 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Agents for Education: Advances and Applications
Mar 14, 2025Large Language Model (LLM) agents have demonstrated remarkable capabilities in automating tasks and driving innovation across diverse educational applications. In this survey, we provide a systematic review of state-of-the-art research on LLM agents in education, categorizing them into two broad classes: (1) \emph{Pedagogical Agents}, which focus on automating complex pedagogical tasks to support both teachers and students; and (2) \emph{Domain-Specific Educational Agents}, which are tailored for specialized fields such as science education, language learning, and professional development. We comprehensively examine the technological advancements underlying these LLM agents, including key datasets, benchmarks, and algorithmic frameworks that drive their effectiveness. Furthermore, we discuss critical challenges such as privacy, bias and fairness concerns, hallucination mitigation, and integration with existing educational ecosystems. This survey aims to provide a comprehensive technological overview of LLM agents for education, fostering further research and collaboration to enhance their impact for the greater good of learners and educators alike.
LAG: LLM agents for Leaderboard Auto Generation on Demanding
Feb 25, 2025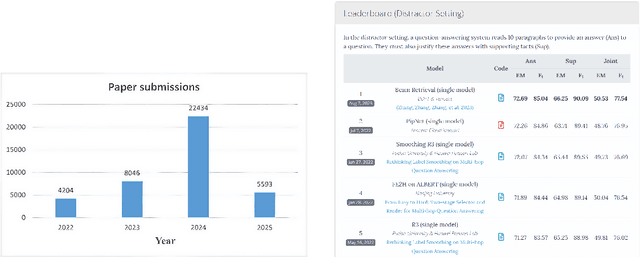
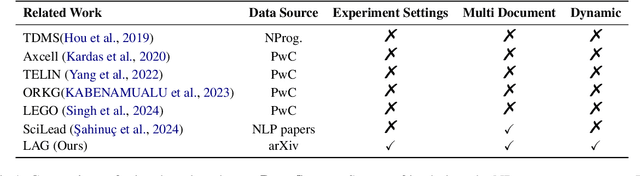
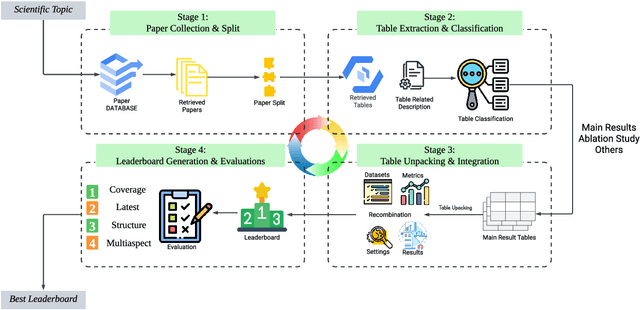

This paper introduces Leaderboard Auto Generation (LAG), a novel and well-organized framework for automatic generation of leaderboards on a given research topic in rapidly evolving fields like Artificial Intelligence (AI). Faced with a large number of AI papers updated daily, it becomes difficult for researchers to track every paper's proposed methods, experimental results, and settings, prompting the need for efficient automatic leaderboard construction. While large language models (LLMs) offer promise in automating this process, challenges such as multi-document summarization, leaderboard generation, and experiment fair comparison still remain under exploration. LAG solves these challenges through a systematic approach that involves the paper collection, experiment results extraction and integration, leaderboard generation, and quality evaluation. Our contributions include a comprehensive solution to the leaderboard construction problem, a reliable evaluation method, and experimental results showing the high quality of leaderboards.
ErrorRadar: Benchmarking Complex Mathematical Reasoning of Multimodal Large Language Models Via Error Detection
Oct 06, 2024


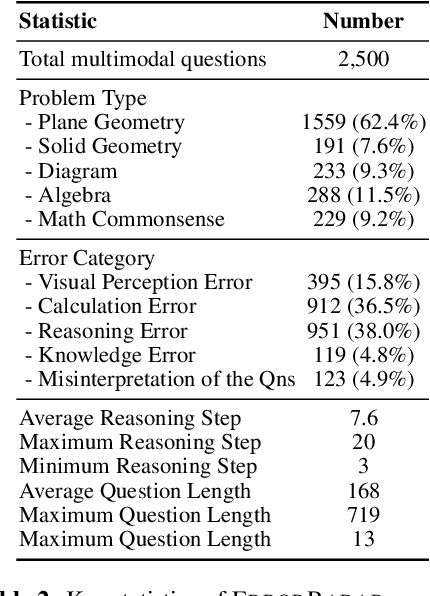
As the field of Multimodal Large Language Models (MLLMs) continues to evolve, their potential to revolutionize artificial intelligence is particularly promising, especially in addressing mathematical reasoning tasks. Current mathematical benchmarks predominantly focus on evaluating MLLMs' problem-solving ability, yet there is a crucial gap in addressing more complex scenarios such as error detection, for enhancing reasoning capability in complicated settings. To fill this gap, we formally formulate the new task: multimodal error detection, and introduce ErrorRadar, the first benchmark designed to assess MLLMs' capabilities in such a task. ErrorRadar evaluates two sub-tasks: error step identification and error categorization, providing a comprehensive framework for evaluating MLLMs' complex mathematical reasoning ability. It consists of 2,500 high-quality multimodal K-12 mathematical problems, collected from real-world student interactions in an educational organization, with rigorous annotation and rich metadata such as problem type and error category. Through extensive experiments, we evaluated both open-source and closed-source representative MLLMs, benchmarking their performance against educational expert evaluators. Results indicate significant challenges still remain, as GPT-4o with best performance is still around 10% behind human evaluation. The dataset will be available upon acceptance.
Mind Scramble: Unveiling Large Language Model Psychology Via Typoglycemia
Oct 02, 2024



Research into the external behaviors and internal mechanisms of large language models (LLMs) has shown promise in addressing complex tasks in the physical world. Studies suggest that powerful LLMs, like GPT-4, are beginning to exhibit human-like cognitive abilities, including planning, reasoning, and reflection. In this paper, we introduce a research line and methodology called LLM Psychology, leveraging human psychology experiments to investigate the cognitive behaviors and mechanisms of LLMs. We migrate the Typoglycemia phenomenon from psychology to explore the "mind" of LLMs. Unlike human brains, which rely on context and word patterns to comprehend scrambled text, LLMs use distinct encoding and decoding processes. Through Typoglycemia experiments at the character, word, and sentence levels, we observe: (I) LLMs demonstrate human-like behaviors on a macro scale, such as lower task accuracy and higher token/time consumption; (II) LLMs exhibit varying robustness to scrambled input, making Typoglycemia a benchmark for model evaluation without new datasets; (III) Different task types have varying impacts, with complex logical tasks (e.g., math) being more challenging in scrambled form; (IV) Each LLM has a unique and consistent "cognitive pattern" across tasks, revealing general mechanisms in its psychology process. We provide an in-depth analysis of hidden layers to explain these phenomena, paving the way for future research in LLM Psychology and deeper interpretability.
LogParser-LLM: Advancing Efficient Log Parsing with Large Language Models
Aug 25, 2024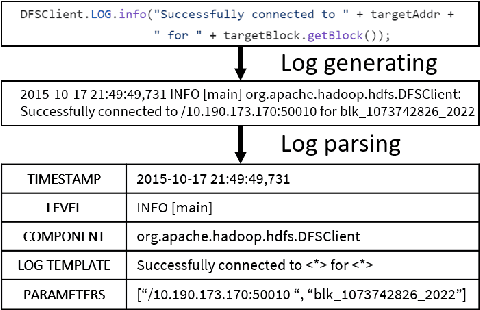
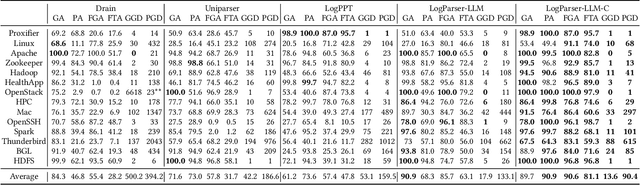
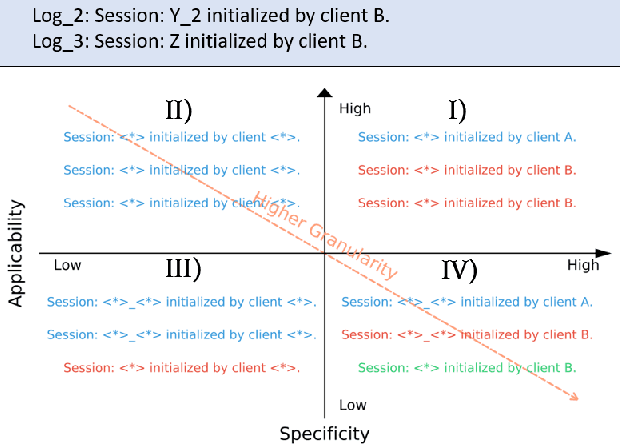

Logs are ubiquitous digital footprints, playing an indispensable role in system diagnostics, security analysis, and performance optimization. The extraction of actionable insights from logs is critically dependent on the log parsing process, which converts raw logs into structured formats for downstream analysis. Yet, the complexities of contemporary systems and the dynamic nature of logs pose significant challenges to existing automatic parsing techniques. The emergence of Large Language Models (LLM) offers new horizons. With their expansive knowledge and contextual prowess, LLMs have been transformative across diverse applications. Building on this, we introduce LogParser-LLM, a novel log parser integrated with LLM capabilities. This union seamlessly blends semantic insights with statistical nuances, obviating the need for hyper-parameter tuning and labeled training data, while ensuring rapid adaptability through online parsing. Further deepening our exploration, we address the intricate challenge of parsing granularity, proposing a new metric and integrating human interactions to allow users to calibrate granularity to their specific needs. Our method's efficacy is empirically demonstrated through evaluations on the Loghub-2k and the large-scale LogPub benchmark. In evaluations on the LogPub benchmark, involving an average of 3.6 million logs per dataset across 14 datasets, our LogParser-LLM requires only 272.5 LLM invocations on average, achieving a 90.6% F1 score for grouping accuracy and an 81.1% for parsing accuracy. These results demonstrate the method's high efficiency and accuracy, outperforming current state-of-the-art log parsers, including pattern-based, neural network-based, and existing LLM-enhanced approaches.
RCAgent: Cloud Root Cause Analysis by Autonomous Agents with Tool-Augmented Large Language Models
Oct 25, 2023



Large language model (LLM) applications in cloud root cause analysis (RCA) have been actively explored recently. However, current methods are still reliant on manual workflow settings and do not unleash LLMs' decision-making and environment interaction capabilities. We present RCAgent, a tool-augmented LLM autonomous agent framework for practical and privacy-aware industrial RCA usage. Running on an internally deployed model rather than GPT families, RCAgent is capable of free-form data collection and comprehensive analysis with tools. Our framework combines a variety of enhancements, including a unique Self-Consistency for action trajectories, and a suite of methods for context management, stabilization, and importing domain knowledge. Our experiments show RCAgent's evident and consistent superiority over ReAct across all aspects of RCA -- predicting root causes, solutions, evidence, and responsibilities -- and tasks covered or uncovered by current rules, as validated by both automated metrics and human evaluations. Furthermore, RCAgent has already been integrated into the diagnosis and issue discovery workflow of the Real-time Compute Platform for Apache Flink of Alibaba Cloud.
MediViSTA-SAM: Zero-shot Medical Video Analysis with Spatio-temporal SAM Adaptation
Sep 24, 2023In recent years, the Segmentation Anything Model (SAM) has attracted considerable attention as a foundational model well-known for its robust generalization capabilities across various downstream tasks. However, SAM does not exhibit satisfactory performance in the realm of medical image analysis. In this study, we introduce the first study on adapting SAM on video segmentation, called MediViSTA-SAM, a novel approach designed for medical video segmentation. Given video data, MediViSTA, spatio-temporal adapter captures long and short range temporal attention with cross-frame attention mechanism effectively constraining it to consider the immediately preceding video frame as a reference, while also considering spatial information effectively. Additionally, it incorporates multi-scale fusion by employing a U-shaped encoder and a modified mask decoder to handle objects of varying sizes. To evaluate our approach, extensive experiments were conducted using state-of-the-art (SOTA) methods, assessing its generalization abilities on multi-vendor in-house echocardiography datasets. The results highlight the accuracy and effectiveness of our network in medical video segmentation.
MA-SAM: Modality-agnostic SAM Adaptation for 3D Medical Image Segmentation
Sep 16, 2023



The Segment Anything Model (SAM), a foundation model for general image segmentation, has demonstrated impressive zero-shot performance across numerous natural image segmentation tasks. However, SAM's performance significantly declines when applied to medical images, primarily due to the substantial disparity between natural and medical image domains. To effectively adapt SAM to medical images, it is important to incorporate critical third-dimensional information, i.e., volumetric or temporal knowledge, during fine-tuning. Simultaneously, we aim to harness SAM's pre-trained weights within its original 2D backbone to the fullest extent. In this paper, we introduce a modality-agnostic SAM adaptation framework, named as MA-SAM, that is applicable to various volumetric and video medical data. Our method roots in the parameter-efficient fine-tuning strategy to update only a small portion of weight increments while preserving the majority of SAM's pre-trained weights. By injecting a series of 3D adapters into the transformer blocks of the image encoder, our method enables the pre-trained 2D backbone to extract third-dimensional information from input data. The effectiveness of our method has been comprehensively evaluated on four medical image segmentation tasks, by using 10 public datasets across CT, MRI, and surgical video data. Remarkably, without using any prompt, our method consistently outperforms various state-of-the-art 3D approaches, surpassing nnU-Net by 0.9%, 2.6%, and 9.9% in Dice for CT multi-organ segmentation, MRI prostate segmentation, and surgical scene segmentation respectively. Our model also demonstrates strong generalization, and excels in challenging tumor segmentation when prompts are used. Our code is available at: https://github.com/cchen-cc/MA-SAM.
Radiology-Llama2: Best-in-Class Large Language Model for Radiology
Aug 29, 2023



This paper introduces Radiology-Llama2, a large language model specialized for radiology through a process known as instruction tuning. Radiology-Llama2 is based on the Llama2 architecture and further trained on a large dataset of radiology reports to generate coherent and clinically useful impressions from radiological findings. Quantitative evaluations using ROUGE metrics on the MIMIC-CXR and OpenI datasets demonstrate that Radiology-Llama2 achieves state-of-the-art performance compared to other generative language models, with a Rouge-1 score of 0.4834 on MIMIC-CXR and 0.4185 on OpenI. Additional assessments by radiology experts highlight the model's strengths in understandability, coherence, relevance, conciseness, and clinical utility. The work illustrates the potential of localized language models designed and tuned for specialized domains like radiology. When properly evaluated and deployed, such models can transform fields like radiology by automating rote tasks and enhancing human expertise.
Radiology-GPT: A Large Language Model for Radiology
Jun 14, 2023



We introduce Radiology-GPT, a large language model for radiology. Using an instruction tuning approach on an extensive dataset of radiology domain knowledge, Radiology-GPT demonstrates superior performance compared to general language models such as StableLM, Dolly and LLaMA. It exhibits significant versatility in radiological diagnosis, research, and communication. This work serves as a catalyst for future developments in clinical NLP. The successful implementation of Radiology-GPT is indicative of the potential of localizing generative large language models, specifically tailored for distinctive medical specialties, while ensuring adherence to privacy standards such as HIPAA. The prospect of developing individualized, large-scale language models that cater to specific needs of various hospitals presents a promising direction. The fusion of conversational competence and domain-specific knowledge in these models is set to foster future development in healthcare AI. A demo of Radiology-GPT is available at https://huggingface.co/spaces/allen-eric/radiology-gpt.