 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedMoE: Modality-Specialized Mixture of Experts for Medical Vision-Language Understanding
Jun 11, 2025Different medical imaging modalities capture diagnostic information at varying spatial resolutions, from coarse global patterns to fine-grained localized structures. However, most existing vision-language frameworks in the medical domain apply a uniform strategy for local feature extraction, overlooking the modality-specific demands. In this work, we present MedMoE, a modular and extensible vision-language processing framework that dynamically adapts visual representation based on the diagnostic context. MedMoE incorporates a Mixture-of-Experts (MoE) module conditioned on the report type, which routes multi-scale image features through specialized expert branches trained to capture modality-specific visual semantics. These experts operate over feature pyramids derived from a Swin Transformer backbone, enabling spatially adaptive attention to clinically relevant regions. This framework produces localized visual representations aligned with textual descriptions, without requiring modality-specific supervision at inference. Empirical results on diverse medical benchmarks demonstrate that MedMoE improves alignment and retrieval performance across imaging modalities, underscoring the value of modality-specialized visual representations in clinical vision-language systems.
A Holistic Weakly Supervised Approach for Liver Tumor Segmentation with Clinical Knowledge-Informed Label Smoothing
Oct 13, 2024



Liver cancer is a leading cause of mortality worldwide, and accurate CT-based tumor segmentation is essential for diagnosis and treatment. Manual delineation is time-intensive, prone to variability, and highlights the need for reliable automation. While deep learning has shown promise for automated liver segmentation, precise liver tumor segmentation remains challenging due to the heterogeneous nature of tumors, imprecise tumor margins, and limited labeled data. We present a novel holistic weakly supervised framework that integrates clinical knowledge to address these challenges with (1) A knowledge-informed label smoothing technique that leverages clinical data to generate smooth labels, which regularizes model training reducing the risk of overfitting and enhancing model performance; (2) A global and local-view segmentation framework, breaking down the task into two simpler sub-tasks, allowing optimized preprocessing and training for each; and (3) Pre- and post-processing pipelines customized to the challenges of each subtask, which enhances tumor visibility and refines tumor boundaries. We evaluated the proposed method on the HCC-TACE-Seg dataset and showed that these three key components complementarily contribute to the improved performance. Lastly, we prototyped a tool for automated liver tumor segmentation and diagnosis summary generation called MedAssistLiver. The app and code are published at https://github.com/lingchm/medassist-liver-cancer.
Supervised Multi-Modal Fission Learning
Sep 30, 2024

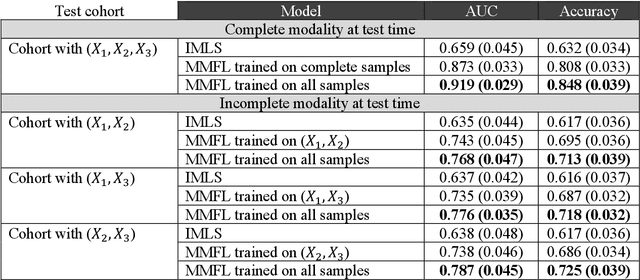

Learning from multimodal datasets can leverage complementary information and improve performance in prediction tasks. A commonly used strategy to account for feature correlations in high-dimensional datasets is the latent variable approach. Several latent variable methods have been proposed for multimodal datasets. However, these methods either focus on extracting the shared component across all modalities or on extracting both a shared component and individual components specific to each modality. To address this gap, we propose a Multi-Modal Fission Learning (MMFL) model that simultaneously identifies globally joint, partially joint, and individual components underlying the features of multimodal datasets. Unlike existing latent variable methods, MMFL uses supervision from the response variable to identify predictive latent components and has a natural extension for incorporating incomplete multimodal data. Through simulation studies, we demonstrate that MMFL outperforms various existing multimodal algorithms in both complete and incomplete modality settings. We applied MMFL to a real-world case study for early prediction of Alzheimers Disease using multimodal neuroimaging and genomics data from the Alzheimers Disease Neuroimaging Initiative (ADNI) dataset. MMFL provided more accurate predictions and better insights into within- and across-modality correlations compared to existing methods.
Knowledge-Informed Machine Learning for Cancer Diagnosis and Prognosis: A review
Jan 12, 2024



Cancer remains one of the most challenging diseases to treat in the medical field. Machine learning has enabled in-depth analysis of rich multi-omics profiles and medical imaging for cancer diagnosis and prognosis. Despite these advancements, machine learning models face challenges stemming from limited labeled sample sizes, the intricate interplay of high-dimensionality data types, the inherent heterogeneity observed among patients and within tumors, and concerns about interpretability and consistency with existing biomedical knowledge. One approach to surmount these challenges is to integrate biomedical knowledge into data-driven models, which has proven potential to improve the accuracy, robustness, and interpretability of model results. Here, we review the state-of-the-art machine learning studies that adopted the fusion of biomedical knowledge and data, termed knowledge-informed machine learning, for cancer diagnosis and prognosis. Emphasizing the properties inherent in four primary data types including clinical, imaging, molecular, and treatment data, we highlight modeling considerations relevant to these contexts. We provide an overview of diverse forms of knowledge representation and current strategies of knowledge integration into machine learning pipelines with concrete examples. We conclude the review article by discussing future directions to advance cancer research through knowledge-informed machine learning.