 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graph Fusion for Language Model Fine-tuning
Jun 21, 2022
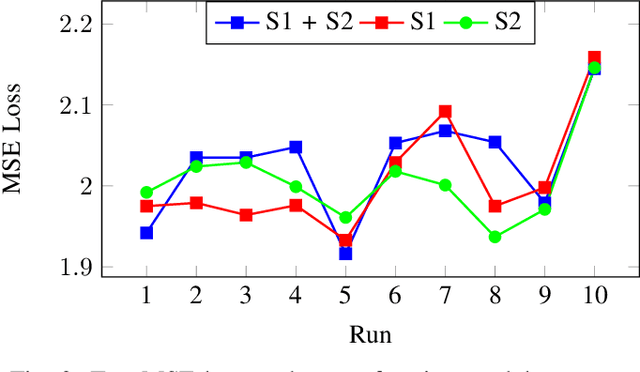
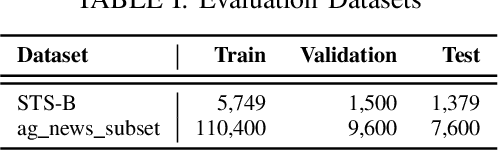
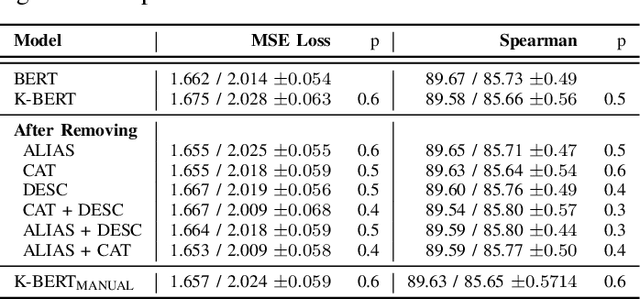
Language Models such as BERT have grown in popularity due to their ability to be pre-trained and perform robustly on a wide range of Natural Language Processing tasks. Often seen as an evolution over traditional word embedding techniques, they can produce semantic representations of text, useful for tasks such as semantic similarity. However, state-of-the-art models often have high computational requirements and lack global context or domain knowledge which is required for complete language understanding. To address these limitations, we investigate the benefits of knowledge incorporation into the fine-tuning stages of BERT. An existing K-BERT model, which enriches sentences with triplets from a Knowledge Graph, is adapted for the English language and extended to inject contextually relevant information into sentences. As a side-effect, changes made to K-BERT for accommodating the English language also extend to other word-based languages. Experiments conducted indicate that injected knowledge introduces noise. We see statistically significant improvements for knowledge-driven tasks when this noise is minimised. We show evidence that, given the appropriate task, modest injection with relevant, high-quality knowledge is most performant.