 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Multi-Modal Fission Learning
Sep 30, 2024

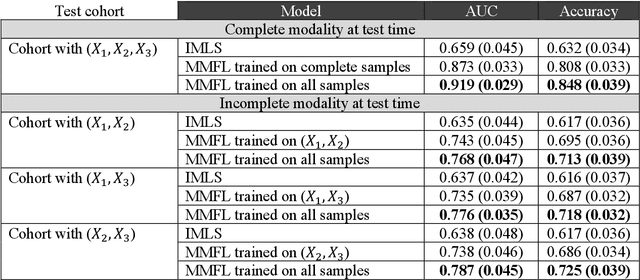

Learning from multimodal datasets can leverage complementary information and improve performance in prediction tasks. A commonly used strategy to account for feature correlations in high-dimensional datasets is the latent variable approach. Several latent variable methods have been proposed for multimodal datasets. However, these methods either focus on extracting the shared component across all modalities or on extracting both a shared component and individual components specific to each modality. To address this gap, we propose a Multi-Modal Fission Learning (MMFL) model that simultaneously identifies globally joint, partially joint, and individual components underlying the features of multimodal datasets. Unlike existing latent variable methods, MMFL uses supervision from the response variable to identify predictive latent components and has a natural extension for incorporating incomplete multimodal data. Through simulation studies, we demonstrate that MMFL outperforms various existing multimodal algorithms in both complete and incomplete modality settings. We applied MMFL to a real-world case study for early prediction of Alzheimers Disease using multimodal neuroimaging and genomics data from the Alzheimers Disease Neuroimaging Initiative (ADNI) dataset. MMFL provided more accurate predictions and better insights into within- and across-modality correlations compared to existing methods.
LDC-Net: A Unified Framework for Localization, Detection and Counting in Dense Crowds
Oct 10, 2021
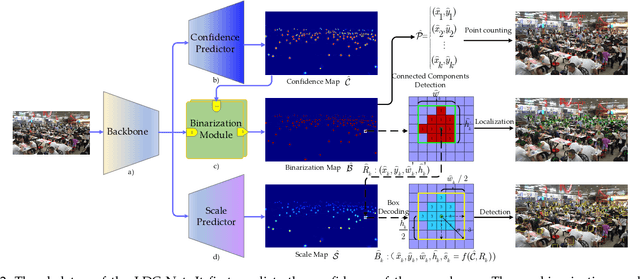

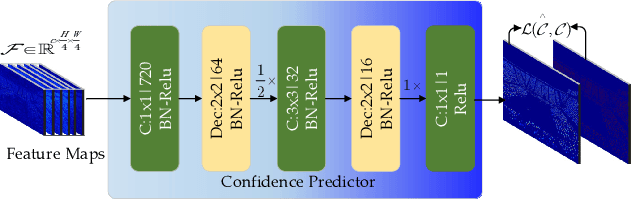
The rapid development in visual crowd analysis shows a trend to count people by positioning or even detecting, rather than simply summing a density map. It also enlightens us back to the essence of the field, detection to count, which can give more abundant crowd information and has more practical applications. However, some recent work on crowd localization and detection has two limitations: 1) The typical detection methods can not handle the dense crowds and a large variation in scale; 2) The density map heuristic methods suffer from performance deficiency in position and box prediction, especially in high density or large-size crowds. In this paper, we devise a tailored baseline for dense crowds location, detection, and counting from a new perspective, named as LDC-Net for convenience, which has the following features: 1) A strong but minimalist paradigm to detect objects by only predicting a location map and a size map, which endows an ability to detect in a scene with any capacity ($0 \sim 10,000+$ persons); 2) Excellent cross-scale ability in facing a large variation, such as the head ranging in $0 \sim 100,000+$ pixels; 3) Achieve superior performance in location and box prediction tasks, as well as a competitive counting performance compared with the density-based methods. Finally, the source code and pre-trained models will be released.