 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarth-o1: A Grid-free Observation-native Atmospheric World Model
May 07, 2026Despite the unprecedented volume of multimodal data provided by modern Earth observation systems, our ability to model atmospheric dynamics remains constrained. Traditional modeling frameworks force heterogeneous measurements into predefined spatial grids, inherently limiting the full exploitation of raw sensor data and creating severe computational bottlenecks. Here we present Earth-o1, an observation-native atmospheric world model that overcomes these structural limitations. Rather than relying on conventional atmospheric dynamical modeling systems or traditional data assimilation, Earth-o1 directly learns the continuous, three-dimensional physical evolution of the Earth system from ungridded observational data. By integrating diverse sensor inputs into a unified, grid-free dynamical field, the model autonomously advances the atmospheric state in space and time. We show that this fundamentally distinct paradigm enables direct, real-time forecasting and cross-sensor inference without the overhead of explicit numerical solvers. In hindcast evaluations, Earth-o1 achieves surface forecast skill comparable to the operational Integrated Forecasting System (IFS). These results establish that continuous, observation-driven world models -- a new class of fully observation-native geophysical simulators -- can match the fidelity of established physical frameworks, providing a scalable data-driven foundation for a digital twin of the Earth.
What You Think is What You See: Driving Exploration in VLM Agents via Visual-Linguistic Curiosity
May 05, 2026To navigate partially observable visual environments, recent VLM agents increasingly internalize world modeling capabilities into their policies via explicit CoT reasoning, enabling them to mentally simulate futures before acting. However, relying solely on passive reasoning over visited states is insufficient for sparse-reward tasks, as it lacks the epistemic drive to actively uncover the ``known unknown'' required for robust generalization. We ask: Can VLM agents actively find signals that challenge and refine their internal world model through curiosity-driven exploration? In this work, we propose GLANCE, a unified framework that bridges reasoning and exploration by grounding the agent's linguistic world model into the stable visual representations of an evolving target network. Crucially, GLANCE leverages the discrepancy between linguistic prediction and visual reality as an intrinsic curiosity signal within reinforcement learning, steering the agent to actively explore areas where its internal model is uncertain. Extensive experiments across a series of agentic tasks show the effectiveness of GLANCE, and demonstrate that aligning ``what the agent thinks'' with ``what the agent sees'' is key to solving complex or sparse agentic tasks.
UNICBench: UNIfied Counting Benchmark for MLLM
Feb 28, 2026Counting is a core capability for multimodal large language models (MLLMs), yet there is no unified counting dataset to rigorously evaluate this ability across image, text, and audio. We present UNICBench, a unified multimodal, multi level counting benchmark and evaluation toolkit with accurate ground truth, deterministic numeric parsing, and stratified reporting. The corpus comprises 5,300 images (5,508 QA), 872 documents (5,888 QA), and 2,069 audio clips (2,905 QA), annotated with a three level capability taxonomy and difficulty tags. Under a standardized protocol with fixed splits/prompts/seeds and modality specific matching rules, we evaluate 45 state-of-the-art MLLMs across modalities. Results show strong performance on some basic counting tasks but significant gaps on reasoning and the hardest partitions, highlighting long-tail errors and substantial headroom for improving general counting. UNICBench offers a rigorous and comparable basis for measurement and a public toolkit to accelerate progress.
Parallel Continuous-Time Relative Localization with Augmented Clamped Non-Uniform B-Splines
Feb 25, 2026Accurate relative localization is critical for multi-robot cooperation. In robot swarms, measurements from different robots arrive asynchronously and with clock time-offsets. Although Continuous-Time (CT) formulations have proved effective for handling asynchronous measurements in single-robot SLAM and calibration, extending CT methods to multi-robot settings faces great challenges to achieve high-accuracy, low-latency, and high-frequency performance. Especially, existing CT methods suffer from the inherent query-time delay of unclamped B-splines and high computational cost. This paper proposes CT-RIO, a novel Continuous-Time Relative-Inertial Odometry framework. We employ Clamped Non-Uniform B-splines (C-NUBS) to represent robot states for the first time, eliminating the query-time delay. We further augment C-NUBS with closed-form extension and shrinkage operations that preserve the spline shape, making it suitable for online estimation and enabling flexible knot management. This flexibility leads to the concept of knot-keyknot strategy, which supports spline extension at high-frequency while retaining sparse keyknots for adaptive relative-motion modeling. We then formulate a sliding-window relative localization problem that operates purely on relative kinematics and inter-robot constraints. To meet the demanding computation required at swarm scale, we decompose the tightly-coupled optimization into robot-wise sub-problems and solve them in parallel using incremental asynchronous block coordinate descent. Extensive experiments show that CT-RIO converges from time-offsets as large as 263 ms to sub-millisecond within 3 s, and achieves RMSEs of 0.046 m and 1.8 °. It consistently outperforms state-of-the-art methods, with improvements of up to 60% under high-speed motion.
EMFormer: Efficient Multi-Scale Transformer for Accumulative Context Weather Forecasting
Feb 01, 2026Long-term weather forecasting is critical for socioeconomic planning and disaster preparedness. While recent approaches employ finetuning to extend prediction horizons, they remain constrained by the issues of catastrophic forgetting, error accumulation, and high training overhead. To address these limitations, we present a novel pipeline across pretraining, finetuning and forecasting to enhance long-context modeling while reducing computational overhead. First, we introduce an Efficient Multi-scale Transformer (EMFormer) to extract multi-scale features through a single convolution in both training and inference. Based on the new architecture, we further employ an accumulative context finetuning to improve temporal consistency without degrading short-term accuracy. Additionally, we propose a composite loss that dynamically balances different terms via a sinusoidal weighting, thereby adaptively guiding the optimization trajectory throughout pretraining and finetuning. Experiments show that our approach achieves strong performance in weather forecasting and extreme event prediction, substantially improving long-term forecast accuracy. Moreover, EMFormer demonstrates strong generalization on vision benchmarks (ImageNet-1K and ADE20K) while delivering a 5.69x speedup over conventional multi-scale modules.
Video Individual Counting and Tracking from Moving Drones: A Benchmark and Methods
Jan 18, 2026Counting and tracking dense crowds in large-scale scenes is highly challenging, yet existing methods mainly rely on datasets captured by fixed cameras, which provide limited spatial coverage and are inadequate for large-scale dense crowd analysis. To address this limitation, we propose a flexible solution using moving drones to capture videos and perform video-level crowd counting and tracking of unique pedestrians across entire scenes. We introduce MovingDroneCrowd++, the largest video-level dataset for dense crowd counting and tracking captured by moving drones, covering diverse and complex conditions with varying flight altitudes, camera angles, and illumination. Existing methods fail to achieve satisfactory performance on this dataset. To this end, we propose GD3A (Global Density Map Decomposition via Descriptor Association), a density map-based video individual counting method that avoids explicit localization. GD3A establishes pixel-level correspondences between pedestrian descriptors across consecutive frames via optimal transport with an adaptive dustbin score, enabling the decomposition of global density maps into shared, inflow, and outflow components. Building on this framework, we further introduce DVTrack, which converts descriptor-level matching into instance-level associations through a descriptor voting mechanism for pedestrian tracking. Experimental results show that our methods significantly outperform existing approaches under dense crowds and complex motion, reducing counting error by 47.4 percent and improving tracking performance by 39.2 percent.
Predicting the Future by Retrieving the Past
Nov 08, 2025Deep learning models such as MLP, Transformer, and TCN have achieved remarkable success in univariate time series forecasting, typically relying on sliding window samples from historical data for training. However, while these models implicitly compress historical information into their parameters during training, they are unable to explicitly and dynamically access this global knowledge during inference, relying only on the local context within the lookback window. This results in an underutilization of rich patterns from the global history. To bridge this gap, we propose Predicting the Future by Retrieving the Past (PFRP), a novel approach that explicitly integrates global historical data to enhance forecasting accuracy. Specifically, we construct a Global Memory Bank (GMB) to effectively store and manage global historical patterns. A retrieval mechanism is then employed to extract similar patterns from the GMB, enabling the generation of global predictions. By adaptively combining these global predictions with the outputs of any local prediction model, PFRP produces more accurate and interpretable forecasts. Extensive experiments conducted on seven real-world datasets demonstrate that PFRP significantly enhances the average performance of advanced univariate forecasting models by 8.4\%. Codes can be found in https://github.com/ddz16/PFRP.
Mesh-RFT: Enhancing Mesh Generation via Fine-grained Reinforcement Fine-Tuning
May 22, 2025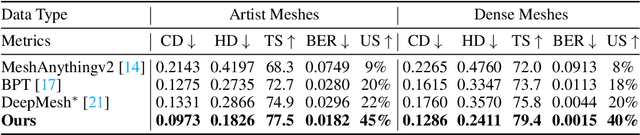
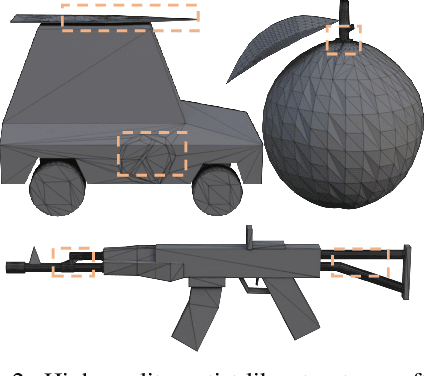
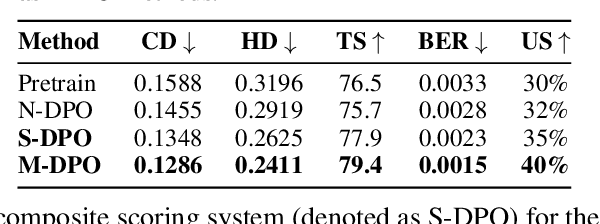
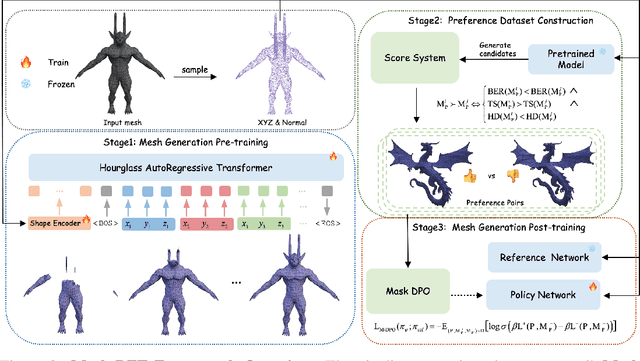
Existing pretrained models for 3D mesh generation often suffer from data biases and produce low-quality results, while global reinforcement learning (RL) methods rely on object-level rewards that struggle to capture local structure details. To address these challenges, we present \textbf{Mesh-RFT}, a novel fine-grained reinforcement fine-tuning framework that employs Masked Direct Preference Optimization (M-DPO) to enable localized refinement via quality-aware face masking. To facilitate efficient quality evaluation, we introduce an objective topology-aware scoring system to evaluate geometric integrity and topological regularity at both object and face levels through two metrics: Boundary Edge Ratio (BER) and Topology Score (TS). By integrating these metrics into a fine-grained RL strategy, Mesh-RFT becomes the first method to optimize mesh quality at the granularity of individual faces, resolving localized errors while preserving global coherence. Experiment results show that our M-DPO approach reduces Hausdorff Distance (HD) by 24.6\% and improves Topology Score (TS) by 3.8\% over pre-trained models, while outperforming global DPO methods with a 17.4\% HD reduction and 4.9\% TS gain. These results demonstrate Mesh-RFT's ability to improve geometric integrity and topological regularity, achieving new state-of-the-art performance in production-ready mesh generation. Project Page: \href{https://hitcslj.github.io/mesh-rft/}{this https URL}.
FreeMesh: Boosting Mesh Generation with Coordinates Merging
May 19, 2025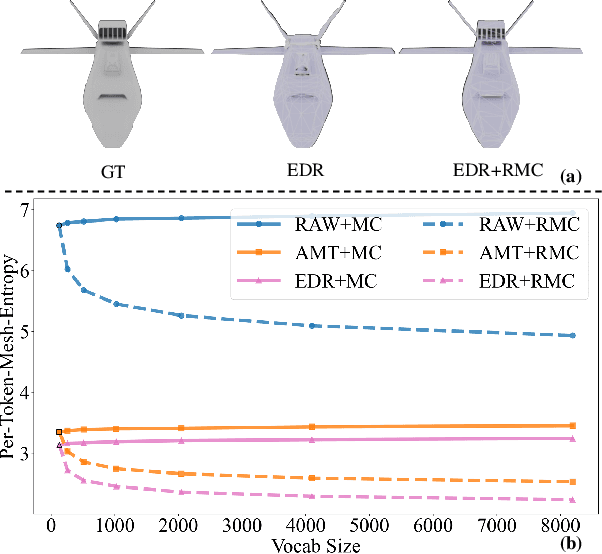
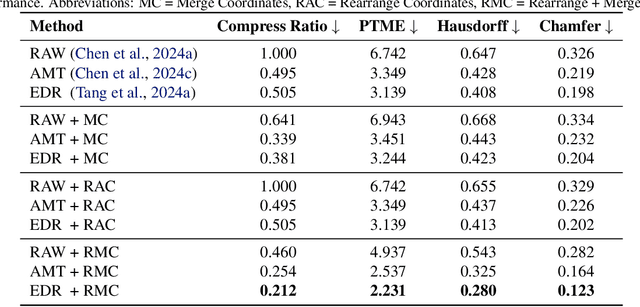
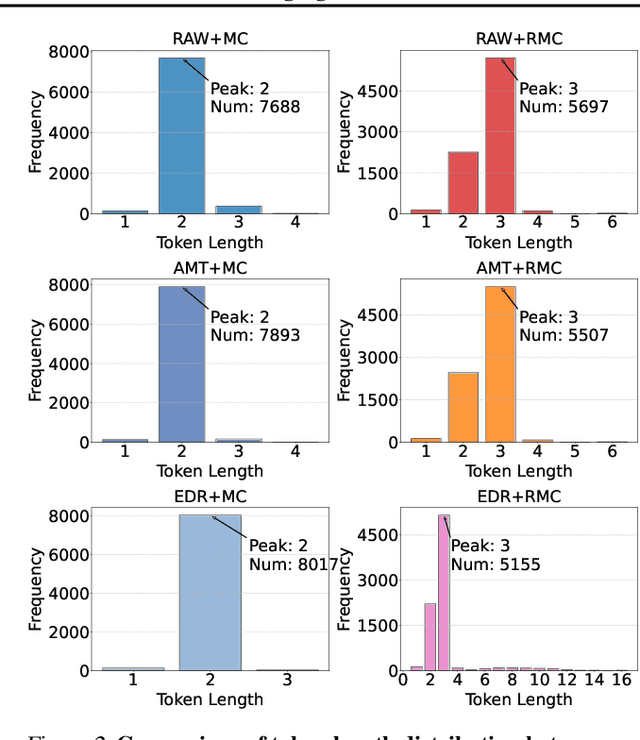
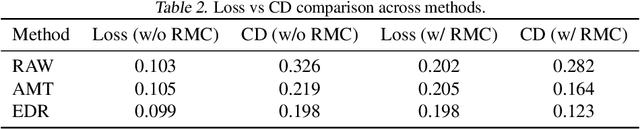
The next-coordinate prediction paradigm has emerged as the de facto standard in current auto-regressive mesh generation methods. Despite their effectiveness, there is no efficient measurement for the various tokenizers that serialize meshes into sequences. In this paper, we introduce a new metric Per-Token-Mesh-Entropy (PTME) to evaluate the existing mesh tokenizers theoretically without any training. Building upon PTME, we propose a plug-and-play tokenization technique called coordinate merging. It further improves the compression ratios of existing tokenizers by rearranging and merging the most frequent patterns of coordinates. Through experiments on various tokenization methods like MeshXL, MeshAnything V2, and Edgerunner, we further validate the performance of our method. We hope that the proposed PTME and coordinate merging can enhance the existing mesh tokenizers and guide the further development of native mesh generation.
Event-Based Eye Tracking. 2025 Event-based Vision Workshop
Apr 25, 2025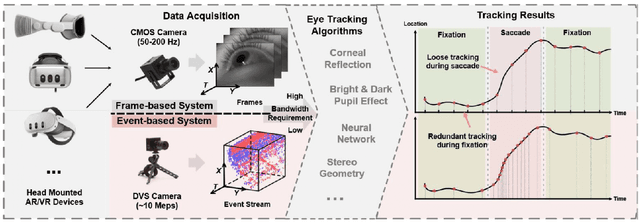
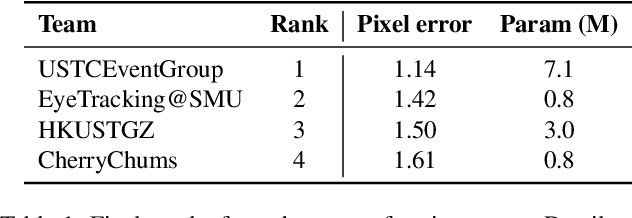
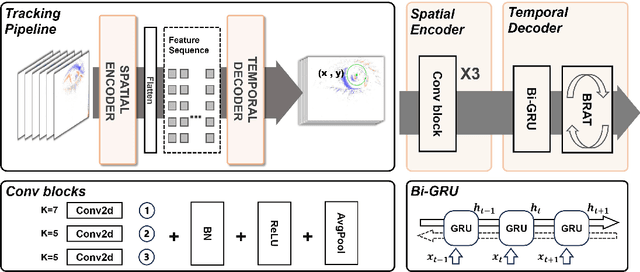

This survey serves as a review for the 2025 Event-Based Eye Tracking Challenge organized as part of the 2025 CVPR event-based vision workshop. This challenge focuses on the task of predicting the pupil center by processing event camera recorded eye movement. We review and summarize the innovative methods from teams rank the top in the challenge to advance future event-based eye tracking research. In each method, accuracy, model size, and number of operations are reported. In this survey, we also discuss event-based eye tracking from the perspective of hardware design.