 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiCoRec: Bias-Mitigated Context-Aware Sequential Recommendation Model
Dec 15, 2025Sequential recommendation models aim to learn from users evolving preferences. However, current state-of-the-art models suffer from an inherent popularity bias. This study developed a novel framework, BiCoRec, that adaptively accommodates users changing preferences for popular and niche items. Our approach leverages a co-attention mechanism to obtain a popularity-weighted user sequence representation, facilitating more accurate predictions. We then present a new training scheme that learns from future preferences using a consistency loss function. BiCoRec aimed to improve the recommendation performance of users who preferred niche items. For these users, BiCoRec achieves a 26.00% average improvement in NDCG@10 over state-of-the-art baselines. When ranking the relevant item against the entire collection, BiCoRec achieves NDCG@10 scores of 0.0102, 0.0047, 0.0021, and 0.0005 for the Movies, Fashion, Games and Music datasets.
Statistics and Deep Learning-based Hybrid Model for Interpretable Anomaly Detection
Feb 25, 2022


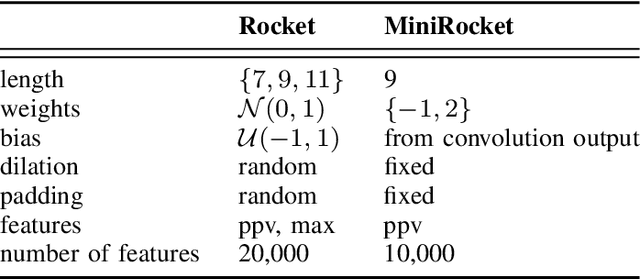
Hybrid methods have been shown to outperform pure statistical and pure deep learning methods at both forecasting tasks, and at quantifying the uncertainty associated with those forecasts (prediction intervals). One example is Multivariate Exponential Smoothing Long Short-Term Memory (MES-LSTM), a hybrid between a multivariate statistical forecasting model and a Recurrent Neural Network variant, Long Short-Term Memory. It has also been shown that a model that ($i$) produces accurate forecasts and ($ii$) is able to quantify the associated predictive uncertainty satisfactorily, can be successfully adapted to a model suitable for anomaly detection tasks. With the increasing ubiquity of multivariate data and new application domains, there have been numerous anomaly detection methods proposed in recent years. The proposed methods have largely focused on deep learning techniques, which are prone to suffer from challenges such as ($i$) large sets of parameters that may be computationally intensive to tune, $(ii)$ returning too many false positives rendering the techniques impractical for use, $(iii)$ requiring labeled datasets for training which are often not prevalent in real life, and ($iv$) understanding of the root causes of anomaly occurrences inhibited by the predominantly black-box nature of deep learning methods. In this article, an extension of MES-LSTM is presented, an interpretable anomaly detection model that overcomes these challenges. With a focus on renewable energy generation as an application domain, the proposed approach is benchmarked against the state-of-the-art. The findings are that MES-LSTM anomaly detector is at least competitive to the benchmarks at anomaly detection tasks, and less prone to learning from spurious effects than the benchmarks, thus making it more reliable at root cause discovery and explanation.
Surrogate Assisted Strategies (The Parameterisation of an Infectious Disease Agent-Based Model)
Aug 19, 2021
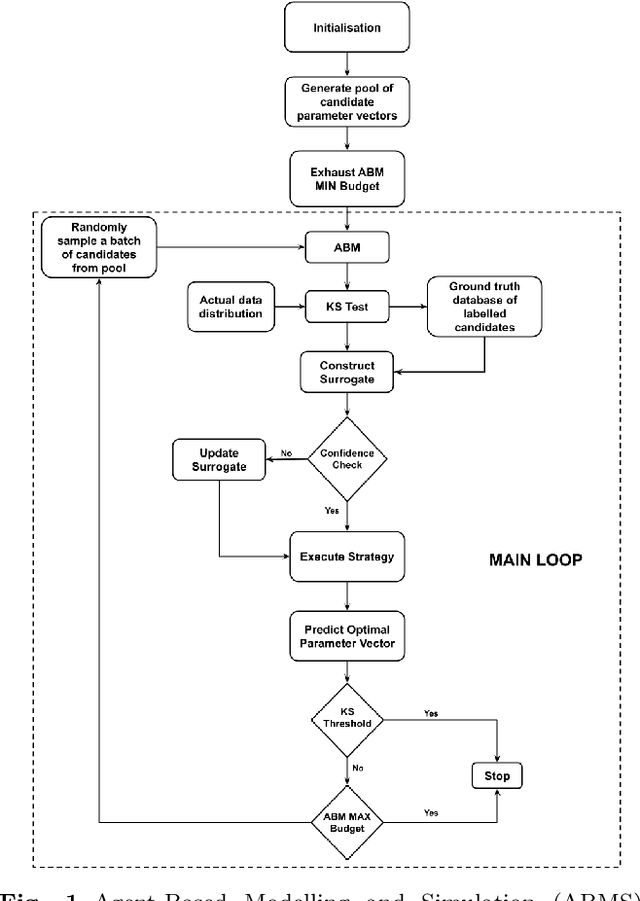


Parameter calibration is a significant challenge in agent-based modelling and simulation (ABMS). An agent-based model's (ABM) complexity grows as the number of parameters required to be calibrated increases. This parameter expansion leads to the ABMS equivalent of the \say{curse of dimensionality}. In particular, infeasible computational requirements searching an infinite parameter space. We propose a more comprehensive and adaptive ABMS Framework that can effectively swap out parameterisation strategies and surrogate models to parameterise an infectious disease ABM. This framework allows us to evaluate different strategy-surrogate combinations' performance in accuracy and efficiency (speedup). We show that we achieve better than parity in accuracy across the surrogate assisted sampling strategies and the baselines. Also, we identify that the Metric Stochastic Response Surface strategy combined with the Support Vector Machine surrogate is the best overall in getting closest to the true synthetic parameters. Also, we show that DYnamic COOrdindate Search Using Response Surface Models with XGBoost as a surrogate attains in combination the highest probability of approximating a cumulative synthetic daily infection data distribution and achieves the most significant speedup with regards to our analysis. Lastly, we show in a real-world setting that DYCORS XGBoost and MSRS SVM can approximate the real world cumulative daily infection distribution with $97.12$\% and $96.75$\% similarity respectively.
Surrogate Assisted Methods for the Parameterisation of Agent-Based Models
Aug 26, 2020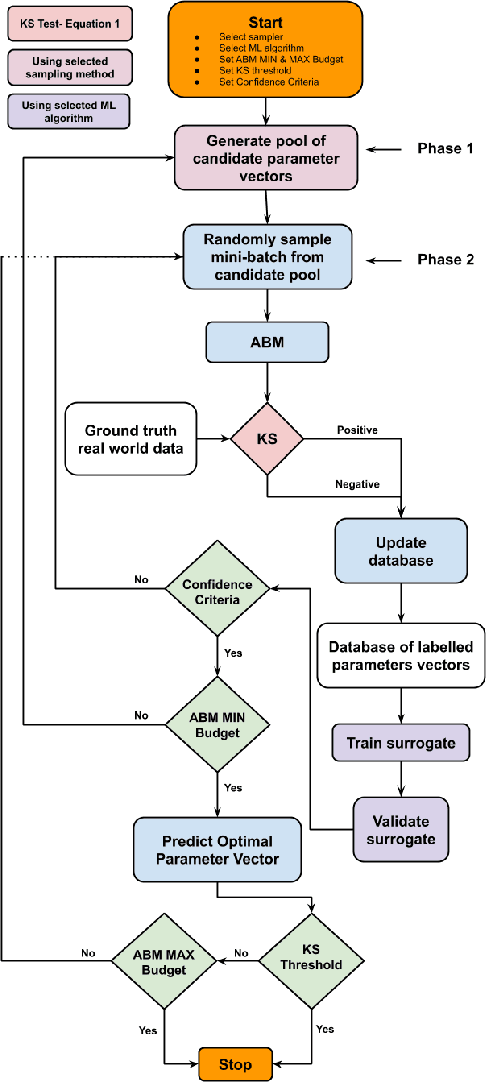



Parameter calibration is a major challenge in agent-based modelling and simulation (ABMS). As the complexity of agent-based models (ABMs) increase, the number of parameters required to be calibrated grows. This leads to the ABMS equivalent of the \say{curse of dimensionality}. We propose an ABMS framework which facilitates the effective integration of different sampling methods and surrogate models (SMs) in order to evaluate how these strategies affect parameter calibration and exploration. We show that surrogate assisted methods perform better than the standard sampling methods. In addition, we show that the XGBoost and Decision Tree SMs are most optimal overall with regards to our analysis.
Unique Faces Recognition in Videos
Jun 10, 2020
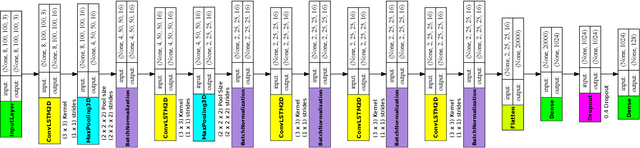

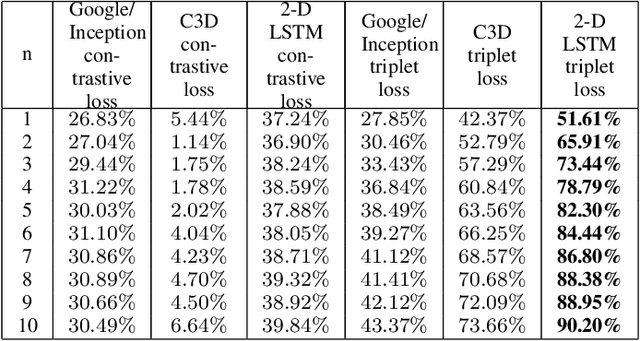
This paper tackles face recognition in videos employing metric learning methods and similarity ranking models. The paper compares the use of the Siamese network with contrastive loss and Triplet Network with triplet loss implementing the following architectures: Google/Inception architecture, 3D Convolutional Network (C3D), and a 2-D Long short-term memory (LSTM) Recurrent Neural Network. We make use of still images and sequences from videos for training the networks and compare the performances implementing the above architectures. The dataset used was the YouTube Face Database designed for investigating the problem of face recognition in videos. The contribution of this paper is two-fold: to begin, the experiments have established 3-D Convolutional networks and 2-D LSTMs with the contrastive loss on image sequences do not outperform Google/Inception architecture with contrastive loss in top $n$ rank face retrievals with still images. However, the 3-D Convolution networks and 2-D LSTM with triplet Loss outperform the Google/Inception with triplet loss in top $n$ rank face retrievals on the dataset; second, a Support Vector Machine (SVM) was used in conjunction with the CNNs' learned feature representations for facial identification. The results show that feature representation learned with triplet loss is significantly better for n-shot facial identification compared to contrastive loss. The most useful feature representations for facial identification are from the 2-D LSTM with triplet loss. The experiments show that learning spatio-temporal features from video sequences is beneficial for facial recognition in videos.
Comparison of Recurrent Neural Network Architectures for Wildfire Spread Modelling
May 26, 2020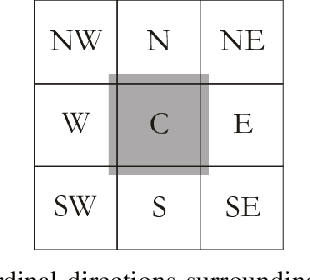
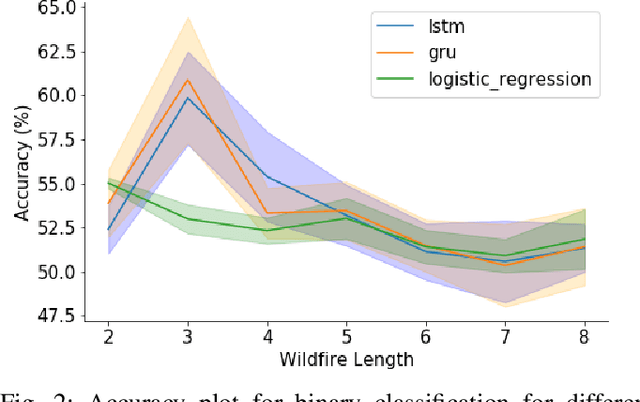
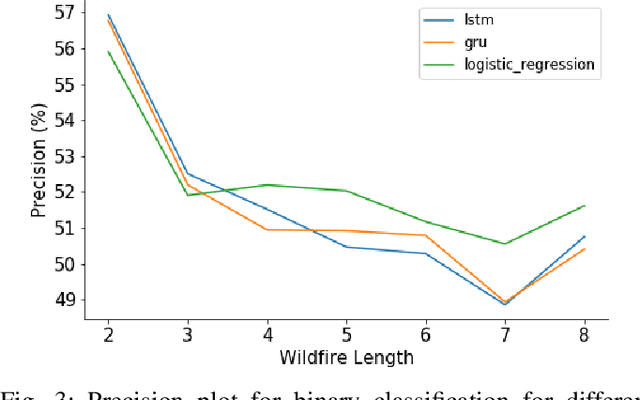
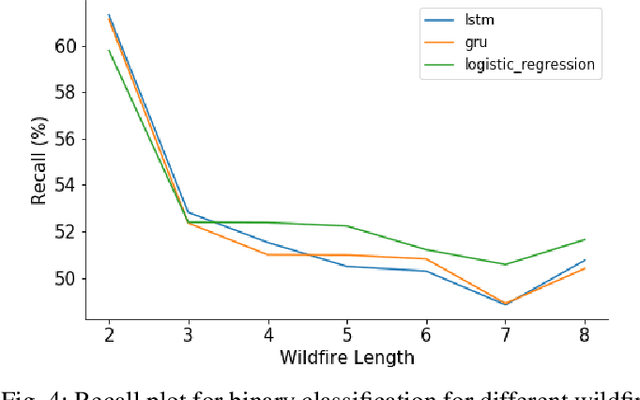
Wildfire modelling is an attempt to reproduce fire behaviour. Through active fire analysis, it is possible to reproduce a dynamical process, such as wildfires, with limited duration time series data. Recurrent neural networks (RNNs) can model dynamic temporal behaviour due to their ability to remember their internal input. In this paper, we compare the Gated Recurrent Unit (GRU) and the Long Short-Term Memory (LSTM) network. We try to determine whether a wildfire continues to burn and given that it does, we aim to predict which one of the 8 cardinal directions the wildfire will spread in. Overall the GRU performs better for longer time series than the LSTM. We have shown that although we are reasonable at predicting the direction in which the wildfire will spread, we are not able to asses if the wildfire continues to burn due to the lack of auxiliary data.