 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataMagic: Transforming Tabular Data into Data Insight Video
Jun 18, 2026Data videos integrate dynamic charts, voice narration, and synchronized animations to communicate data insights as temporal narratives, making them an effective medium for improving data consumption efficiency in the data management lifecycle. However, producing high-quality data videos requires expertise spanning data analysis, narrative design, and video production. Existing approaches fall short: static visualization tools (e.g., BI dashboards) lack narrative logic and animation; authoring tools require users to pre-prepare visualizations rather than working from raw data; pixel-level video generation models cannot guarantee data fidelity or provenance. We demonstrate DataMagic, an end-to-end interactive system that transforms raw tabular data and natural language queries into narrative data-insight videos. To ensure data fidelity, DataMagic introduces the declarative specification DVSpec, which binds visual and animation elements to underlying data fields through data-driven semantic references. To address the combinatorial explosion of the design space, DataMagic adopts a Generate-then-Orchestrate multi-agent architecture that generates candidate scenes in parallel and then optimizes narrative coherence through global orchestration. Leveraging DVSpec's decoupling of logic and rendering, the system further supports three interaction modes and structured provenance-based data Q&A, transforming one-way videos into explorable interactive data interfaces. Evaluation on 109 real-world samples validates the effectiveness of the DataMagic. Homepage: https://datamagic-home.github.io/
3DReflecNet: A Large-Scale Dataset for 3D Reconstruction of Reflective, Transparent, and Low-Texture Objects
May 11, 2026Accurate 3D reconstruction of objects with reflective, transparent, or low-texture surfaces still remains notoriously challenging. Such materials often violate key assumptions in multi-view reconstruction pipelines, such as photometric consistency and the availability on distinct geometric texture cues. Existing datasets primarily focus on diffuse, textured objects, and therefore provide limited insight into performance under real-world material complexities. We introduce 3DReflecNet, a large-scale hybrid dataset exceeding 22 TB that is specifically designed to benchmark and advance 3D vision methods for these challenging materials. 3DReflecNet combines two types of data: over 120,000 synthetic instances generated via physically-based rendering of more than 12,000 shapes, and over 1,000 real-world objects captured using consumer devices. Together, these data consist of more than 7 million multi-view frames. The dataset spans diverse materials, complex lighting conditions, and a wide range of geometric forms, including shapes generated from both real and LLM-synthesized 2D images using diffusion-based pipelines. To support robust evaluation, we design benchmarks for five core tasks: image matching, structure-from-motion, novel view synthesis, reflection removal, and relighting. Extensive experiments demonstrate that state-of-the-art methods struggle to maintain accuracy across these settings, highlighting the need for more resilient 3D vision models.
ROSE: An Intent-Centered Evaluation Metric for NL2SQL
Apr 14, 2026Execution Accuracy (EX), the widely used metric for evaluating the effectiveness of Natural Language to SQL (NL2SQL) solutions, is becoming increasingly unreliable. It is sensitive to syntactic variation, ignores that questions may admit multiple interpretations, and is easily misled by erroneous ground-truth SQL. To address this, we introduce ROSE, an intent-centered metric that focuses on whether the predicted SQL answers the question, rather than consistency with the ground-truth SQL under the reference-dependent paradigm. ROSE employs an adversarial Prover-Refuter cascade: SQL Prover assesses the semantic correctness of a predicted SQL against the user's intent independently, while Adversarial Refuter uses the ground-truth SQL as evidence to challenge and refine this judgment. On our expert-aligned validation set ROSE-VEC, ROSE achieves the best agreement with human experts, outperforming the next-best metric by nearly 24% in Cohen's Kappa. We also conduct a largescale re-evaluation of 19 NL2SQL methods, revealing four valuable insights. We release ROSE and ROSE-VEC to facilitate more reliable NL2SQL research.
TouchGuide: Inference-Time Steering of Visuomotor Policies via Touch Guidance
Jan 28, 2026Fine-grained and contact-rich manipulation remain challenging for robots, largely due to the underutilization of tactile feedback. To address this, we introduce TouchGuide, a novel cross-policy visuo-tactile fusion paradigm that fuses modalities within a low-dimensional action space. Specifically, TouchGuide operates in two stages to guide a pre-trained diffusion or flow-matching visuomotor policy at inference time. First, the policy produces a coarse, visually-plausible action using only visual inputs during early sampling. Second, a task-specific Contact Physical Model (CPM) provides tactile guidance to steer and refine the action, ensuring it aligns with realistic physical contact conditions. Trained through contrastive learning on limited expert demonstrations, the CPM provides a tactile-informed feasibility score to steer the sampling process toward refined actions that satisfy physical contact constraints. Furthermore, to facilitate TouchGuide training with high-quality and cost-effective data, we introduce TacUMI, a data collection system. TacUMI achieves a favorable trade-off between precision and affordability; by leveraging rigid fingertips, it obtains direct tactile feedback, thereby enabling the collection of reliable tactile data. Extensive experiments on five challenging contact-rich tasks, such as shoe lacing and chip handover, show that TouchGuide consistently and significantly outperforms state-of-the-art visuo-tactile policies.
Beyond Single-shot Writing: Deep Research Agents are Unreliable at Multi-turn Report Revision
Jan 19, 2026Existing benchmarks for Deep Research Agents (DRAs) treat report generation as a single-shot writing task, which fundamentally diverges from how human researchers iteratively draft and revise reports via self-reflection or peer feedback. Whether DRAs can reliably revise reports with user feedback remains unexplored. We introduce Mr Dre, an evaluation suite that establishes multi-turn report revision as a new evaluation axis for DRAs. Mr Dre consists of (1) a unified long-form report evaluation protocol spanning comprehensiveness, factuality, and presentation, and (2) a human-verified feedback simulation pipeline for multi-turn revision. Our analysis of five diverse DRAs reveals a critical limitation: while agents can address most user feedback, they also regress on 16-27% of previously covered content and citation quality. Over multiple revision turns, even the best-performing agents leave significant headroom, as they continue to disrupt content outside the feedback's scope and fail to preserve earlier edits. We further show that these issues are not easily resolvable through inference-time fixes such as prompt engineering and a dedicated sub-agent for report revision.
Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems
Mar 31, 2025The advent of large language models (LLMs) has catalyzed a transformative shift in artificial intelligence, paving the way for advanced intelligent agents capable of sophisticated reasoning, robust perception, and versatile action across diverse domains. As these agents increasingly drive AI research and practical applications, their design, evaluation, and continuous improvement present intricate, multifaceted challenges. This survey provides a comprehensive overview, framing intelligent agents within a modular, brain-inspired architecture that integrates principles from cognitive science, neuroscience, and computational research. We structure our exploration into four interconnected parts. First, we delve into the modular foundation of intelligent agents, systematically mapping their cognitive, perceptual, and operational modules onto analogous human brain functionalities, and elucidating core components such as memory, world modeling, reward processing, and emotion-like systems. Second, we discuss self-enhancement and adaptive evolution mechanisms, exploring how agents autonomously refine their capabilities, adapt to dynamic environments, and achieve continual learning through automated optimization paradigms, including emerging AutoML and LLM-driven optimization strategies. Third, we examine collaborative and evolutionary multi-agent systems, investigating the collective intelligence emerging from agent interactions, cooperation, and societal structures, highlighting parallels to human social dynamics. Finally, we address the critical imperative of building safe, secure, and beneficial AI systems, emphasizing intrinsic and extrinsic security threats, ethical alignment, robustness, and practical mitigation strategies necessary for trustworthy real-world deployment.
ExScene: Free-View 3D Scene Reconstruction with Gaussian Splatting from a Single Image
Mar 31, 2025The increasing demand for augmented and virtual reality applications has highlighted the importance of crafting immersive 3D scenes from a simple single-view image. However, due to the partial priors provided by single-view input, existing methods are often limited to reconstruct low-consistency 3D scenes with narrow fields of view from single-view input. These limitations make them less capable of generalizing to reconstruct immersive scenes. To address this problem, we propose ExScene, a two-stage pipeline to reconstruct an immersive 3D scene from any given single-view image. ExScene designs a novel multimodal diffusion model to generate a high-fidelity and globally consistent panoramic image. We then develop a panoramic depth estimation approach to calculate geometric information from panorama, and we combine geometric information with high-fidelity panoramic image to train an initial 3D Gaussian Splatting (3DGS) model. Following this, we introduce a GS refinement technique with 2D stable video diffusion priors. We add camera trajectory consistency and color-geometric priors into the denoising process of diffusion to improve color and spatial consistency across image sequences. These refined sequences are then used to fine-tune the initial 3DGS model, leading to better reconstruction quality. Experimental results demonstrate that our ExScene achieves consistent and immersive scene reconstruction using only single-view input, significantly surpassing state-of-the-art baselines.
EllieSQL: Cost-Efficient Text-to-SQL with Complexity-Aware Routing
Mar 28, 2025



Text-to-SQL automatically translates natural language queries to SQL, allowing non-technical users to retrieve data from databases without specialized SQL knowledge. Despite the success of advanced LLM-based Text-to-SQL approaches on leaderboards, their unsustainable computational costs--often overlooked--stand as the "elephant in the room" in current leaderboard-driven research, limiting their economic practicability for real-world deployment and widespread adoption. To tackle this, we exploratively propose EllieSQL, a complexity-aware routing framework that assigns queries to suitable SQL generation pipelines based on estimated complexity. We investigate multiple routers to direct simple queries to efficient approaches while reserving computationally intensive methods for complex cases. Drawing from economics, we introduce the Token Elasticity of Performance (TEP) metric, capturing cost-efficiency by quantifying the responsiveness of performance gains relative to token investment in SQL generation. Experiments show that compared to always using the most advanced methods in our study, EllieSQL with the Qwen2.5-0.5B-DPO router reduces token use by over 40% without compromising performance on Bird development set, achieving more than a 2x boost in TEP over non-routing approaches. This not only advances the pursuit of cost-efficient Text-to-SQL but also invites the community to weigh resource efficiency alongside performance, contributing to progress in sustainable Text-to-SQL.
nvBench 2.0: A Benchmark for Natural Language to Visualization under Ambiguity
Mar 17, 2025Natural Language to Visualization (NL2VIS) enables users to create visualizations from natural language queries, making data insights more accessible. However, NL2VIS faces challenges in interpreting ambiguous queries, as users often express their visualization needs in imprecise language. To address this challenge, we introduce nvBench 2.0, a new benchmark designed to evaluate NL2VIS systems in scenarios involving ambiguous queries. nvBench 2.0 includes 7,878 natural language queries and 24,076 corresponding visualizations, derived from 780 tables across 153 domains. It is built using a controlled ambiguity-injection pipeline that generates ambiguous queries through a reverse-generation workflow. By starting with unambiguous seed visualizations and selectively injecting ambiguities, the pipeline yields multiple valid interpretations for each query, with each ambiguous query traceable to its corresponding visualization through step-wise reasoning paths. We evaluate various Large Language Models (LLMs) on their ability to perform ambiguous NL2VIS tasks using nvBench 2.0. We also propose Step-NL2VIS, an LLM-based model trained on nvBench 2.0, which enhances performance in ambiguous scenarios through step-wise preference optimization. Our results show that Step-NL2VIS outperforms all baselines, setting a new state-of-the-art for ambiguous NL2VIS tasks.
ErrorRadar: Benchmarking Complex Mathematical Reasoning of Multimodal Large Language Models Via Error Detection
Oct 06, 2024


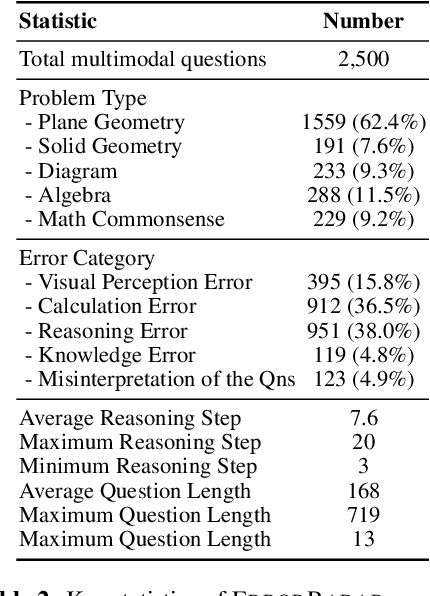
As the field of Multimodal Large Language Models (MLLMs) continues to evolve, their potential to revolutionize artificial intelligence is particularly promising, especially in addressing mathematical reasoning tasks. Current mathematical benchmarks predominantly focus on evaluating MLLMs' problem-solving ability, yet there is a crucial gap in addressing more complex scenarios such as error detection, for enhancing reasoning capability in complicated settings. To fill this gap, we formally formulate the new task: multimodal error detection, and introduce ErrorRadar, the first benchmark designed to assess MLLMs' capabilities in such a task. ErrorRadar evaluates two sub-tasks: error step identification and error categorization, providing a comprehensive framework for evaluating MLLMs' complex mathematical reasoning ability. It consists of 2,500 high-quality multimodal K-12 mathematical problems, collected from real-world student interactions in an educational organization, with rigorous annotation and rich metadata such as problem type and error category. Through extensive experiments, we evaluated both open-source and closed-source representative MLLMs, benchmarking their performance against educational expert evaluators. Results indicate significant challenges still remain, as GPT-4o with best performance is still around 10% behind human evaluation. The dataset will be available upon acceptance.