 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplexity of Linear Regions in Self-supervised Deep ReLU Networks
Apr 27, 2026There has been growing interest in studying the complexity of Rectified Linear Unit (ReLU) based activation networks. Recent work investigates the evolution of the number of piecewise-linear partitions (linear regions) that are formed during training. However, current research is limited to examining the complexity of models trained in a supervised way. Self-Supervised Learning (SSL) differs in that it directly optimises the representation space using a loss function to enhance the model's performance across multiple downstream tasks. This study investigates the local distribution of linear regions produced by SSL models. We demonstrate that the evolution of linear regions correlates with the representation quality by utilising SplineCam to extract two-dimensional polytopes near the data distribution. We track the number, area, eccentricity, and boundaries of regions throughout training. The study compares supervised, contrastive, and self-distillation methods over two standard benchmark datasets, MNIST and FashionMNIST. The analysis of the experimental results shows that self-supervised methods create substantially fewer regions to achieve comparable accuracy to supervised models. Contrastive methods rapidly expand regions over time, whereas self-distillation methods tend to consolidate by merging neighbouring regions. Lastly, we can detect representation collapse early within the geometric space of linear regions. Our analysis suggests that polytopal metrics can serve as reliable indicators of representation quality and model performance.
Wildlife Target Re-Identification Using Self-supervised Learning in Non-Urban Settings
Jul 03, 2025Wildlife re-identification aims to match individuals of the same species across different observations. Current state-of-the-art (SOTA) models rely on class labels to train supervised models for individual classification. This dependence on annotated data has driven the curation of numerous large-scale wildlife datasets. This study investigates self-supervised learning Self-Supervised Learning (SSL) for wildlife re-identification. We automatically extract two distinct views of an individual using temporal image pairs from camera trap data without supervision. The image pairs train a self-supervised model from a potentially endless stream of video data. We evaluate the learnt representations against supervised features on open-world scenarios and transfer learning in various wildlife downstream tasks. The analysis of the experimental results shows that self-supervised models are more robust even with limited data. Moreover, self-supervised features outperform supervision across all downstream tasks. The code is available here https://github.com/pxpana/SSLWildlife.
Improving Wildlife Out-of-Distribution Detection: Africas Big Five
Jun 07, 2025Mitigating human-wildlife conflict seeks to resolve unwanted encounters between these parties. Computer Vision provides a solution to identifying individuals that might escalate into conflict, such as members of the Big Five African animals. However, environments often contain several varied species. The current state-of-the-art animal classification models are trained under a closed-world assumption. They almost always remain overconfident in their predictions even when presented with unknown classes. This study investigates out-of-distribution (OOD) detection of wildlife, specifically the Big Five. To this end, we select a parametric Nearest Class Mean (NCM) and a non-parametric contrastive learning approach as baselines to take advantage of pretrained and projected features from popular classification encoders. Moreover, we compare our baselines to various common OOD methods in the literature. The results show feature-based methods reflect stronger generalisation capability across varying classification thresholds. Specifically, NCM with ImageNet pre-trained features achieves a 2%, 4% and 22% improvement on AUPR-IN, AUPR-OUT and AUTC over the best OOD methods, respectively. The code can be found here https://github.com/pxpana/BIG5OOD
A Learnheuristic Approach to A Constrained Multi-Objective Portfolio Optimisation Problem
Apr 13, 2023



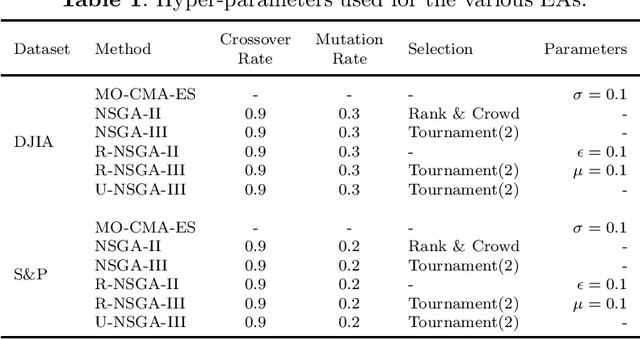
Multi-objective portfolio optimisation is a critical problem researched across various fields of study as it achieves the objective of maximising the expected return while minimising the risk of a given portfolio at the same time. However, many studies fail to include realistic constraints in the model, which limits practical trading strategies. This study introduces realistic constraints, such as transaction and holding costs, into an optimisation model. Due to the non-convex nature of this problem, metaheuristic algorithms, such as NSGA-II, R-NSGA-II, NSGA-III and U-NSGA-III, will play a vital role in solving the problem. Furthermore, a learnheuristic approach is taken as surrogate models enhance the metaheuristics employed. These algorithms are then compared to the baseline metaheuristic algorithms, which solve a constrained, multi-objective optimisation problem without using learnheuristics. The results of this study show that, despite taking significantly longer to run to completion, the learnheuristic algorithms outperform the baseline algorithms in terms of hypervolume and rate of convergence. Furthermore, the backtesting results indicate that utilising learnheuristics to generate weights for asset allocation leads to a lower risk percentage, higher expected return and higher Sharpe ratio than backtesting without using learnheuristics. This leads us to conclude that using learnheuristics to solve a constrained, multi-objective portfolio optimisation problem produces superior and preferable results than solving the problem without using learnheuristics.
Late Meta-learning Fusion Using Representation Learning for Time Series Forecasting
Mar 20, 2023Meta-learning, decision fusion, hybrid models, and representation learning are topics of investigation with significant traction in time-series forecasting research. Of these two specific areas have shown state-of-the-art results in forecasting: hybrid meta-learning models such as Exponential Smoothing - Recurrent Neural Network (ES-RNN) and Neural Basis Expansion Analysis (N-BEATS) and feature-based stacking ensembles such as Feature-based FORecast Model Averaging (FFORMA). However, a unified taxonomy for model fusion and an empirical comparison of these hybrid and feature-based stacking ensemble approaches is still missing. This study presents a unified taxonomy encompassing these topic areas. Furthermore, the study empirically evaluates several model fusion approaches and a novel combination of hybrid and feature stacking algorithms called Deep-learning FORecast Model Averaging (DeFORMA). The taxonomy contextualises the considered methods. Furthermore, the empirical analysis of the results shows that the proposed model, DeFORMA, can achieve state-of-the-art results in the M4 data set. DeFORMA, increases the mean Overall Weighted Average (OWA) in the daily, weekly and yearly subsets with competitive results in the hourly, monthly and quarterly subsets. The taxonomy and empirical results lead us to argue that significant progress is still to be made by continuing to explore the intersection of these research areas.
Towards a methodology for addressing missingness in datasets, with an application to demographic health datasets
Nov 05, 2022



Missing data is a common concern in health datasets, and its impact on good decision-making processes is well documented. Our study's contribution is a methodology for tackling missing data problems using a combination of synthetic dataset generation, missing data imputation and deep learning methods to resolve missing data challenges. Specifically, we conducted a series of experiments with these objectives; $a)$ generating a realistic synthetic dataset, $b)$ simulating data missingness, $c)$ recovering the missing data, and $d)$ analyzing imputation performance. Our methodology used a gaussian mixture model whose parameters were learned from a cleaned subset of a real demographic and health dataset to generate the synthetic data. We simulated various missingness degrees ranging from $10 \%$, $20 \%$, $30 \%$, and $40\%$ under the missing completely at random scheme MCAR. We used an integrated performance analysis framework involving clustering, classification and direct imputation analysis. Our results show that models trained on synthetic and imputed datasets could make predictions with an accuracy of $83 \%$ and $80 \%$ on $a) $ an unseen real dataset and $b)$ an unseen reserved synthetic test dataset, respectively. Moreover, the models that used the DAE method for imputed yielded the lowest log loss an indication of good performance, even though the accuracy measures were slightly lower. In conclusion, our work demonstrates that using our methodology, one can reverse engineer a solution to resolve missingness on an unseen dataset with missingness. Moreover, though we used a health dataset, our methodology can be utilized in other contexts.
Multi-Modal Recommendation System with Auxiliary Information
Oct 13, 2022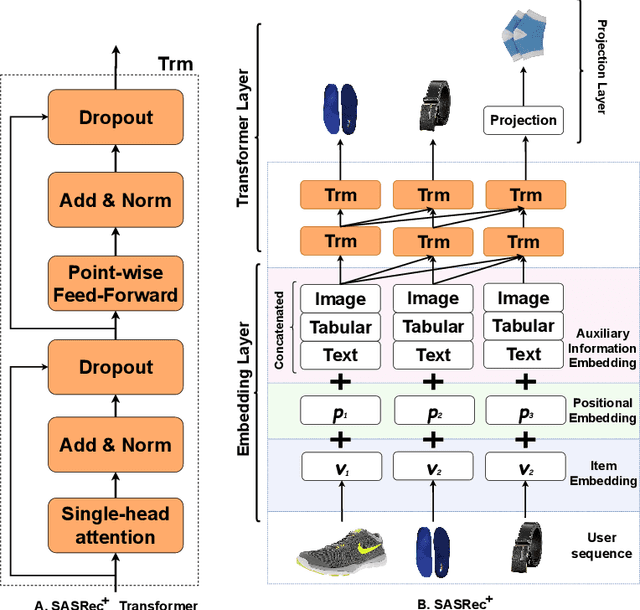
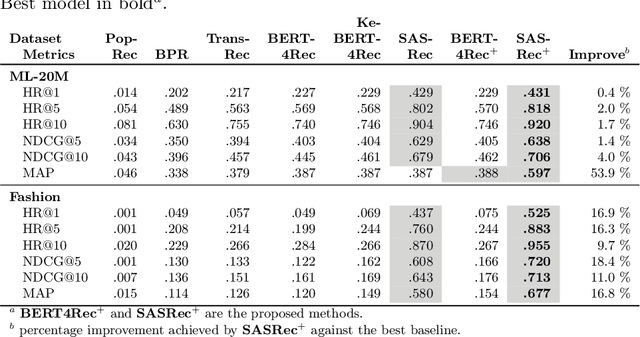
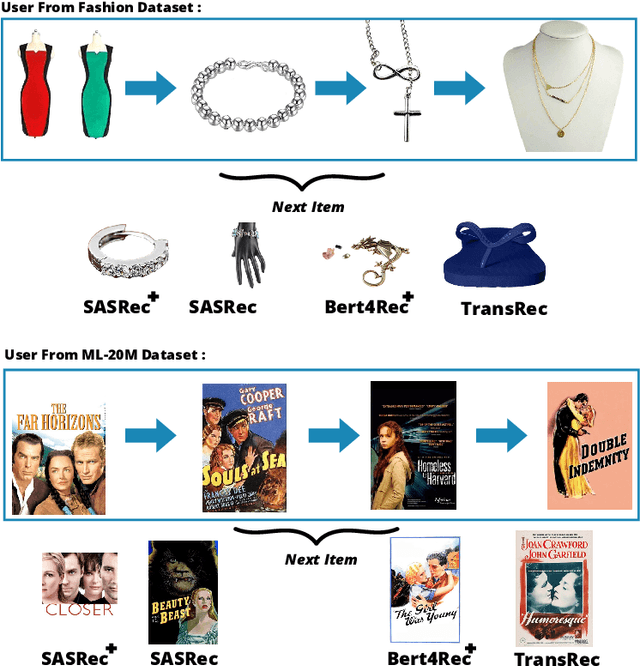

Context-aware recommendation systems improve upon classical recommender systems by including, in the modelling, a user's behaviour. Research into context-aware recommendation systems has previously only considered the sequential ordering of items as contextual information. However, there is a wealth of unexploited additional multi-modal information available in auxiliary knowledge related to items. This study extends the existing research by evaluating a multi-modal recommendation system that exploits the inclusion of comprehensive auxiliary knowledge related to an item. The empirical results explore extracting vector representations (embeddings) from unstructured and structured data using data2vec. The fused embeddings are then used to train several state-of-the-art transformer architectures for sequential user-item representations. The analysis of the experimental results shows a statistically significant improvement in prediction accuracy, which confirms the effectiveness of including auxiliary information in a context-aware recommendation system. We report a 4% and 11% increase in the NDCG score for long and short user sequence datasets, respectively.
Pareto Driven Surrogate (ParDen-Sur) Assisted Optimisation of Multi-period Portfolio Backtest Simulations
Sep 13, 2022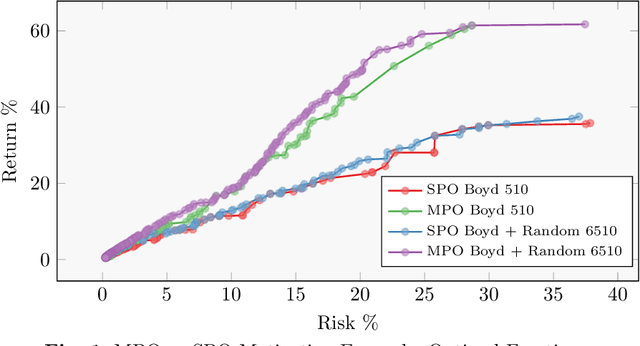
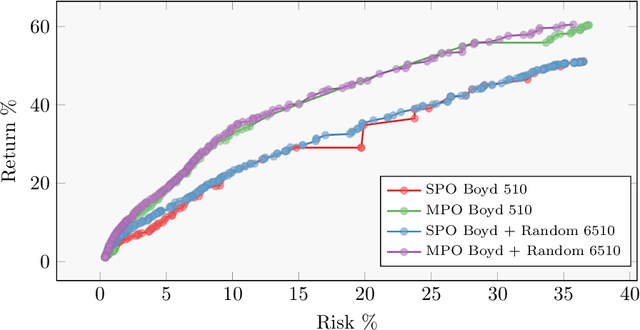
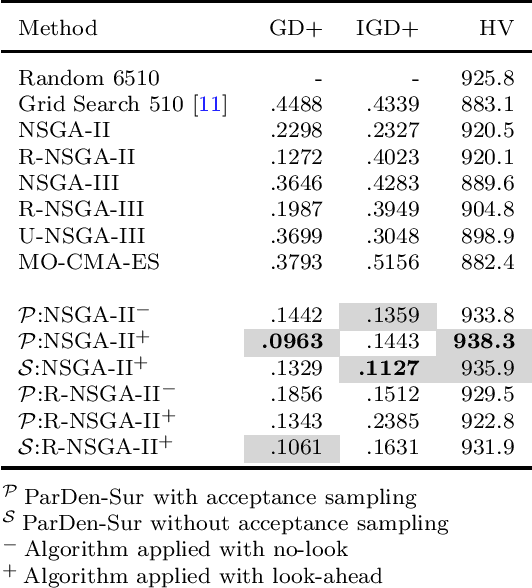
Portfolio management is a multi-period multi-objective optimisation problem subject to a wide range of constraints. However, in practice, portfolio management is treated as a single-period problem partly due to the computationally burdensome hyper-parameter search procedure needed to construct a multi-period Pareto frontier. This study presents the \gls{ParDen-Sur} modelling framework to efficiently perform the required hyper-parameter search. \gls{ParDen-Sur} extends previous surrogate frameworks by including a reservoir sampling-based look-ahead mechanism for offspring generation in \glspl{EA} alongside the traditional acceptance sampling scheme. We evaluate this framework against, and in conjunction with, several seminal \gls{MO} \glspl{EA} on two datasets for both the single- and multi-period use cases. Our results show that \gls{ParDen-Sur} can speed up the exploration for optimal hyper-parameters by almost $2\times$ with a statistically significant improvement of the Pareto frontiers, across multiple \glspl{EA}, for both datasets and use cases.
Knowledge Graph Fusion for Language Model Fine-tuning
Jun 21, 2022
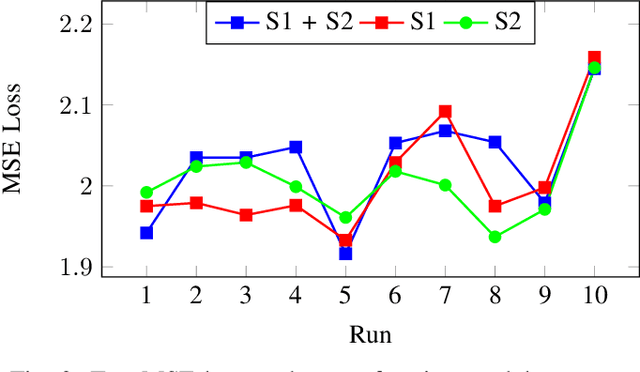
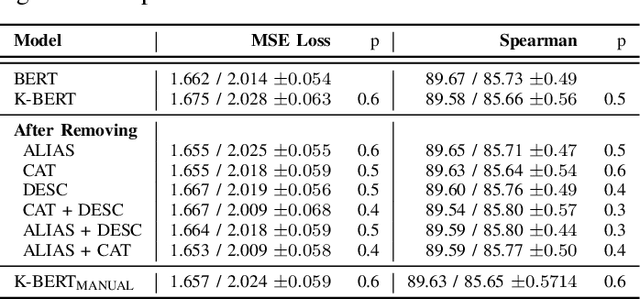
Language Models such as BERT have grown in popularity due to their ability to be pre-trained and perform robustly on a wide range of Natural Language Processing tasks. Often seen as an evolution over traditional word embedding techniques, they can produce semantic representations of text, useful for tasks such as semantic similarity. However, state-of-the-art models often have high computational requirements and lack global context or domain knowledge which is required for complete language understanding. To address these limitations, we investigate the benefits of knowledge incorporation into the fine-tuning stages of BERT. An existing K-BERT model, which enriches sentences with triplets from a Knowledge Graph, is adapted for the English language and extended to inject contextually relevant information into sentences. As a side-effect, changes made to K-BERT for accommodating the English language also extend to other word-based languages. Experiments conducted indicate that injected knowledge introduces noise. We see statistically significant improvements for knowledge-driven tasks when this noise is minimised. We show evidence that, given the appropriate task, modest injection with relevant, high-quality knowledge is most performant.
Fusion of Sentiment and Asset Price Predictions for Portfolio Optimization
Mar 10, 2022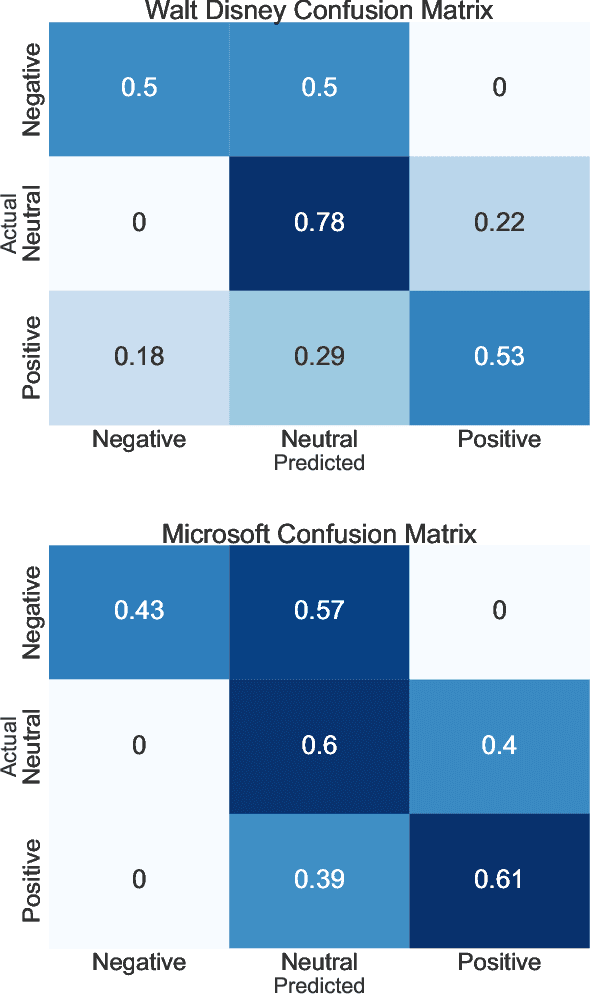
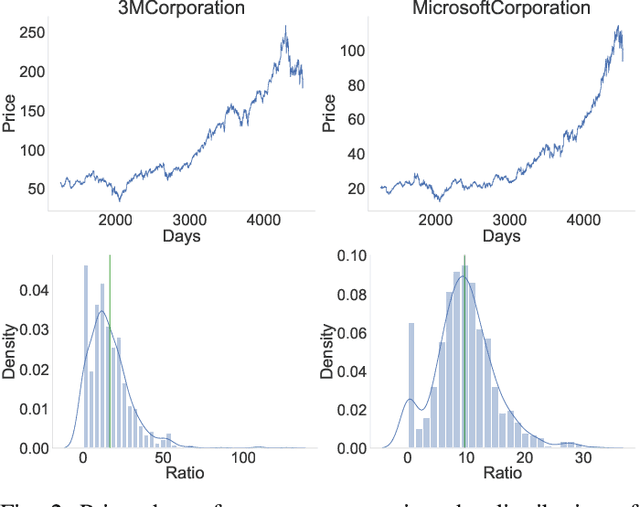
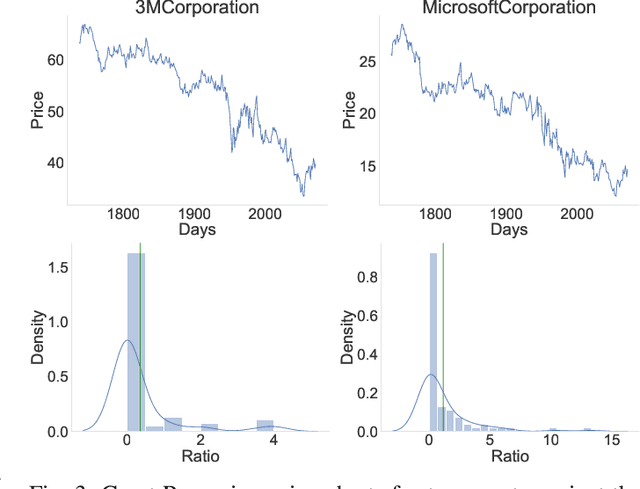
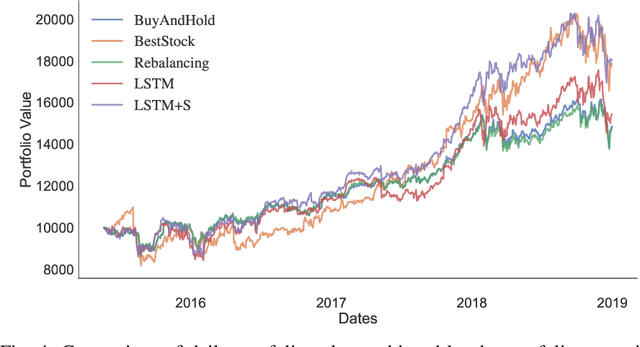
The fusion of public sentiment data in the form of text with stock price prediction is a topic of increasing interest within the financial community. However, the research literature seldom explores the application of investor sentiment in the Portfolio Selection problem. This paper aims to unpack and develop an enhanced understanding of the sentiment aware portfolio selection problem. To this end, the study uses a Semantic Attention Model to predict sentiment towards an asset. We select the optimal portfolio through a sentiment-aware Long Short Term Memory (LSTM) recurrent neural network for price prediction and a mean-variance strategy. Our sentiment portfolio strategies achieved on average a significant increase in revenue above the non-sentiment aware models. However, the results show that our strategy does not outperform traditional portfolio allocation strategies from a stability perspective. We argue that an improved fusion of sentiment prediction with a combination of price prediction and portfolio optimization leads to an enhanced portfolio selection strategy.