 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnique Faces Recognition in Videos
Paper and Code
Jun 10, 2020
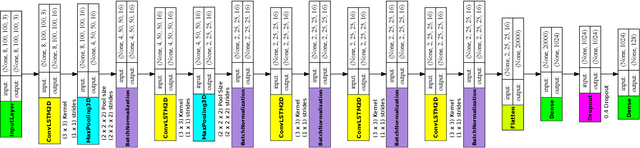

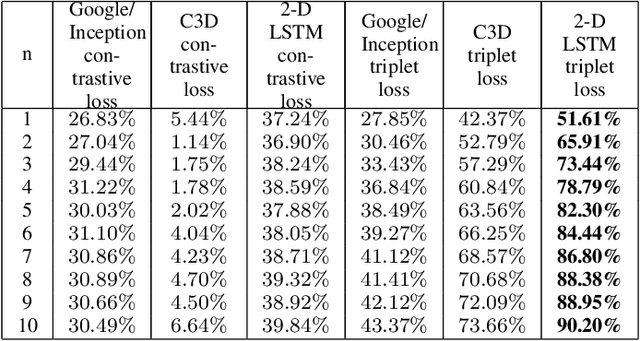
This paper tackles face recognition in videos employing metric learning methods and similarity ranking models. The paper compares the use of the Siamese network with contrastive loss and Triplet Network with triplet loss implementing the following architectures: Google/Inception architecture, 3D Convolutional Network (C3D), and a 2-D Long short-term memory (LSTM) Recurrent Neural Network. We make use of still images and sequences from videos for training the networks and compare the performances implementing the above architectures. The dataset used was the YouTube Face Database designed for investigating the problem of face recognition in videos. The contribution of this paper is two-fold: to begin, the experiments have established 3-D Convolutional networks and 2-D LSTMs with the contrastive loss on image sequences do not outperform Google/Inception architecture with contrastive loss in top $n$ rank face retrievals with still images. However, the 3-D Convolution networks and 2-D LSTM with triplet Loss outperform the Google/Inception with triplet loss in top $n$ rank face retrievals on the dataset; second, a Support Vector Machine (SVM) was used in conjunction with the CNNs' learned feature representations for facial identification. The results show that feature representation learned with triplet loss is significantly better for n-shot facial identification compared to contrastive loss. The most useful feature representations for facial identification are from the 2-D LSTM with triplet loss. The experiments show that learning spatio-temporal features from video sequences is beneficial for facial recognition in videos.