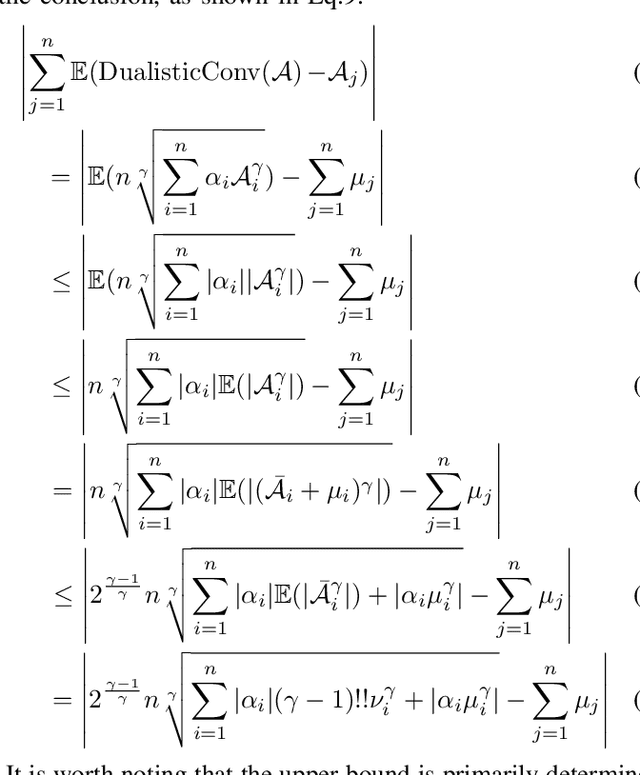
Anomaly detection significantly enhances the robustness of cloud systems. While neural network-based methods have recently demonstrated strong advantages, they encounter practical challenges in cloud environments: the contradiction between the impracticality of maintaining a unique model for each service and the limited ability of dealing with diverse normal patterns by a unified model, as well as issues with handling heavy traffic in real time and short-term anomaly detection sensitivity. Thus, we propose MACE, a Multi-pattern Accommodated and efficient Anomaly detection method in the frequency domain for time series anomaly detection. There are three novel characteristics of it: (i) a pattern extraction mechanism excelling at handling diverse normal patterns, which enables the model to identify anomalies by examining the correlation between the data sample and its service normal pattern, instead of solely focusing on the data sample itself; (ii) a dualistic convolution mechanism that amplifies short-term anomalies in the time domain and hinders the reconstruction of anomalies in the frequency domain, which enlarges the reconstruction error disparity between anomaly and normality and facilitates anomaly detection; (iii) leveraging the sparsity and parallelism of frequency domain to enhance model efficiency. We theoretically and experimentally prove that using a strategically selected subset of Fourier bases can not only reduce computational overhead but is also profit to distinguish anomalies, compared to using the complete spectrum. Moreover, extensive experiments demonstrate MACE's effectiveness in handling diverse normal patterns with a unified model and it achieves state-of-the-art performance with high efficiency. \end{abstract}
RCAgent: Cloud Root Cause Analysis by Autonomous Agents with Tool-Augmented Large Language Models
Oct 25, 2023



Large language model (LLM) applications in cloud root cause analysis (RCA) have been actively explored recently. However, current methods are still reliant on manual workflow settings and do not unleash LLMs' decision-making and environment interaction capabilities. We present RCAgent, a tool-augmented LLM autonomous agent framework for practical and privacy-aware industrial RCA usage. Running on an internally deployed model rather than GPT families, RCAgent is capable of free-form data collection and comprehensive analysis with tools. Our framework combines a variety of enhancements, including a unique Self-Consistency for action trajectories, and a suite of methods for context management, stabilization, and importing domain knowledge. Our experiments show RCAgent's evident and consistent superiority over ReAct across all aspects of RCA -- predicting root causes, solutions, evidence, and responsibilities -- and tasks covered or uncovered by current rules, as validated by both automated metrics and human evaluations. Furthermore, RCAgent has already been integrated into the diagnosis and issue discovery workflow of the Real-time Compute Platform for Apache Flink of Alibaba Cloud.
CloudRCA: A Root Cause Analysis Framework for Cloud Computing Platforms
Nov 05, 2021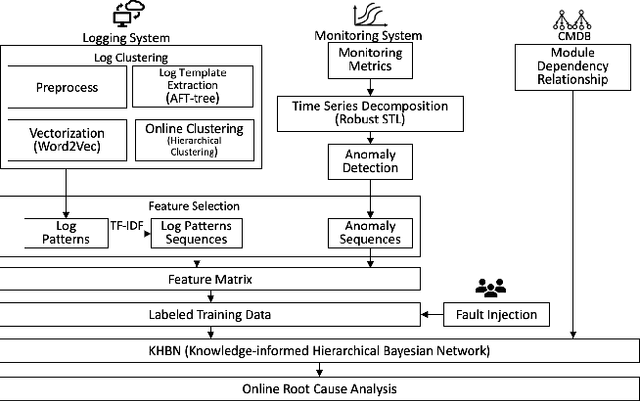
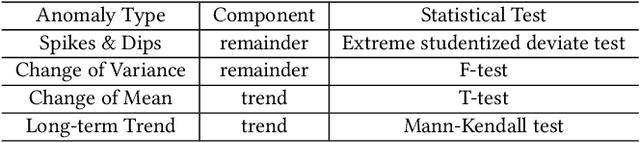
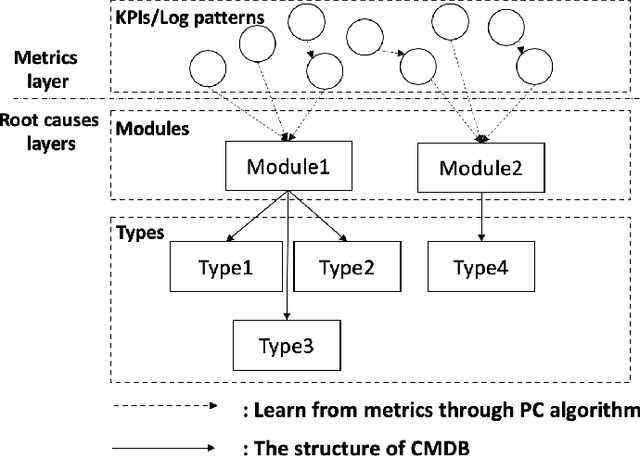

As business of Alibaba expands across the world among various industries, higher standards are imposed on the service quality and reliability of big data cloud computing platforms which constitute the infrastructure of Alibaba Cloud. However, root cause analysis in these platforms is non-trivial due to the complicated system architecture. In this paper, we propose a root cause analysis framework called CloudRCA which makes use of heterogeneous multi-source data including Key Performance Indicators (KPIs), logs, as well as topology, and extracts important features via state-of-the-art anomaly detection and log analysis techniques. The engineered features are then utilized in a Knowledge-informed Hierarchical Bayesian Network (KHBN) model to infer root causes with high accuracy and efficiency. Ablation study and comprehensive experimental comparisons demonstrate that, compared to existing frameworks, CloudRCA 1) consistently outperforms existing approaches in f1-score across different cloud systems; 2) can handle novel types of root causes thanks to the hierarchical structure of KHBN; 3) performs more robustly with respect to algorithmic configurations; and 4) scales more favorably in the data and feature sizes. Experiments also show that a cross-platform transfer learning mechanism can be adopted to further improve the accuracy by more than 10\%. CloudRCA has been integrated into the diagnosis system of Alibaba Cloud and employed in three typical cloud computing platforms including MaxCompute, Realtime Compute and Hologres. It saves Site Reliability Engineers (SREs) more than $20\%$ in the time spent on resolving failures in the past twelve months and improves service reliability significantly.
* Accepted by CIKM 2021; 10 pages, 3 figures, 12 tables