 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausalEmbed: Auto-Regressive Multi-Vector Generation in Latent Space for Visual Document Embedding
Jan 29, 2026Although Multimodal Large Language Models (MLLMs) have shown remarkable potential in Visual Document Retrieval (VDR) through generating high-quality multi-vector embeddings, the substantial storage overhead caused by representing a page with thousands of visual tokens limits their practicality in real-world applications. To address this challenge, we propose an auto-regressive generation approach, CausalEmbed, for constructing multi-vector embeddings. By incorporating iterative margin loss during contrastive training, CausalEmbed encourages the embedding models to learn compact and well-structured representations. Our method enables efficient VDR tasks using only dozens of visual tokens, achieving a 30-155x reduction in token count while maintaining highly competitive performance across various backbones and benchmarks. Theoretical analysis and empirical results demonstrate the unique advantages of auto-regressive embedding generation in terms of training efficiency and scalability at test time. As a result, CausalEmbed introduces a flexible test-time scaling strategy for multi-vector VDR representations and sheds light on the generative paradigm within multimodal document retrieval.
Memory in the Age of AI Agents
Dec 15, 2025Memory has emerged, and will continue to remain, a core capability of foundation model-based agents. As research on agent memory rapidly expands and attracts unprecedented attention, the field has also become increasingly fragmented. Existing works that fall under the umbrella of agent memory often differ substantially in their motivations, implementations, and evaluation protocols, while the proliferation of loosely defined memory terminologies has further obscured conceptual clarity. Traditional taxonomies such as long/short-term memory have proven insufficient to capture the diversity of contemporary agent memory systems. This work aims to provide an up-to-date landscape of current agent memory research. We begin by clearly delineating the scope of agent memory and distinguishing it from related concepts such as LLM memory, retrieval augmented generation (RAG), and context engineering. We then examine agent memory through the unified lenses of forms, functions, and dynamics. From the perspective of forms, we identify three dominant realizations of agent memory, namely token-level, parametric, and latent memory. From the perspective of functions, we propose a finer-grained taxonomy that distinguishes factual, experiential, and working memory. From the perspective of dynamics, we analyze how memory is formed, evolved, and retrieved over time. To support practical development, we compile a comprehensive summary of memory benchmarks and open-source frameworks. Beyond consolidation, we articulate a forward-looking perspective on emerging research frontiers, including memory automation, reinforcement learning integration, multimodal memory, multi-agent memory, and trustworthiness issues. We hope this survey serves not only as a reference for existing work, but also as a conceptual foundation for rethinking memory as a first-class primitive in the design of future agentic intelligence.
Improving Wildlife Out-of-Distribution Detection: Africas Big Five
Jun 07, 2025Mitigating human-wildlife conflict seeks to resolve unwanted encounters between these parties. Computer Vision provides a solution to identifying individuals that might escalate into conflict, such as members of the Big Five African animals. However, environments often contain several varied species. The current state-of-the-art animal classification models are trained under a closed-world assumption. They almost always remain overconfident in their predictions even when presented with unknown classes. This study investigates out-of-distribution (OOD) detection of wildlife, specifically the Big Five. To this end, we select a parametric Nearest Class Mean (NCM) and a non-parametric contrastive learning approach as baselines to take advantage of pretrained and projected features from popular classification encoders. Moreover, we compare our baselines to various common OOD methods in the literature. The results show feature-based methods reflect stronger generalisation capability across varying classification thresholds. Specifically, NCM with ImageNet pre-trained features achieves a 2%, 4% and 22% improvement on AUPR-IN, AUPR-OUT and AUTC over the best OOD methods, respectively. The code can be found here https://github.com/pxpana/BIG5OOD
MemOS: An Operating System for Memory-Augmented Generation (MAG) in Large Language Models
May 28, 2025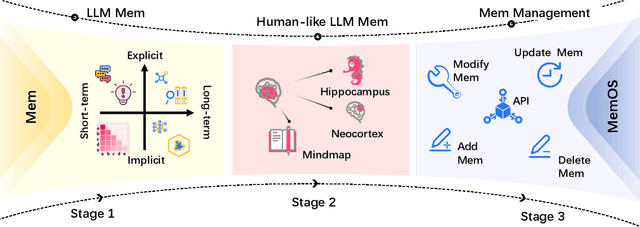
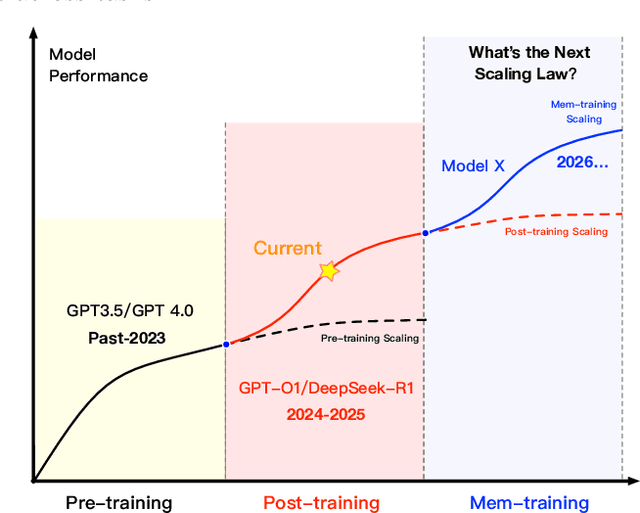
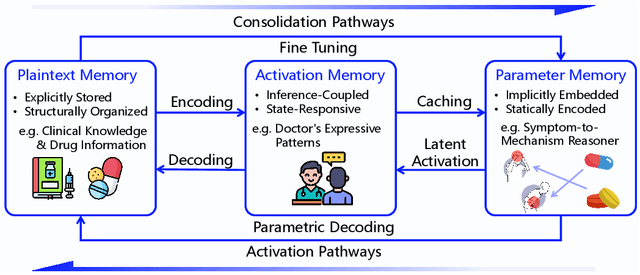
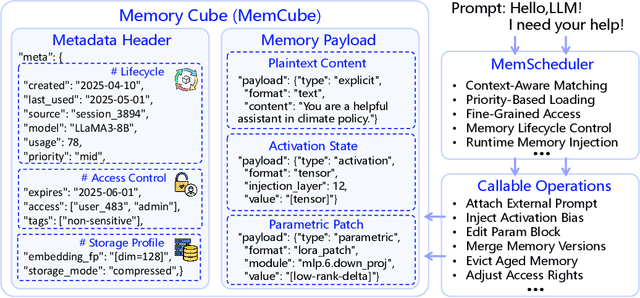
Large Language Models (LLMs) have emerged as foundational infrastructure in the pursuit of Artificial General Intelligence (AGI). Despite their remarkable capabilities in language perception and generation, current LLMs fundamentally lack a unified and structured architecture for handling memory. They primarily rely on parametric memory (knowledge encoded in model weights) and ephemeral activation memory (context-limited runtime states). While emerging methods like Retrieval-Augmented Generation (RAG) incorporate plaintext memory, they lack lifecycle management and multi-modal integration, limiting their capacity for long-term knowledge evolution. To address this, we introduce MemOS, a memory operating system designed for LLMs that, for the first time, elevates memory to a first-class operational resource. It builds unified mechanisms for representation, organization, and governance across three core memory types: parametric, activation, and plaintext. At its core is the MemCube, a standardized memory abstraction that enables tracking, fusion, and migration of heterogeneous memory, while offering structured, traceable access across tasks and contexts. MemOS establishes a memory-centric execution framework with strong controllability, adaptability, and evolvability. It fills a critical gap in current LLM infrastructure and lays the groundwork for continual adaptation, personalized intelligence, and cross-platform coordination in next-generation intelligent systems.
Pierce the Mists, Greet the Sky: Decipher Knowledge Overshadowing via Knowledge Circuit Analysis
May 21, 2025Large Language Models (LLMs), despite their remarkable capabilities, are hampered by hallucinations. A particularly challenging variant, knowledge overshadowing, occurs when one piece of activated knowledge inadvertently masks another relevant piece, leading to erroneous outputs even with high-quality training data. Current understanding of overshadowing is largely confined to inference-time observations, lacking deep insights into its origins and internal mechanisms during model training. Therefore, we introduce PhantomCircuit, a novel framework designed to comprehensively analyze and detect knowledge overshadowing. By innovatively employing knowledge circuit analysis, PhantomCircuit dissects the internal workings of attention heads, tracing how competing knowledge pathways contribute to the overshadowing phenomenon and its evolution throughout the training process. Extensive experiments demonstrate PhantomCircuit's effectiveness in identifying such instances, offering novel insights into this elusive hallucination and providing the research community with a new methodological lens for its potential mitigation.
EssayJudge: A Multi-Granular Benchmark for Assessing Automated Essay Scoring Capabilities of Multimodal Large Language Models
Feb 17, 2025Automated Essay Scoring (AES) plays a crucial role in educational assessment by providing scalable and consistent evaluations of writing tasks. However, traditional AES systems face three major challenges: (1) reliance on handcrafted features that limit generalizability, (2) difficulty in capturing fine-grained traits like coherence and argumentation, and (3) inability to handle multimodal contexts. In the era of Multimodal Large Language Models (MLLMs), we propose EssayJudge, the first multimodal benchmark to evaluate AES capabilities across lexical-, sentence-, and discourse-level traits. By leveraging MLLMs' strengths in trait-specific scoring and multimodal context understanding, EssayJudge aims to offer precise, context-rich evaluations without manual feature engineering, addressing longstanding AES limitations. Our experiments with 18 representative MLLMs reveal gaps in AES performance compared to human evaluation, particularly in discourse-level traits, highlighting the need for further advancements in MLLM-based AES research. Our dataset and code will be available upon acceptance.
Position: Multimodal Large Language Models Can Significantly Advance Scientific Reasoning
Feb 05, 2025



Scientific reasoning, the process through which humans apply logic, evidence, and critical thinking to explore and interpret scientific phenomena, is essential in advancing knowledge reasoning across diverse fields. However, despite significant progress, current scientific reasoning models still struggle with generalization across domains and often fall short of multimodal perception. Multimodal Large Language Models (MLLMs), which integrate text, images, and other modalities, present an exciting opportunity to overcome these limitations and enhance scientific reasoning. Therefore, this position paper argues that MLLMs can significantly advance scientific reasoning across disciplines such as mathematics, physics, chemistry, and biology. First, we propose a four-stage research roadmap of scientific reasoning capabilities, and highlight the current state of MLLM applications in scientific reasoning, noting their ability to integrate and reason over diverse data types. Second, we summarize the key challenges that remain obstacles to achieving MLLM's full potential. To address these challenges, we propose actionable insights and suggestions for the future. Overall, our work offers a novel perspective on MLLM integration with scientific reasoning, providing the LLM community with a valuable vision for achieving Artificial General Intelligence (AGI).
Explainable and Interpretable Multimodal Large Language Models: A Comprehensive Survey
Dec 03, 2024
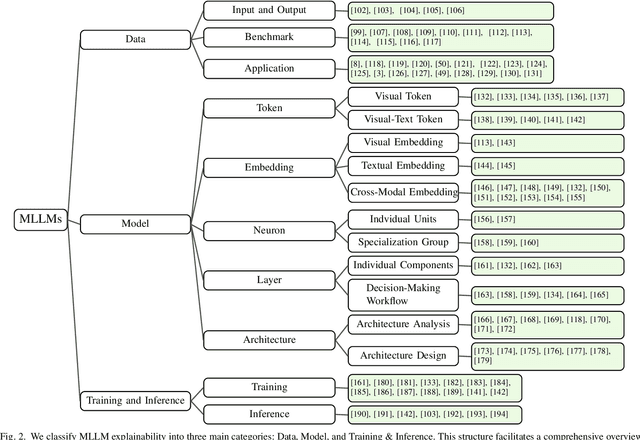
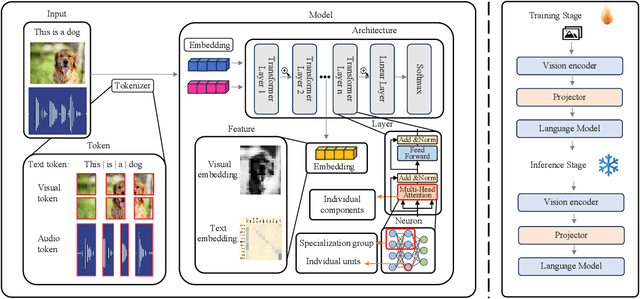
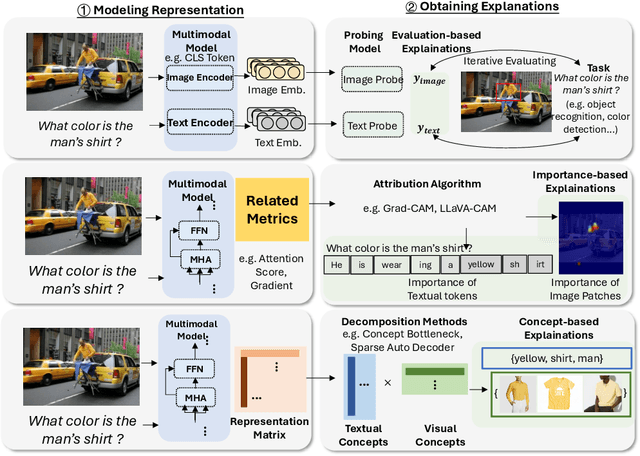
The rapid development of Artificial Intelligence (AI) has revolutionized numerous fields, with large language models (LLMs) and computer vision (CV) systems driving advancements in natural language understanding and visual processing, respectively. The convergence of these technologies has catalyzed the rise of multimodal AI, enabling richer, cross-modal understanding that spans text, vision, audio, and video modalities. Multimodal large language models (MLLMs), in particular, have emerged as a powerful framework, demonstrating impressive capabilities in tasks like image-text generation, visual question answering, and cross-modal retrieval. Despite these advancements, the complexity and scale of MLLMs introduce significant challenges in interpretability and explainability, essential for establishing transparency, trustworthiness, and reliability in high-stakes applications. This paper provides a comprehensive survey on the interpretability and explainability of MLLMs, proposing a novel framework that categorizes existing research across three perspectives: (I) Data, (II) Model, (III) Training \& Inference. We systematically analyze interpretability from token-level to embedding-level representations, assess approaches related to both architecture analysis and design, and explore training and inference strategies that enhance transparency. By comparing various methodologies, we identify their strengths and limitations and propose future research directions to address unresolved challenges in multimodal explainability. This survey offers a foundational resource for advancing interpretability and transparency in MLLMs, guiding researchers and practitioners toward developing more accountable and robust multimodal AI systems.
MINER: Mining the Underlying Pattern of Modality-Specific Neurons in Multimodal Large Language Models
Oct 07, 2024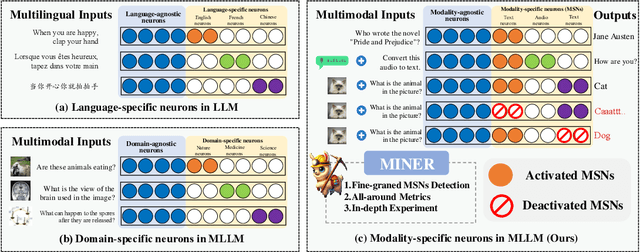
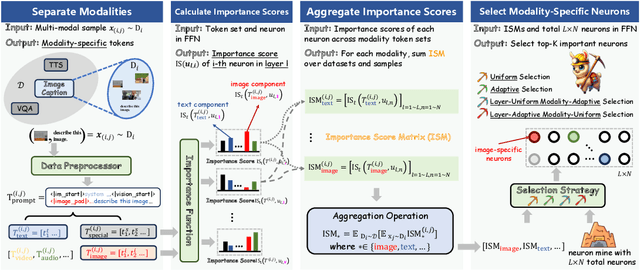
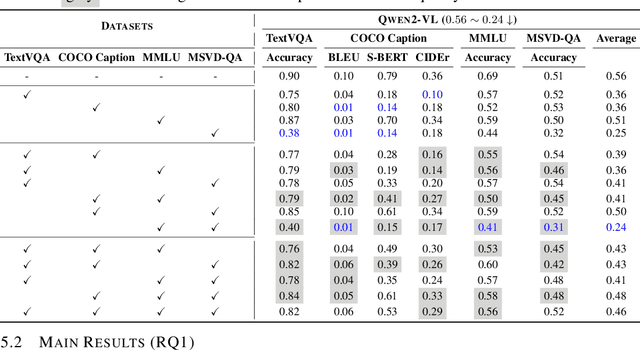

In recent years, multimodal large language models (MLLMs) have significantly advanced, integrating more modalities into diverse applications. However, the lack of explainability remains a major barrier to their use in scenarios requiring decision transparency. Current neuron-level explanation paradigms mainly focus on knowledge localization or language- and domain-specific analyses, leaving the exploration of multimodality largely unaddressed. To tackle these challenges, we propose MINER, a transferable framework for mining modality-specific neurons (MSNs) in MLLMs, which comprises four stages: (1) modality separation, (2) importance score calculation, (3) importance score aggregation, (4) modality-specific neuron selection. Extensive experiments across six benchmarks and two representative MLLMs show that (I) deactivating ONLY 2% of MSNs significantly reduces MLLMs performance (0.56 to 0.24 for Qwen2-VL, 0.69 to 0.31 for Qwen2-Audio), (II) different modalities mainly converge in the lower layers, (III) MSNs influence how key information from various modalities converges to the last token, (IV) two intriguing phenomena worth further investigation, i.e., semantic probing and semantic telomeres. The source code is available at this URL.
ErrorRadar: Benchmarking Complex Mathematical Reasoning of Multimodal Large Language Models Via Error Detection
Oct 06, 2024


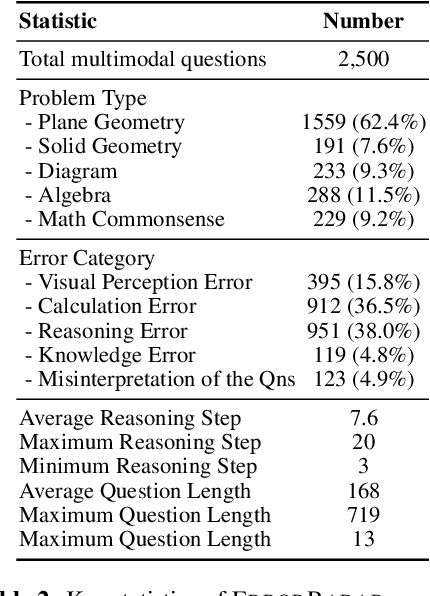
As the field of Multimodal Large Language Models (MLLMs) continues to evolve, their potential to revolutionize artificial intelligence is particularly promising, especially in addressing mathematical reasoning tasks. Current mathematical benchmarks predominantly focus on evaluating MLLMs' problem-solving ability, yet there is a crucial gap in addressing more complex scenarios such as error detection, for enhancing reasoning capability in complicated settings. To fill this gap, we formally formulate the new task: multimodal error detection, and introduce ErrorRadar, the first benchmark designed to assess MLLMs' capabilities in such a task. ErrorRadar evaluates two sub-tasks: error step identification and error categorization, providing a comprehensive framework for evaluating MLLMs' complex mathematical reasoning ability. It consists of 2,500 high-quality multimodal K-12 mathematical problems, collected from real-world student interactions in an educational organization, with rigorous annotation and rich metadata such as problem type and error category. Through extensive experiments, we evaluated both open-source and closed-source representative MLLMs, benchmarking their performance against educational expert evaluators. Results indicate significant challenges still remain, as GPT-4o with best performance is still around 10% behind human evaluation. The dataset will be available upon acceptance.