 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceptM$^3$oE: Concept-Guided Multimodal Mixture of Experts for Interpretable Computational Pathology
May 27, 2026Healthcare models are transitioning from unimodal prediction toward multimodal reasoning over heterogeneous diagnostic inputs. In computational pathology, for complex tumor subtypes where morphology alone can be challenging to distinguish, pathology reports and molecular measurements may provide additional diagnostic evidence alongside whole-slide images, yet existing models often fail to clarify how diverse signals assemble into recognizable diagnostic concepts. We propose ConceptM$^3$oE (Concept Multimodal MoE), which embeds concept formation directly within interaction-aware mixture-of-experts (MoE) pathways. The architecture decomposes evidence into modality-specific, redundant, and synergistic experts, which are then projected into structured concept bottlenecks mapping latent features to a hierarchy of morphology and biomarker concepts. To prevent the information loss typical of interpretable bottlenecks, we utilize residual pathways within each expert to allow task-relevant signals to flow both through the concepts and directly to the final task prediction, so that high performance is maintained alongside interpretability. Across an institutional pediatric brain tumor cohort and a public glioma cohort, the framework delivers competitive performance to unconstrained models while producing reasoning traces validated by an independent neuropathologist. In data-limited regimes, ConceptM$^3$oE improves limited-data performance, increasing macro-F1 from 56.41% to 66.70% at small training sizes compared to non-concept-informed baselines, while also showing faster training convergence consistent with the regularizing effect of concept learning. This work offers a scalable path toward high-performance medical AI that is inherently verifiable and better aligned with the complex decision-making of clinical practice.
Clinically-Informed Modeling for Pediatric Brain Tumor Classification from Whole-Slide Histopathology Images
Apr 22, 2026Accurate diagnosis of pediatric brain tumors, starting with histopathology, presents unique challenges for deep learning, including severe data scarcity, class imbalance, and fine-grained morphologic overlap across diagnostically distinct subtypes. While pathology foundation models have advanced patch-level representation learning, their effective adaptation to weakly supervised pediatric brain tumor classification under limited data remains underexplored. In this work, we introduce an expert-guided contrastive fine-tuning framework for pediatric brain tumor diagnosis from whole-slide images (WSI). Our approach integrates contrastive learning into slide-level multiple instance learning (MIL) to explicitly regularize the geometry of slide-level representations during downstream fine-tuning. We propose both a general supervised contrastive setting and an expert-guided variant that incorporates clinically informed hard negatives targeting diagnostically confusable subtypes. Through comprehensive experiments on pediatric brain tumor WSI classification under realistic low-sample and class-imbalanced conditions, we demonstrate that contrastive fine-tuning yields measurable improvements in fine-grained diagnostic distinctions. Our experimental analyses reveal complementary strengths across different contrastive strategies, with expert-guided hard negatives promoting more compact intra-class representations and improved inter-class separation. This work highlights the importance of explicitly shaping slide-level representations for robust fine-grained classification in data-scarce pediatric pathology settings.
PathMoE: Interpretable Multimodal Interaction Experts for Pediatric Brain Tumor Classification
Mar 02, 2026Accurate classification of pediatric central nervous system tumors remains challenging due to histological complexity and limited training data. While pathology foundation models have advanced whole-slide image (WSI) analysis, they often fail to leverage the rich, complementary information found in clinical text and tissue microarchitecture. To this end, we propose PathMoE, an interpretable multimodal framework that integrates H\&E slides, pathology reports, and nuclei-level cell graphs via an interaction-aware mixture-of-experts architecture built on state-of-the-art foundation models for each modality. By training specialized experts to capture modality uniqueness, redundancy, and synergy, PathMoE employs an input-dependent gating mechanism that dynamically weights these interactions, providing sample-level interpretability. We evaluate our framework on two dataset-specific classification tasks on an internal pediatric brain tumor dataset (PBT) and external TCGA datasets. PathMoE improves macro-F1 from 0.762 to 0.799 (+0.037) on PBT when integrating WSI, text, and graph modalities; on TCGA, augmenting WSI with graph knowledge improves macro-F1 from 0.668 to 0.709 (+0.041). These results demonstrate significant performance gains over state-of-the-art image-only baselines while revealing the specific modality interactions driving individual predictions. This interpretability is particularly critical for rare tumor subtypes, where transparent model reasoning is essential for clinical trust and diagnostic validation.
CLARiTy: A Vision Transformer for Multi-Label Classification and Weakly-Supervised Localization of Chest X-ray Pathologies
Dec 18, 2025The interpretation of chest X-rays (CXRs) poses significant challenges, particularly in achieving accurate multi-label pathology classification and spatial localization. These tasks demand different levels of annotation granularity but are frequently constrained by the scarcity of region-level (dense) annotations. We introduce CLARiTy (Class Localizing and Attention Refining Image Transformer), a vision transformer-based model for joint multi-label classification and weakly-supervised localization of thoracic pathologies. CLARiTy employs multiple class-specific tokens to generate discriminative attention maps, and a SegmentCAM module for foreground segmentation and background suppression using explicit anatomical priors. Trained on image-level labels from the NIH ChestX-ray14 dataset, it leverages distillation from a ConvNeXtV2 teacher for efficiency. Evaluated on the official NIH split, the CLARiTy-S-16-512 (a configuration of CLARiTy), achieves competitive classification performance across 14 pathologies, and state-of-the-art weakly-supervised localization performance on 8 pathologies, outperforming prior methods by 50.7%. In particular, pronounced gains occur for small pathologies like nodules and masses. The lower-resolution variant of CLARiTy, CLARiTy-S-16-224, offers high efficiency while decisively surpassing baselines, thereby having the potential for use in low-resource settings. An ablation study confirms contributions of SegmentCAM, DINO pretraining, orthogonal class token loss, and attention pooling. CLARiTy advances beyond CNN-ViT hybrids by harnessing ViT self-attention for global context and class-specific localization, refined through convolutional background suppression for precise, noise-reduced heatmaps.
BiCoRec: Bias-Mitigated Context-Aware Sequential Recommendation Model
Dec 15, 2025Sequential recommendation models aim to learn from users evolving preferences. However, current state-of-the-art models suffer from an inherent popularity bias. This study developed a novel framework, BiCoRec, that adaptively accommodates users changing preferences for popular and niche items. Our approach leverages a co-attention mechanism to obtain a popularity-weighted user sequence representation, facilitating more accurate predictions. We then present a new training scheme that learns from future preferences using a consistency loss function. BiCoRec aimed to improve the recommendation performance of users who preferred niche items. For these users, BiCoRec achieves a 26.00% average improvement in NDCG@10 over state-of-the-art baselines. When ranking the relevant item against the entire collection, BiCoRec achieves NDCG@10 scores of 0.0102, 0.0047, 0.0021, and 0.0005 for the Movies, Fashion, Games and Music datasets.
BrainNormalizer: Anatomy-Informed Pseudo-Healthy Brain Reconstruction from Tumor MRI via Edge-Guided ControlNet
Nov 17, 2025Brain tumors are among the most clinically significant neurological diseases and remain a major cause of morbidity and mortality due to their aggressive growth and structural heterogeneity. As tumors expand, they induce substantial anatomical deformation that disrupts both local tissue organization and global brain architecture, complicating diagnosis, treatment planning, and surgical navigation. Yet a subject-specific reference of how the brain would appear without tumor-induced changes is fundamentally unobtainable in clinical practice. We present BrainNormalizer, an anatomy-informed diffusion framework that reconstructs pseudo-healthy MRIs directly from tumorous scans by conditioning the generative process on boundary cues extracted from the subject's own anatomy. This boundary-guided conditioning enables anatomically plausible pseudo-healthy reconstruction without requiring paired non-tumorous and tumorous scans. BrainNormalizer employs a two-stage training strategy. The pretrained diffusion model is first adapted through inpainting-based fine-tuning on tumorous and non-tumorous scans. Next, an edge-map-guided ControlNet branch is trained to inject fine-grained anatomical contours into the frozen decoder while preserving learned priors. During inference, a deliberate misalignment strategy pairs tumorous inputs with non-tumorous prompts and mirrored contralateral edge maps, leveraging hemispheric correspondence to guide reconstruction. On the BraTS2020 dataset, BrainNormalizer achieves strong quantitative performance and qualitatively produces anatomically plausible reconstructions in tumor-affected regions while retaining overall structural coherence. BrainNormalizer provides clinically reliable anatomical references for treatment planning and supports new research directions in counterfactual modeling and tumor-induced deformation analysis.
A Holistic Weakly Supervised Approach for Liver Tumor Segmentation with Clinical Knowledge-Informed Label Smoothing
Oct 13, 2024



Liver cancer is a leading cause of mortality worldwide, and accurate CT-based tumor segmentation is essential for diagnosis and treatment. Manual delineation is time-intensive, prone to variability, and highlights the need for reliable automation. While deep learning has shown promise for automated liver segmentation, precise liver tumor segmentation remains challenging due to the heterogeneous nature of tumors, imprecise tumor margins, and limited labeled data. We present a novel holistic weakly supervised framework that integrates clinical knowledge to address these challenges with (1) A knowledge-informed label smoothing technique that leverages clinical data to generate smooth labels, which regularizes model training reducing the risk of overfitting and enhancing model performance; (2) A global and local-view segmentation framework, breaking down the task into two simpler sub-tasks, allowing optimized preprocessing and training for each; and (3) Pre- and post-processing pipelines customized to the challenges of each subtask, which enhances tumor visibility and refines tumor boundaries. We evaluated the proposed method on the HCC-TACE-Seg dataset and showed that these three key components complementarily contribute to the improved performance. Lastly, we prototyped a tool for automated liver tumor segmentation and diagnosis summary generation called MedAssistLiver. The app and code are published at https://github.com/lingchm/medassist-liver-cancer.
Knowledge-Informed Machine Learning for Cancer Diagnosis and Prognosis: A review
Jan 12, 2024



Cancer remains one of the most challenging diseases to treat in the medical field. Machine learning has enabled in-depth analysis of rich multi-omics profiles and medical imaging for cancer diagnosis and prognosis. Despite these advancements, machine learning models face challenges stemming from limited labeled sample sizes, the intricate interplay of high-dimensionality data types, the inherent heterogeneity observed among patients and within tumors, and concerns about interpretability and consistency with existing biomedical knowledge. One approach to surmount these challenges is to integrate biomedical knowledge into data-driven models, which has proven potential to improve the accuracy, robustness, and interpretability of model results. Here, we review the state-of-the-art machine learning studies that adopted the fusion of biomedical knowledge and data, termed knowledge-informed machine learning, for cancer diagnosis and prognosis. Emphasizing the properties inherent in four primary data types including clinical, imaging, molecular, and treatment data, we highlight modeling considerations relevant to these contexts. We provide an overview of diverse forms of knowledge representation and current strategies of knowledge integration into machine learning pipelines with concrete examples. We conclude the review article by discussing future directions to advance cancer research through knowledge-informed machine learning.
Quantifying intra-tumoral genetic heterogeneity of glioblastoma toward precision medicine using MRI and a data-inclusive machine learning algorithm
Dec 30, 2023
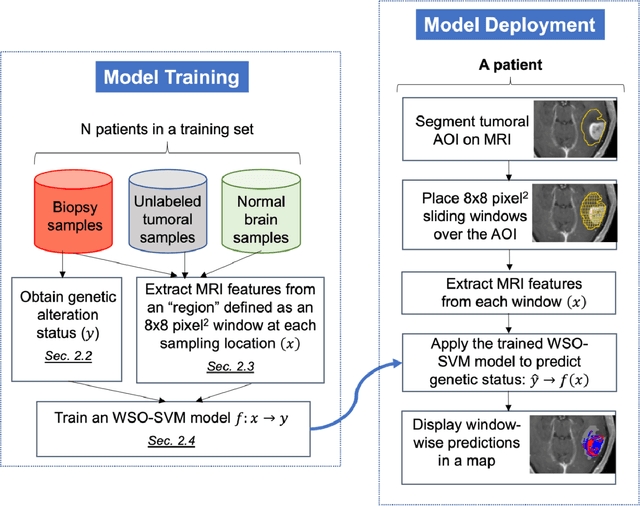


Glioblastoma (GBM) is one of the most aggressive and lethal human cancers. Intra-tumoral genetic heterogeneity poses a significant challenge for treatment. Biopsy is invasive, which motivates the development of non-invasive, MRI-based machine learning (ML) models to quantify intra-tumoral genetic heterogeneity for each patient. This capability holds great promise for enabling better therapeutic selection to improve patient outcomes. We proposed a novel Weakly Supervised Ordinal Support Vector Machine (WSO-SVM) to predict regional genetic alteration status within each GBM tumor using MRI. WSO-SVM was applied to a unique dataset of 318 image-localized biopsies with spatially matched multiparametric MRI from 74 GBM patients. The model was trained to predict the regional genetic alteration of three GBM driver genes (EGFR, PDGFRA, and PTEN) based on features extracted from the corresponding region of five MRI contrast images. For comparison, a variety of existing ML algorithms were also applied. The classification accuracy of each gene was compared between the different algorithms. The SHapley Additive exPlanations (SHAP) method was further applied to compute contribution scores of different contrast images. Finally, the trained WSO-SVM was used to generate prediction maps within the tumoral area of each patient to help visualize the intra-tumoral genetic heterogeneity. This study demonstrated the feasibility of using MRI and WSO-SVM to enable non-invasive prediction of intra-tumoral regional genetic alteration for each GBM patient, which can inform future adaptive therapies for individualized oncology.
A Novel Hybrid Ordinal Learning Model with Health Care Application
Dec 15, 2023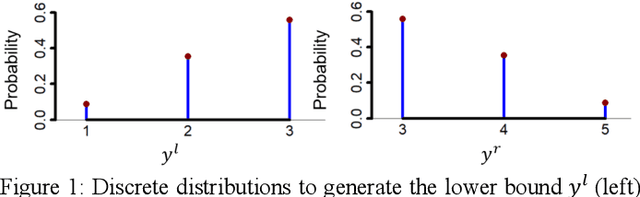
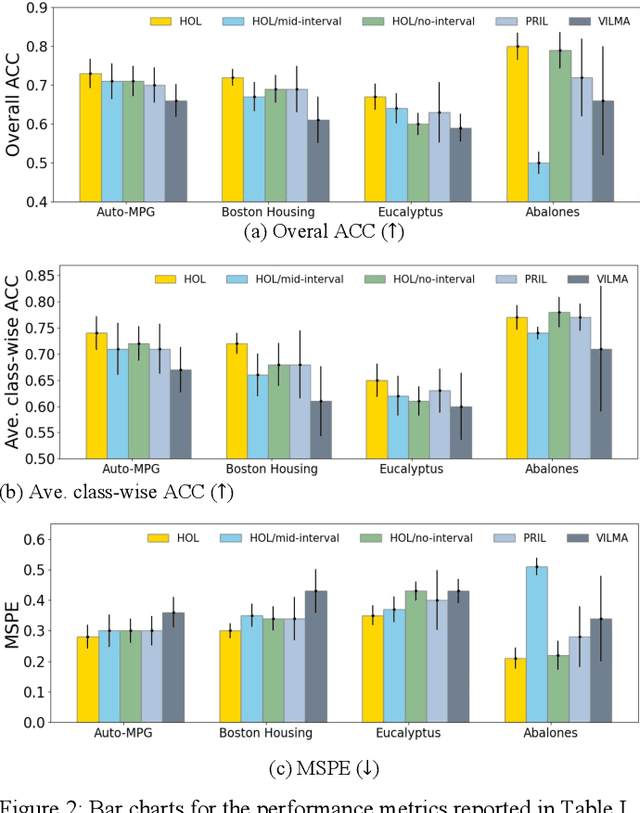
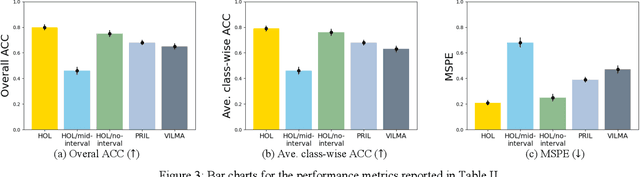
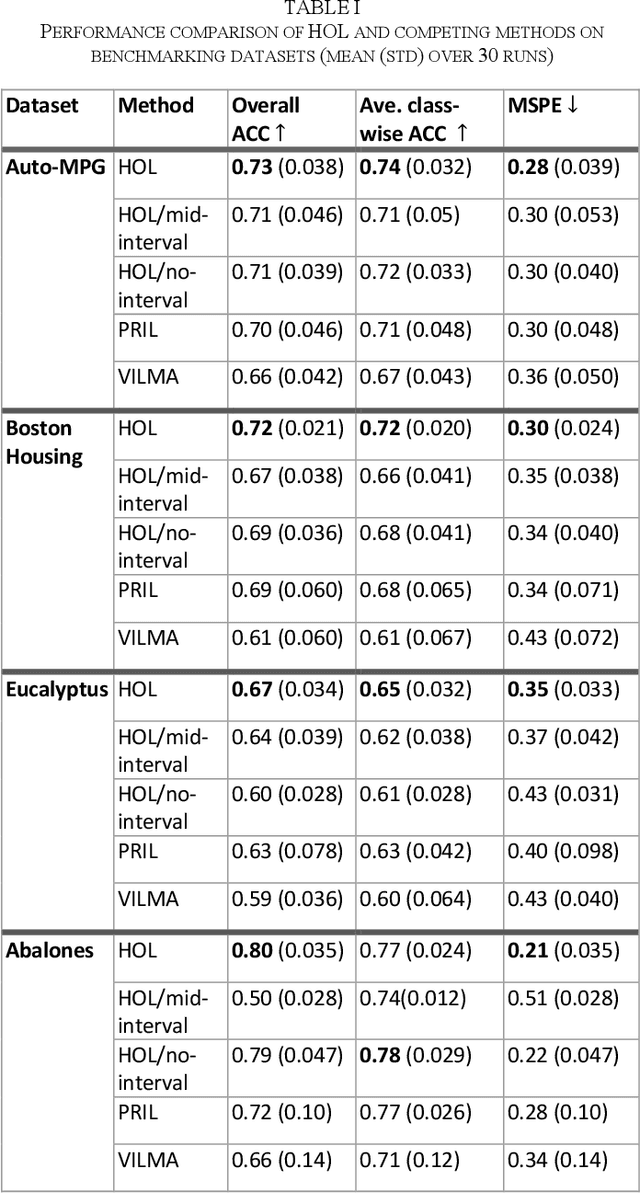
Ordinal learning (OL) is a type of machine learning models with broad utility in health care applications such as diagnosis of different grades of a disease (e.g., mild, modest, severe) and prediction of the speed of disease progression (e.g., very fast, fast, moderate, slow). This paper aims to tackle a situation when precisely labeled samples are limited in the training set due to cost or availability constraints, whereas there could be an abundance of samples with imprecise labels. We focus on imprecise labels that are intervals, i.e., one can know that a sample belongs to an interval of labels but cannot know which unique label it has. This situation is quite common in health care datasets due to limitations of the diagnostic instrument, sparse clinical visits, or/and patient dropout. Limited research has been done to develop OL models with imprecise/interval labels. We propose a new Hybrid Ordinal Learner (HOL) to integrate samples with both precise and interval labels to train a robust OL model. We also develop a tractable and efficient optimization algorithm to solve the HOL formulation. We compare HOL with several recently developed OL methods on four benchmarking datasets, which demonstrate the superior performance of HOL. Finally, we apply HOL to a real-world dataset for predicting the speed of progressing to Alzheimer's Disease (AD) for individuals with Mild Cognitive Impairment (MCI) based on a combination of multi-modality neuroimaging and demographic/clinical datasets. HOL achieves high accuracy in the prediction and outperforms existing methods. The capability of accurately predicting the speed of progression to AD for each individual with MCI has the potential for helping facilitate more individually-optimized interventional strategies.